处理器发展第一阶段:频率时代(1970-2000 年代)
文章图片
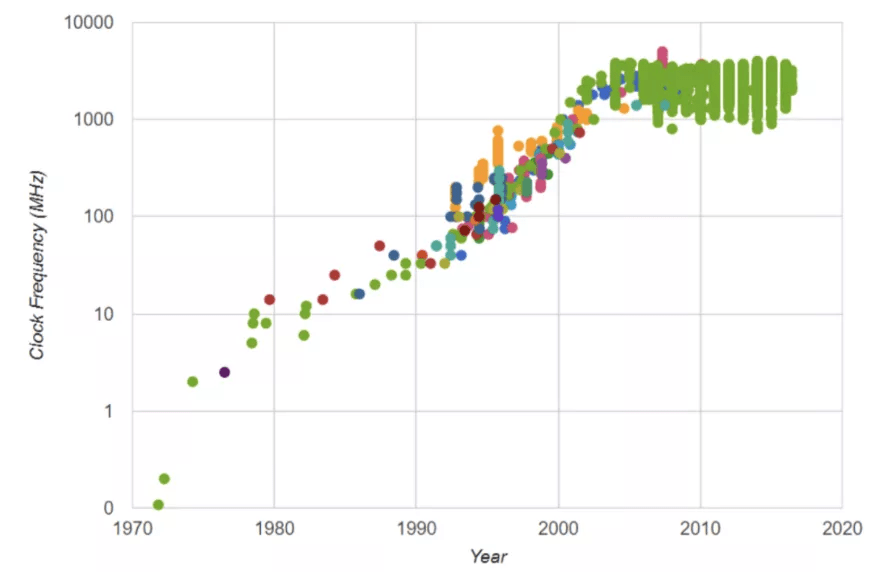
微处理器频率速率的演变 。
早期 , 微处理器行业主要集中在 CPU 上 , 因为 CPU 是当时计算机系统的主力 。 微处理器厂商充分利用了缩放定律 。 具体来说 , 他们的目标是提高 CPU 的频率 , 因为更快的晶体管使处理器能够以更高的速率执行相同的计算(更高的频率 = 每秒更多的计算) 。 这是一种有些简单的看待事物的方式;处理器有很多架构创新 , 但最终 , 在早期 , 频率对性能有很大贡献 , 从英特尔 4004 的 0.5MHz、486 的 50MHz、奔腾的 500MHz 到奔腾 4 系列的 3–4GHz 。
文章图片
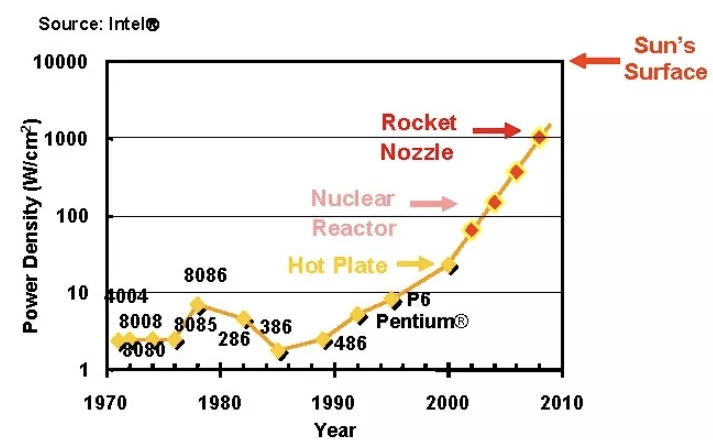
功率密度的演变 。
大约在 2000 年 , 登纳德缩放比例定律开始崩溃 。 具体来说 , 随着频率的提升 , 电压停止以相同的速率下降 , 功率密度速率也是如此 。 如果这种趋势持续下去 , 芯片发热问题将不容忽视 。 然而 , 强大的散热方案还不成熟 。 因此 , 供应商无法继续依靠提高 CPU 频率来获得更高的性能 , 需要想想其他出路 。
处理器发展第二阶段:多核时代(2000 年代 - 2010 年代中期)
停滞不前的 CPU 频率意味着提高单个应用的速度变得非常困难 , 因为单个应用是以连续指令流的形式编写的 。 但是 , 正如摩尔定律所说的那样 , 每过 18 个月 , 我们芯片中的晶体管就会变为原来的两倍 。 因此 , 这次的解决方案不是加快单个处理器的速度 , 而是将芯片分成多个相同的处理内核 , 每个内核执行其指令流 。
文章图片
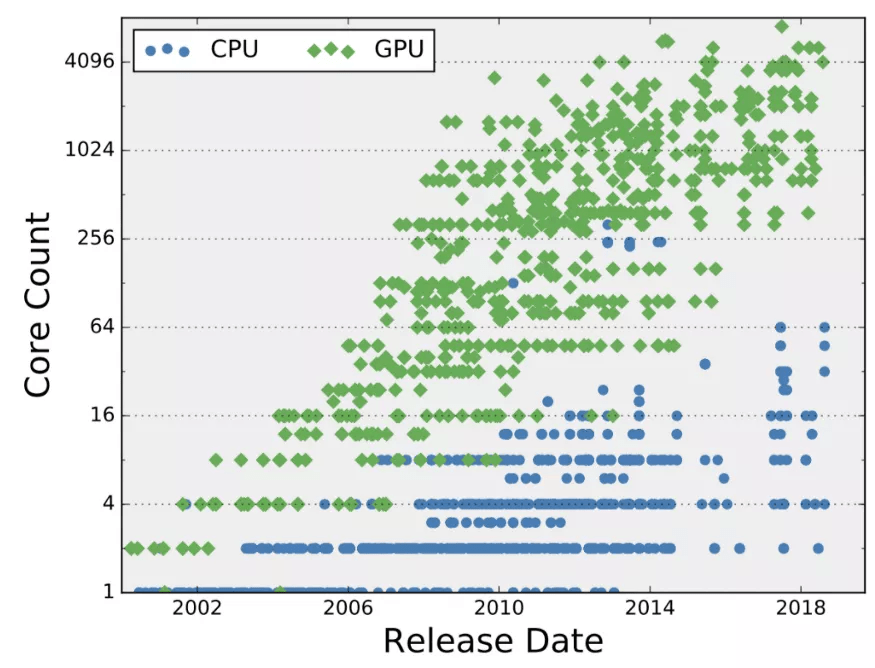
CPU 和 GPU 核数的演化 。
对于 CPU 来说 , 拥有多个内核是很自然的 , 因为它已经在并发执行多个独立的任务 , 比如你的互联网浏览器、文字处理器和声音播放器(更准确地说 , 操作系统在创建这种并发执行的抽象方面做得很好) 。 因此 , 一个应用可以在一个内核上运行 , 而另一个应用可以在另一个内核上运行 。 通过这种实践 , 多核芯片可以在给定的时间内执行更多的任务 。 然而 , 为了加快单个程序的速度 , 程序员需要将其并行化 , 这意味着将原始程序的指令流分解成多个指令「子流」或「线程」 。 简单地说 , 一组线程可以以任何顺序在多个内核上并发运行 , 没有任何一个线程会干扰另一个线程的执行 。 这种实践被称为「多线程编程」 , 是单个程序从多核执行中获得性能提升的最普遍方式 。
多核执行的一种常见形式是在 GPU 中 。 虽然 CPU 由少量快速和复杂的内核组成 , 但 GPU 依赖大量更简单的内核 。 通常来讲 , GPU 侧重于图形应用 , 因为图形图像(例如视频中的图像)由数千个像素组成 , 可以通过一系列简单且预先确定的计算来独立处理 。 从概念上来说 , 每个像素可以被分配一个线程 , 并执行一个简单的「迷你程序」来计算其行为(如颜色和亮度级别) 。 高度的像素级并行使得开发数千个处理内核变得很自然 。 因此 , 在下一轮处理器进化中 , CPU 和 GPU 供应商没有加快单个任务的速度 , 而是利用摩尔定律来增加内核数量 , 因为他们仍然能够在单个芯片上获得和使用更多的晶体管 。
文章图片
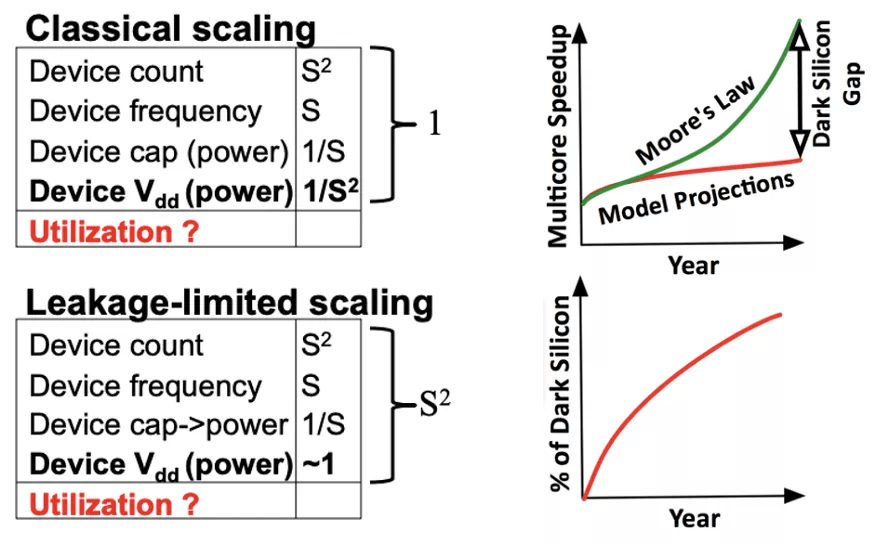
不幸的是 , 到了 2010 年前后 , 事情变得更加复杂:登纳德缩放比例定律走到了尽头 , 因为晶体管的电压接近物理极限 , 无法继续缩小 。 虽然以前可以在保持相同功率预算的情况下增加晶体管数量 , 但晶体管数量翻倍意味着功耗也翻倍 。 登纳德缩放比例定律的消亡意味着当代芯片将遭遇「利用墙(utilization wall)」 。 此时 , 我们的芯片上有多少晶体管并不重要——只要有功耗限制(受芯片冷却能力的限制) , 我们就不能利用芯片中超过给定部分的晶体管 。 芯片的其余部分必须断电 , 这种现象也被称为「暗硅」 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。