另外一个与逐模块训练不同的点在于 , 在并行知识蒸馏训练的初期 , 下一个模块获得的输入是从上一个未经过充分训练的模块中获得 。 因此 , 未充分训练的模块的输出可能依旧含有较大的量化误差 , 并且该误差会逐层传播 , 影响后续模块训练 。
为了解决该问题 , 研究者受教师纠正(teacher forcing) 在训练循环网络中的启发 , 将第 n 个全精度模块的输出导入为第 (n+1) 个量化模块的输入 , 从而中断在后续模块的量化误差传播 。 然而 , 这种跨模块输入打破了与量化模型自身前继模块的联系 , 造成训练和推理前向不一致 。 为了实现平稳过渡 , 他们采用了如下的凸组合:
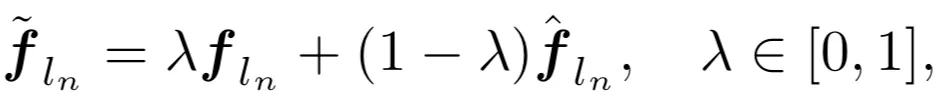
文章图片
并对连接系数
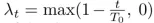
文章图片
随着迭代次数 t 进行线性缩减 。
实验验证
研究者首先在 MNLI 数据集上进行验证 。 由下表可以发现 , 对比逐层后量化训练(REM)算法 , 提出的逐模块量化误差重构 (MREM-S)大大提升了后量化的准确率;同时 , MREM-S 性能也可以接近量化感知训练(QAT)的方法 , 对于 BERT-base 和 BERT-large 在 W4A8 的设定下仅仅比 QAT 低了 1.1% 和 0.8% , 训练时间、显存开销和数据消耗也有了减小 。
当结合并行知识蒸馏时(MREM-P) , 后量化训练时间可以进一步缩短 4 倍 , 而且没有明显性能损失 。 例如 , MREM-P 仅耗时 6 分钟 , 占用 3.7GB 即可完成 BERT-base 上 2 比特权重的后量化训练 。
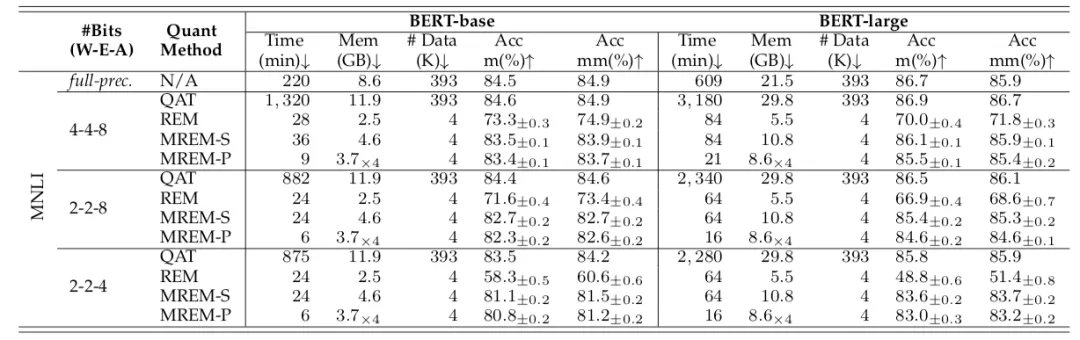
文章图片
在 MNLI 上与 QAT 和 REM 的对比 。
研究者同时在 GLUE 上与现有的其他算法进行了对比 。 如下表所示 , 本文的方法 (MREM-S 和 MREM-P) 比后量化方法 GOBO【4】取得更好的效果 , 甚至在多个任务上接近量化感知训练方法 TernaryBERT 。
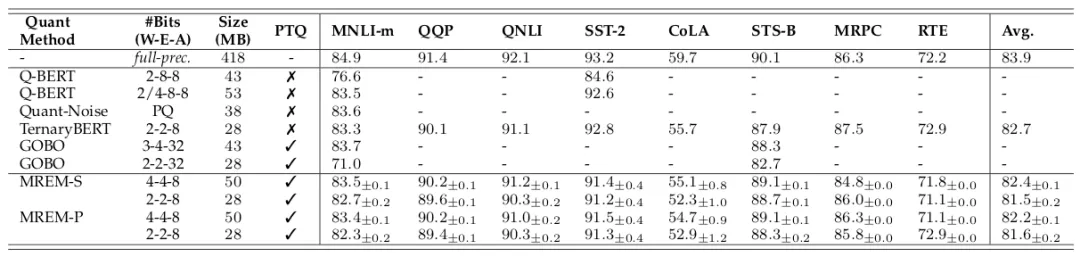
文章图片
在 GLUE 公开数据集上与现有方法对比 。
参考文献:
【1】Di Wu, Qi Tang, Yongle Zhao, Ming Zhang, Ying Fu, and Debing Zhang. Easyquant: Posttraining
quantization via scale optimization. arXiv preprint arXiv:2006.16669, 2020.
【2】Peisong Wang, Qiang Chen, Xiangyu He, and Jian Cheng. Towards accurate post-training
network quantization via bit-split and stitching. In International Conference on Machine
Learning, pages 9847–9856. PMLR, 2020.
【3】I. Hubara, Y. Nahshan, Y. Hanani, R. Banner, and D. Soudry, “Improving post training neural quantization: Layer-wise calibration and integer programming,” in Proceedings of the International Conference on Machine Learning, 2021.
【4】A. H. Zadeh, I. Edo, O. M. Awad, and A. Moshovos, “Gobo: Quantizing attention-based nlp models for low latency and energy efficient inference,” Preprint arXiv:2005.03842, 2020.
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。