GPU进入新三国鼎立时代( 二 )
前些天 , 在2021年财报电话会议上 , AMD确认 , 今年会有几项重要产品发布 , 包括基于RDNA 3架构的GPU , 也就是Radeon RX 7000 。 目前来看 , 该系列最新显卡会有三款GPU , 分别是Navi 31、Navi 32和Navi 33 , 其中 , Navi 31和Navi 32将采用MCM封装 。 之前有传闻称 , Navi 31和Navi 32的Infinity Cache将采用3D堆栈的设计 , 会单独添加到MCD小芯片中 , 与Zen 3架构上采用3D V-Cache的原理类似 , 性能会有较大提升 。
由于Navi 31和Navi 32采用了MCM封装 , AMD将会使用两种不同制程 , GPU会使用台积电的5nm工艺 , 缓存I/O芯片则会采用台积电的6nm工艺 。
英伟达也在跟进MCM封装GPU 。
2017年 , 英伟达展示了通过四个小芯片构建的设计方案 , 不但提升了性能 , 还有助于提高产量(较小的芯片良品率会提高) , 而且还允许将更多的计算资源集合在一起 。 这种多芯片设计还有助于提高供电效率 , 具有更好的散热效果 。
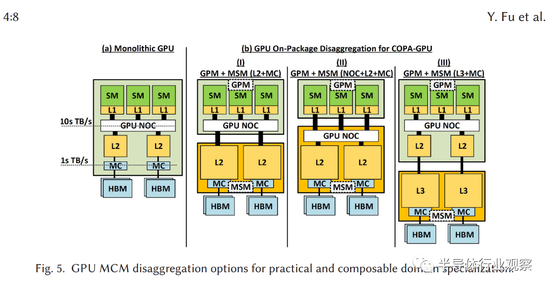
近日 , 英伟达研究人员发表了一篇技术文章 , 概述了该公司对MCM的探索 , 英伟达目前在MCM封装GPU上的做法称为“Composable On Package GPU”(COPA) , 该团队讲述了COPA GPU 的各项优势 , 尤其是能够适应各种类型的深度学习工作负载 。
由于传统融合 GPU 解决方案正迅速变得不太实用 , 研究人员才想到到 COPA-GPU 的理念 。 融合GPU解决方案依赖于由传统芯片组成的架构 , 辅以高带宽内存(HBM)、张量核心/矩阵核心(Matrix Cores)、光线追踪(RT)等专用硬件的结合 。
此类硬件或在某些任务下非常合适 , 但在面对其它情况时却效率低下 。 与当前将所有特定执行组件和缓存组合到一个包中的单片 GPU 设计不同 , COPA-GPU 架构具有混合 / 匹配多个硬件块的能力 。 如此一来 , 它就能够更好地适应当今高性能计算只能呈现的动态工作负载、以及深度学习(DL)环境 。
这种整合更适应多种类型工作负载的能力 , 可带来更高水平的 GPU 重用 。 更重要的是 , 对于数据科学家们来说 , 这使他们更有能力利用现有资源 , 来突破潜在的界限 。
文章图片
图2/3
面向数据中心和消费市场 , 英伟达将分别推出基于Hopper架构和Ada Lovelace架构的GPU 。 据悉 , 该公司只会在Hopper架构GPU上采用MCM技术 , Ada Lovelace架构GPU仍会保留传统的封装设计 , 并不会像AMD基于RDNA 3架构的Navi 31那样 , 将MCM多芯片封装引入到消费级GPU 。
近日 , 有消息称 , 基于Hopper架构的GH100的晶体管数量将达到1400亿 , 这几乎是目前基于Ampere架构的GA100(542亿)或AMD基于CDNA 2架构的Instinct MI200系列(580亿)的2.5倍 。 据称GH100的芯片尺寸接近900mm2 , 比此前传言的1000mm2要小 , 不过比GA100(862mm2)和Instinct MI200系列(约790mm2)要大一些 。 传闻GH100总共配置了288个SM , 可以提供三倍于A100计算卡的性能 。
据悉 , 作为英伟达第一款基于MCM技术的GPU , Hopper架构产品将采用台积电5nm制程工艺 , 支持HBM2e和其他连接特性 , 预计会在2022年中旬亮相 , 竞争对手将是英特尔的Xe-HP架构GPU和AMD的CDNA 2架构产品 。
不过 , 以上说法还未得到官方证实 , 英伟达将于今年3月21日召开GTC 2022大会 , 届时 , 可能会公布Hopper架构 , 以及相应的加速卡方案 。
作为独立GPU的后来者 , 英特尔最近也是动作频频 。
近期 , 英特尔公布新专利 , 描述多个计算模组如何协同工作执行图像渲染 , 代表英特尔GPU将采用MCM封装技术 , 大幅提高运作效能 。
英特尔针对数据中心和超级计算机Ponte Vecchio的CPU已使用多芯片设计 , 并采用MCM封装技术 。 在新专利中 , 英特尔提出GPU图像渲染解决方案 , 将多芯片整合至同单元 , 解决制造和功耗等问题 , 同时优化可扩展性和互联性 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。