华为云盘古大模型在各行业应用方面 , 已经在能源、零售、金融、工业、医疗、环境、物流等行业的 100 多个场景实际应用, 让企业的 AI 应用开发效率平均提升了 90% 。
另外 , 阿里达摩院研发的 M6 , 拥有多模态、多任务能力 , 其认知和创造能力超越传统 AI ,目前已应用在支付宝、淘宝、天猫业务上 , 尤其擅长设计、写作、问答 , 在电商、制造业、文学艺术、科学研究等领域有广泛应用前景 。
值得注意的是 , 目前大模型更多的是离线应用 , 在线应用上 , 还需要考虑知识蒸馏和低精度量化等模型压缩技术、项目实时性等一系列复杂的项目难题 。
大模型的分类 1、按照模型架构划分:单体模型和混合模型 。 单体模型中比较出名的有:其中 OpenAI 推出的「GPT-3」、微软-英伟达推出的「MT-NLG」模型、浪潮推出的「源1.0」等 。 混合模型包括谷歌的「Switch Transformer」、智源研究院的「悟道」、阿里的「M6」、华为云的「盘古」等 。
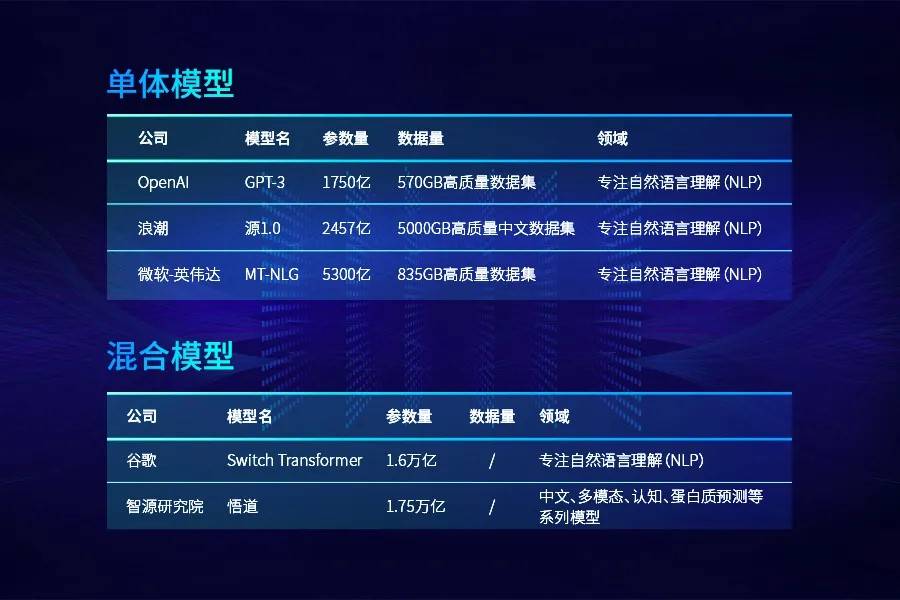
文章图片
其中 , 谷歌「Switch Transformer」采用 Mixture of Experts (MoE , 混合专家) 模式 , 将模型进行切分 , 其结果是得到的是一个稀疏激活模型 , 大大节省了计算资源 。
而智源「悟道2.0」1.75万亿参数再次刷新万亿参数规模的记录 , 值得关注的是它不再关注单一领域的模型开发 , 而是各种领域的融合系统 。
2、按照应用领域划分:目前 , 大模型的热门方向包括 NLP(中文语言)大模型、CV(视觉)大模型、多模态大模型和科学计算大模型等 。
目前 , 自然语言处理领域内热门单体大模型有:「GPT-3」、「MT-NLG」以及「源 1.0」等 。 惊喜的是 , 有研究表明 , 将 NLP 领域大获成功的自监督预训练模式同样也可以用在 CV 任务上 , 效果十分拔群 。
大模型的卡点 大模型性能取得的一系列突破的同时 , 其背后逐渐凸显的卡点也开始备受社会关注 。
首先 , 打造大模型并非易事 , 需要消耗庞大的数据、算力、算法等各种软硬件资源 。 而短期看 , 这种巨大的资源消耗 , 不仅对于企业和科研机构来说 , 无疑是一项沉重的负担 , 更与全球节能环保以及我国提出的双碳(碳达峰、碳中和)目标 , 是有所矛盾的 。 如何在有限资源的条件下实现大模型的低能耗进化 , 是一个不小的挑战 。
其次 , 大模型尚缺乏统一的评价标准和模块化流程 。 大模型的研发尚处于初步探索阶段 , 市场中有条件的企业和机构纷纷展开角逐的同时 , 不可避免地会造成高质量的集中资源的再度分化 , 进而产生各种烟囱式的评判标准、分散的算法模型结构 , 进而可能导致的割裂的探讨评价体系 。
再次 , 创新力度不足 。 大模型应用价值取决于其泛化能力 , 而不是参数规模越大越好 。 大模型是否优秀 , 不仅依赖数据的精度与网络结构 , 也是对其与行业结合软硬件协同能力的比拼 。 目前业界过度强调高参数集、强算力模型的研发 , 而忽视了网络模型的创新、与行业的协同创新等问题 。
最后 , 落地应用缓慢 。 业界人士普遍认为:AI 大模型最大挑战在于 , 如何让更多行业和场景真正付诸落地 。 目前看应用仍处于企业内部项目为主 。 如何改变这种闭门造车的局面 , 如何快速适配给应用场景 , 才是大模型的最大价值和难点 。
大模型何去何从 1、大模型参数红利仍在
从百万、千万、亿再到千亿 , 万亿 , 大模型随着参数规模的增加 , 性能也如研究者预期一样 , 一直在不断接近人类水平 。 可以预见 , 未来一段时间 , 大模型的规模依旧有待提升 。 可能出现的变化是 , 人们不再仅仅增加算力 , 而更多是通过并行计算、软硬件协同等技术的支撑 。 值得关注的是 , 由于实际落地方面的考虑 , 一些小参数模型也在悄然兴起 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。