文章图片
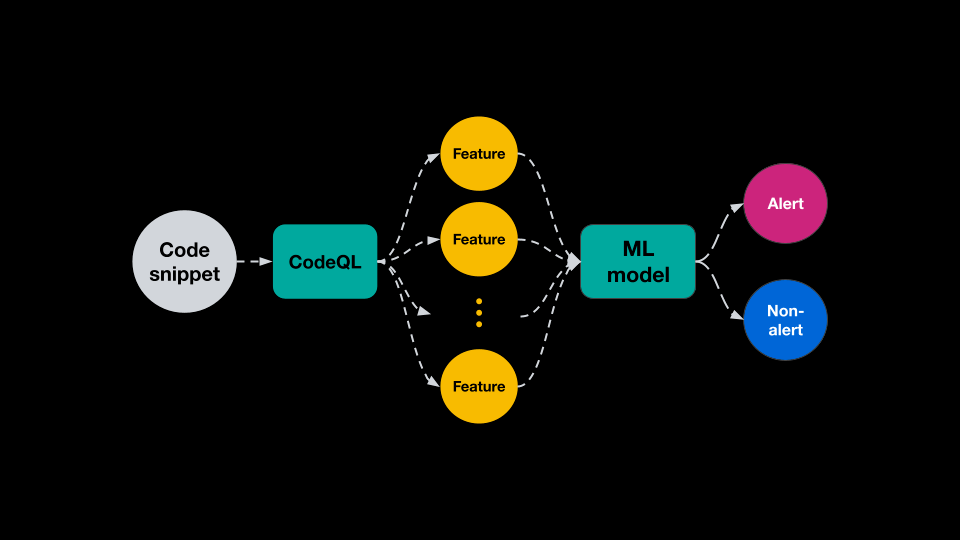
一旦为每个示例提取特征 , 就会像NLP应用程序中通常所做的那样对它们进行标记和子标记 , 并进行一些修改以捕获特定于代码语法的特征 。 安全员从训练数据中生成一个词汇表 , 并将索引列表输入到一个相当简单的DL分类器中 , 其中包含几层特征处理 , 然后是跨特征连接和几层组合处理 。
由于离线数据标记、特征提取和训练管道的规模 , 安全员利用云计算 , 包括用于模型训练的 GPU(图形处理器) 。 然而 , 在推理时 , 不需要GPU 。
对存储库的测试:召回率约为80% , 精确度约为60%
一旦拥有训练有素的ML模型 , 就会使用它来分类新的代码片段并检测每个查询可能存在的漏洞 。 当存储库所有者启用ML生成的警报时 , CodeQL会计算该代码库中代码片段的源代码特征 , 并将它们提供给分类器模型 。 该框架获取给定代码片段代表漏洞的概率 , 并使用该概率来显示可能的新警报 。
整个过程在GitHub Action运行器上运行 , 并且在大型存储库上增加一些运行时间 , 它对用户是透明的 。 代码扫描完成后 , 用户可以看到ML生成的警报以及手动查询出现的警报 。 在评估ML生成的警报时 , 安全员只考虑手动查询未标记的新警报 。
文章图片
为了大规模地测量指标 , 安全员使用上述实验设置 , 其中训练集中的标签是由手动查询的旧版本确定的 。 然后 , 在没有训练集的资源库上 , 安全员测试了该模型 , 并衡量其恢复的能力 。 衡量标准因查询而异 , 就平均而言 , 测量的召回率约为80% , 精确度约为60% 。
研究人员目前正在将ML生成的警报扩展到Java和Type的安全查询 , 并努力提高它们的性能和运行时间 。 未来的计划包括扩展更多的编程语言 , 以及能够查找到更多的漏洞 。
参考链接:https:// github.blog/2022-02-17-leveraging-machine-learning-find-security-vulnerabilities/
— END—
《新程序员001-004》全面上市 , 对话世界级大师 , 报道中国IT行业创新创造
— 推荐阅读 —
? 李想称十年后要成为汽车界苹果;雅虎邮箱停服;Linux内核欲采用现代C语言标准 | 极客头条
? 时隔六年 , FreeDOS终于更新 , 是否还能与Windows一战?
?下一代 面向知识的 BI 到底有何不同 , 从 nextionBI 数据解读能力中一探究竟
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。