
文章图片
论文地址:https://yuanmu97.github.io/preprint/InFi_MobiCom22.pdf
项目地址:https://github.com/yuanmu97/infi
可过滤性分析
直观来说 , 推理任务的可过滤性指:相较于原始推理任务 , 能否得到一个低成本、高精度的输入数据冗余性的预测器 。 原始的推理任务定义为属于函数族 H 的模型 h , 其将输入数据映射至推理输出 , 例如人脸检测模型以图片为输入 , 输出检测结果(人脸位置的检测框) 。 根据推理模型的输出结果 , 定义冗余性判断函数 f_h , 其输出冗余性标签 , 例如当人脸位置检测框输出为空时 , 将该次推理计算视为冗余 。 属于函数族 G 的输入过滤器 g 定义为从输入数据到冗余标签的映射函数 。

文章图片
假设原始推理模型的目标函数(即提供真实标签的函数)为 c, 其过滤器的目标函数为
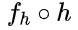
文章图片
, 则可见训练原始的推理模型和训练输入过滤器的区别在于监督标签的不同:推理预测由原始任务标签域 Y 监督 , 而过滤预测由冗余标签域 Z 监督 。 那么对于推理任务的可过滤性一个直观的想法是 , 如果学习输入过滤器比学习原始推理模型更简单 , 则有潜力得到有效的输入过滤器 。
基于此思路 , 该工作分析了三类常见推理任务的可过滤性:

文章图片
分析过程的关键在于将输入过滤器的目标函数与原始推理模型相关联 , 从而在两个学习任务间建立复杂度可比较的桥梁 。 以分类任务基于置信度进行冗余判别为例 , 输入过滤器的目标函数族形式为
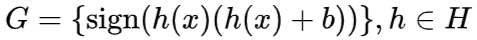
文章图片
, 依此可证明输入过滤器的函数族的 Rademarcher 复杂度小于等于原始推理模型 , 进而得到该任务可过滤性的分析结果 。
框架设计和实现
以上的可过滤性分析基于将输入过滤视为一个学习任务得到 , 因此框架设计需要具有端到端可学性 , 而不依赖手工特征或预训练深度特征 。 同时 , 框架设计应该统一地支持推理跳过(SKIP)和推理重用(REUSE)机制 。 该工作基于一个简洁的思路 , 即 SKIP 等价于对全零输入的推理结果的 REUSE , 将两种机制统一到一个框架之中 。
框架包含训练和推理两个阶段 。 训练阶段通过孪生特征网络为一对输入数据抽取特征 , 计算特征距离后由一个分类网络得到冗余标签预测结果 。

文章图片
在推理阶段 , 若采用 SKIP 机制 , 则将另一个输入的特征固定为零 , 退化为基本的分类器 , 根据预测的冗余性标签决策是否跳过当前输入数据;若采用 REUSE 机制 , 则需要维护一个 “输入特征 - 推理输出” 表作为缓存 , 通过计算当前输入特征与缓存的输入特征之间的距离 , 采用 K - 近邻方法决策是否重用缓存的推理结果 。
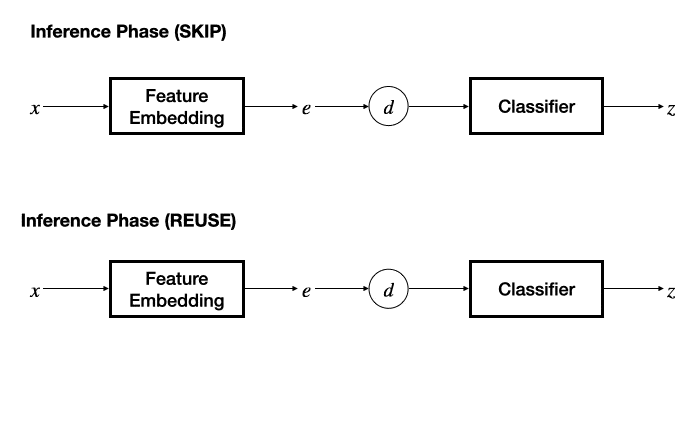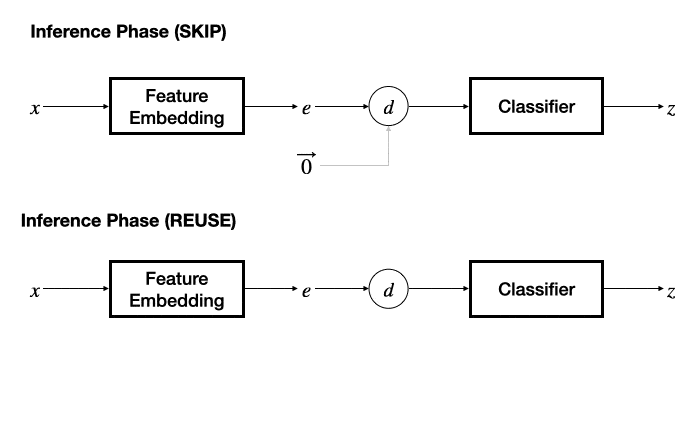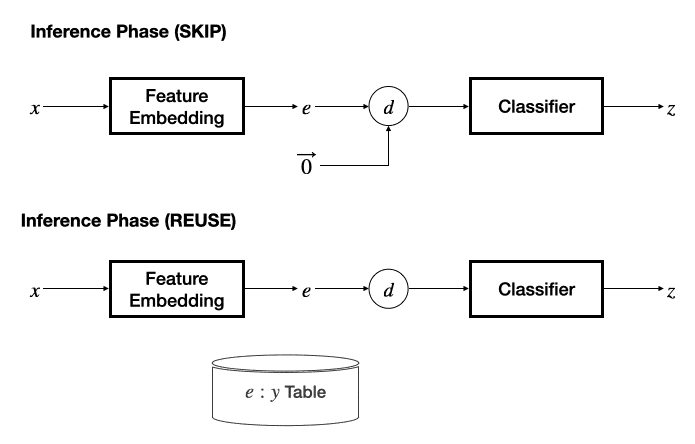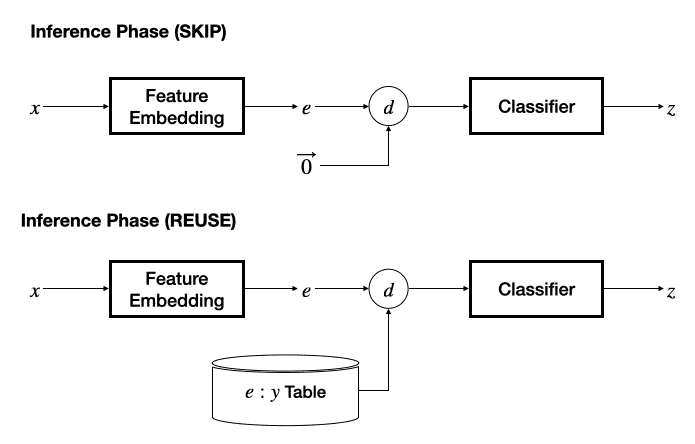
文章图片
该工作提出了 “模态相关的特征网络 + 任务无关的分类网络” 的设计 , 为文本、图像、视频、音频、感知信号、中间层特征设计了特征抽取网络 , 并能够很容易地扩展至更多数据模态 , 分类器网络则设计为多层感知机模型 。 对输入模态的灵活支持为 InFi 在不同的任务部署方式上的适用性提供了基础 , 包括三种典型的以移动为中心的推理任务部署方式:端上推理、卸载至边缘推理、端 - 边模型切分推理 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。