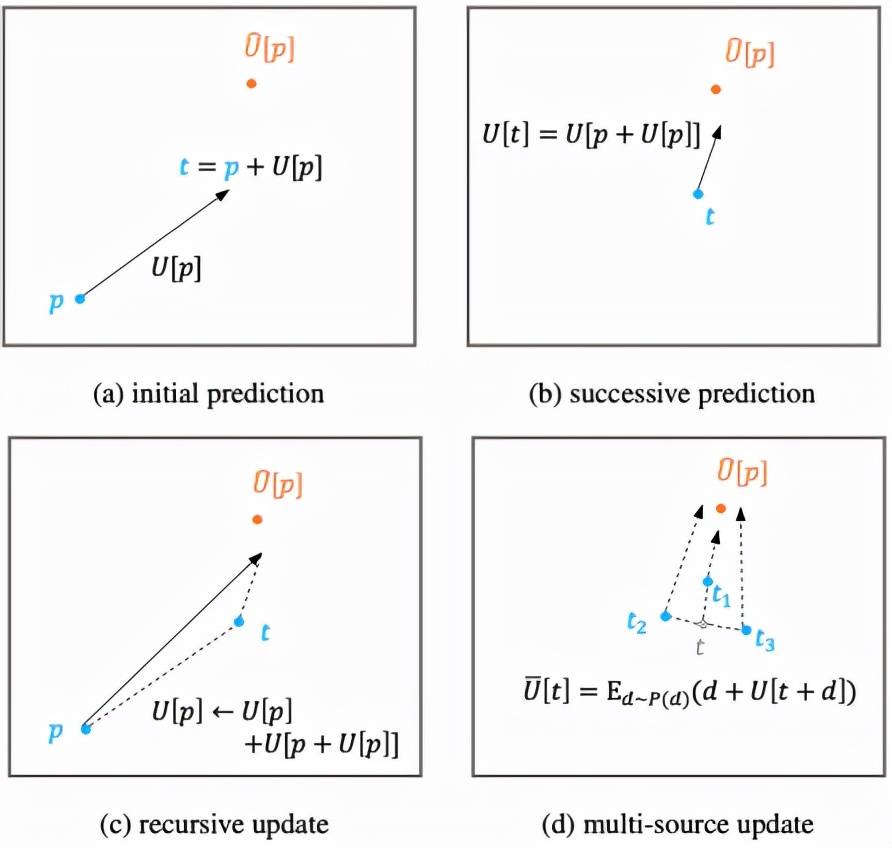
此外 , 用于人体关键点预测的特征提取于人体中心点处 , 这一特征对于远离中心点的人体关键点来说表示能力较弱 , 和目标在空间上的不一致问题会引起预测的较大误差 。 为了缓和这一问题 , 该算法提出了迭代更新策略 , 该策略利用历史更新结果为出发点 , 并整合中间结果附近预测值以逐步逼近最终目标 , 如图 3 所示
文章图片
图 3:迭代优化策略 。
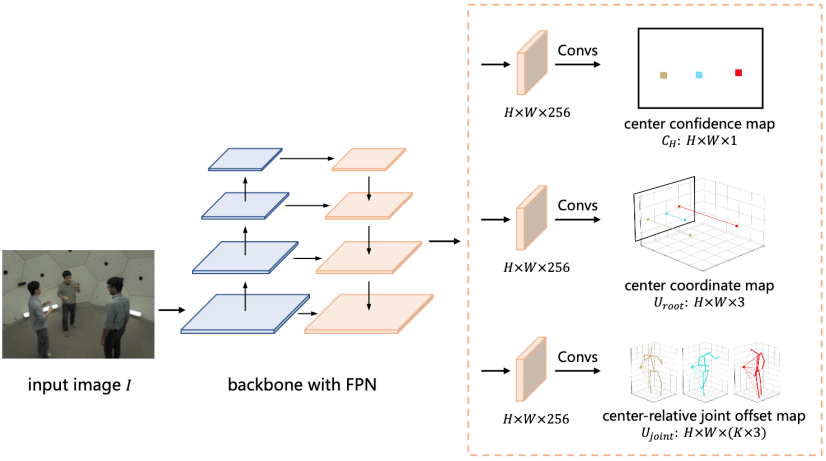
该算法模型通过全卷积网络(Fully Convolutional Networks, FCNs)实现 , 训练和测试过程都可以以端到端的方式进行 , 如图 4 所示 。
文章图片
图 4:分布感知式单阶段多人 3D 人体姿态估计网络结构 。
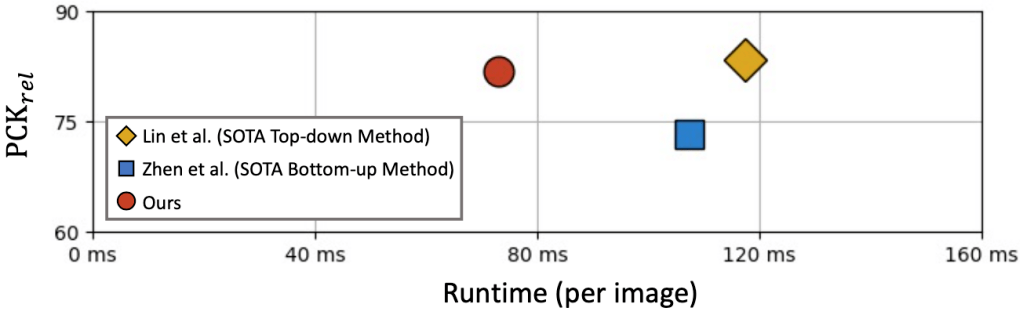
根据实验结果 , 如图 5 所示 , 单阶段算法和已有 state-of-the-art 两阶段方法相比 , 可以取得接近甚至更优的精度 , 同时可以大幅提升速度 , 证明了其在解决多人 3D 人体姿态估计这一问题上的优越性 。
文章图片
图 5:与现有 SOTA 两阶段算法对比结果 。
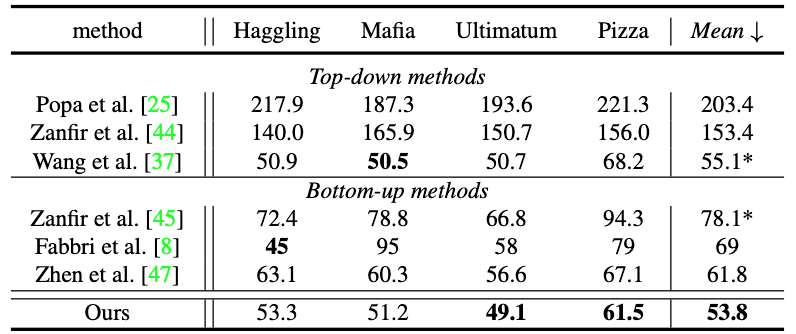
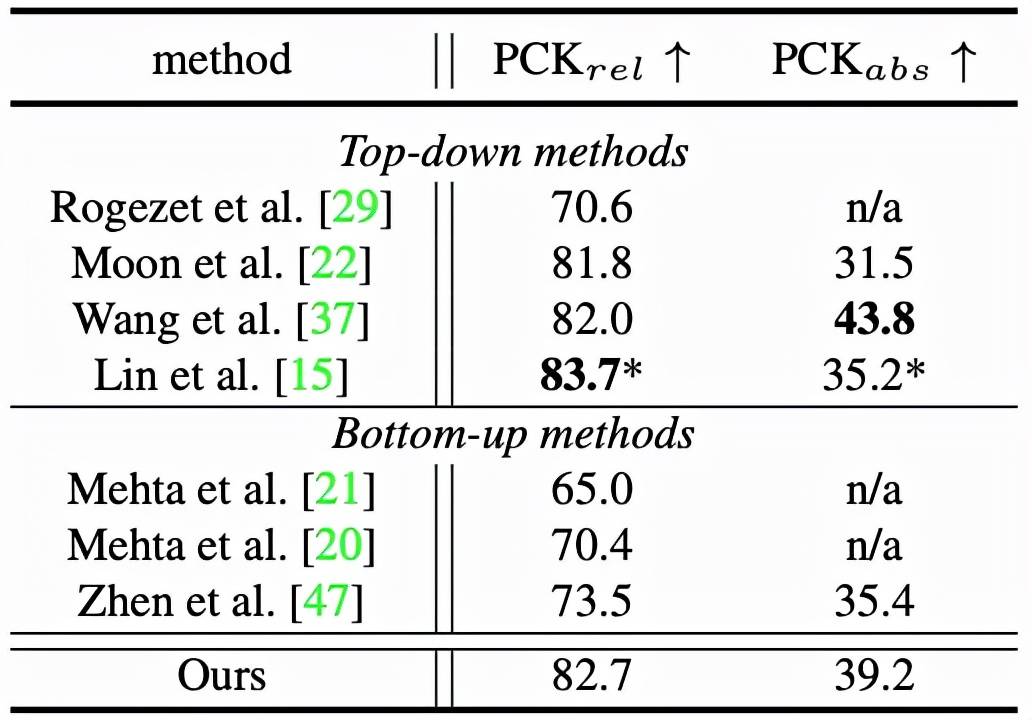
详细实验结果可参考表 1 和表 2 。
文章图片
表 1:CMU Panoptic Studio 数据集结果比较 。
文章图片
表 2:MuPoTS-3D 数据集结果比较 。
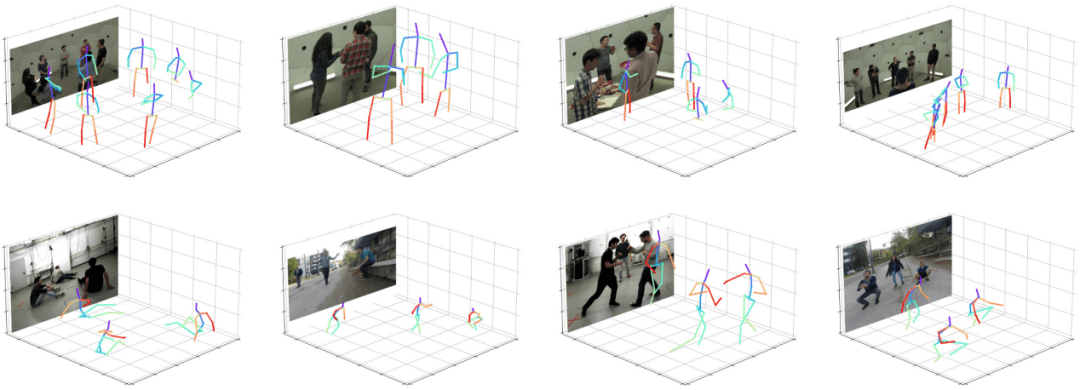
根据单阶段算法的可视化结果 , 如图 6 所示 , 该算法能够适应不同的场景 , 例如姿势变化、人体截断以及杂乱背景等来产生精确的预测结果 , 这进一步说明了该算法的健壮性 。
文章图片
图 6:可视化结果 。
总结
在本论文中 , 美图和北航的研究者们创新性地提出了一种分布感知式单阶段模型 , 用于解决极具挑战性的多人 3D 人体姿态估计问题 。 与已有的自顶向下和自底向上这种两阶段模型相比 , 该模型可以通过一次网络前向推理同时获取人体位置信息以及所对应的人体关键点位置信息 , 从而有效地简化预测流程 , 同时克服了已有方法在高计算成本和高模型复杂度方面的弊端 。
另外 , 该方法成功将标准化流引进到多人 3D 人体姿态估计任务中以在训练过程中学习人体关键点分布 , 并提出迭代回归策略以缓解分布学习难度来达到逐步逼近目标的目的 。 通过这样一种方式 , 该算法可以获取数据的真实分布以有效地提升模型的回归预测精度 。
研究团队
本论文由美图影像研究院(MT Lab)和北京航空航天大学可乐实验室(CoLab)研究者们共同提出 。 美图影像研究院(MT Lab)是美图公司致力于计算机视觉、机器学习、增强现实、云计算等领域的算法研究、工程开发和产品化落地的团队 , 为美图现有和未来的产品提供核心算法支持 , 并通过前沿技术推动美图产品发展 , 被称为「美图技术中枢」 , 曾先后多次参与 CVPR、ICCV、ECCV 等计算机视觉国际顶级会议 , 并斩获冠亚军十余项 。
引用文献:
[1] JP Agnelli, M Cadeiras, Esteban G Tabak, Cristina Vilma Turner, and Eric Vanden-Eijnden. Clustering and classifica- tion through normalizing flows in feature space. Multiscale Modeling & Simulation, 2010.
[12] Jiefeng Li, Siyuan Bian, Ailing Zeng, Can Wang, Bo Pang, Wentao Liu, and Cewu Lu. Human pose regression with residual log-likelihood estimation. In ICCV, 2021.
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。