文章图片
数据并不是万能的 。
2010年12月 , 谷歌与哈佛大学合作推出了科学实验项目“Google Ngram Viewer” , 中文翻译为“谷歌图书词频统计器” 。
简而言之 , 这个统计器是针对图书出版物的一种“谷歌趋势” 。 统计器提供关键词搜索 , 搜索的范围是谷歌的数字图书馆“谷歌图书” , 分析关键词在图书、报纸、期刊中出现的频率 , 并按照年份依次排开 , 最终基于用户给定的时间跨度 , 提供一条显示关键词流行及发展趋势的曲线 。
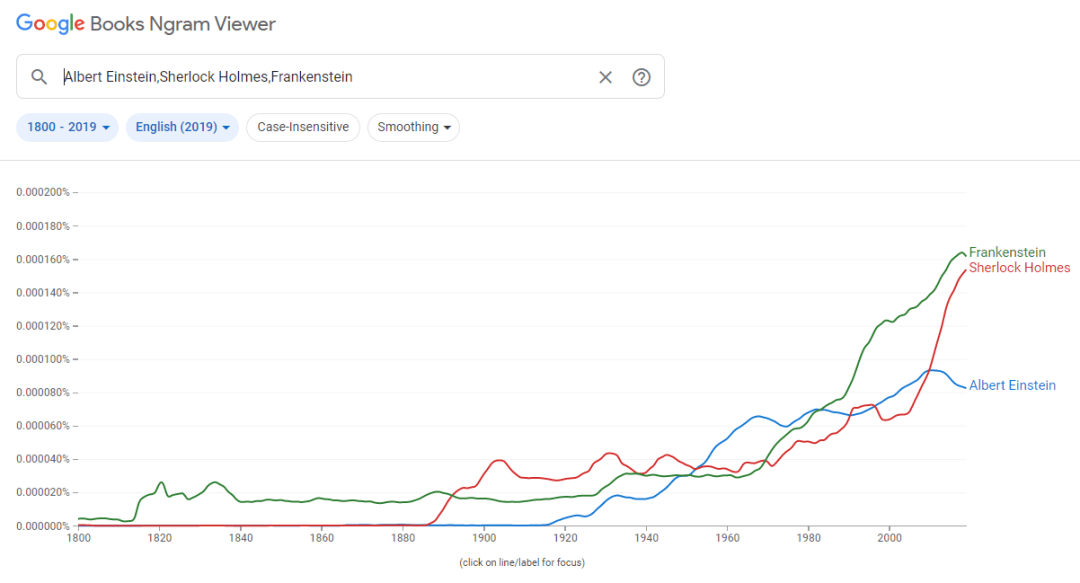
文章图片
横轴为年份 , 纵轴为词频
在语言学范畴上 , 谷歌给定的文本范围可以被称作一种“语料库” , 而谷歌语料库可能是迄今为止最大的人文及社会科学研究语料库 。
刚上线时 , 谷歌语料库中拥有超过500万本图书 , 占世界上所有已出版书籍的4% , 其中以英语书占多数 。 2020年7月 , 谷歌语料库更新至2019版本 , 收录从1500年到2020年2月的书籍文本 , 涵盖英文、简体中文、法文、德文等八种语言 , 图书数量已超过千万本 。
谷歌表示 , 词频统计器得出的数据允许免费下载并用于任何用途 , 因此这项工具受到欧美学术界的热烈欢迎与频繁引用 。
然而 , 更多的人把统计器用在了不那么学术的用途上 。 在以造梗与玩梗著称的互联网民中 , 流传着这么一种玩法:用词频统计器搜索一些21世纪才出现的流行语及特有名词 , 等待统计器提供一条令人细思恐极的曲线 。
例如像下面的视频那样 , 在搜索框输入“Grand theft auto”——也就是GTA的全称 , 你就会发现GTA在1770年左右拥有比21世纪还要高的词频 。
也许 , 历史老师在讲授那段历史时 , 有意向你隐瞒了些什么 。
1
词频统计器的这种玩法 , 是由法国人率先发现并大加传播的 。 至少在第二次世界大战之前 , 法国一直是公认的欧洲乃至世界强权 , 而词频统计器对那段历史的学术研究贡献之大 , 也许唤醒了他们对光荣时刻的追忆 。
2020年7月27日 , 谷歌更新2019语料库没多久 , 法国网友PasEdward使用统计器的法语语料库 , 搜索了一个俚语单词:“Wesh” 。 这个词源自阿尔及利亚语 , 约在上世纪90年代传入法国 , 意思相近于英文中的“What’s up” , 中文里的“嘿”或“发生了什么” 。
结果显示 , 趋势曲线在1800年的位置上出现了一次波折 , 意味着“Wesh”在1800年的著作中有使用记录 。 虽然不明白原委 , PasEdward还是把自己的发现放到推特上分享 , 同时配上一张简陋的P图 , 为法国大革命时期的著名政治家罗伯斯庇尔戴上了一顶现代帽子 。

文章图片
第二天 , 另两位法国网友搜索了一些欧洲歌手的名字 , 并在18-19世纪这一区间内找到了对应的索引结果 。 他们随即把歌手的头像P到法国国王路易十四与路易十六的画像上 , 同样上传至推特 。

文章图片
推特@30SecondsDamso

特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。