其二, 为深度学习算法喂大量数据, 让其准确率达到自动驾驶上路要求 。 特斯拉今年8月份开始陆续抛弃毫米波雷达, 彻底选择了纯视觉技术路线, 离不开其长期大量的数据积累和数据训练 。 特斯拉首席财务官Zachary Kirkhorn说, 到目前为止, 特斯拉已经收集了超过1亿英里的驾驶数据 。 算法与算力相辅相成, 特斯拉的AI超算也排名世界前三 。
其三, 多传感器融合方案, 即视觉+激光雷达+毫米波雷达 。 视觉相当于人的眼睛, 但还有听觉, 多种感知结合能让机器成为一个更健全的“人” 。
马斯克说的“视觉可以解决95%-99%的辅助驾驶场景”限定得很清楚, 仅“辅助驾驶”场景 。 因为视觉无法应对阳光直射、超低能见度情况, 无法应对, 而通过多传感器融合方案能有效提高自动驾驶鲁棒性和应对复杂场景的能力 。
当然, 多传感器融合方案也面临一个很现实的问题:成本高 。 这也是马斯克选择纯视觉方案的主要原因, 定位于“做人人都买得起的电动车” 。
数据很“香”, 既近又远数据是AI时代的生产资料, 据市场预估, 智能汽车生成数据的价值, 到2030年, 可能高达4500-7000亿美元 。 但如何挖掘这些数据价值?
首当其冲的难题是, 数据标准化和共享 。 因为不同公司的传感器数据, 包括位置、高度、角度这些初始参数都不同 。 比如宝马的数据拿给一汽, 完全没法用 。
而且, 考虑隐私、网络安全和保持竞争优势方面, 企业通常不愿意与其他利益相关者共享这些数据, 包括测试、运营和客户行为等各类数据 。
车本身的E架构(Electrical/Electronic Architecture, 汽车电子电气架构)也是一个问题 。 它是整合汽车内各类传感器、处理器、线束连接、电子电气分配系统和软硬件生成的总布置方案 。 过去绝大部分汽车的E架构按照功能信号来设计的, 做成了集成的通用平台 。 今天智能车的E架构融合了数据架构和计算架构, 但包括特斯拉在内的企业, 都还未认真考虑过数据架构和计算架构, 这将导致数据获取成为一个隐藏的大问题 。
据了解, 一台车每天能产生大概4000GB的数据, 如果是十万台甚至百万台, 这些数据的传输到云端的成本就会骤升 。 所以最好的办法, 就是能够在边缘侧处理数据, 将垃圾数据处理掉, 把有效的特征点提取出来 。

文章插图
据希捷科技发布、国际数据公司(IDC)调研完成的《数据新视界:从边缘到云, 激活更多业务数据》报告称, 企业目前定期将大约36%的数据从边缘传输到核心, 两年后, 这一比例将增至57% 。 从边缘立即传输到核心的数据量将翻倍, 从8%增长到16% 。
自动驾驶还需解决数据分布“长尾问题”的任务, 时而出现的corner case(极端情况)是对数据驱动的算法模型进行升级的来源之一 。
打造数据闭环是绕不过去的坎 。 以谷歌waymo报告提到的数据闭环平台为例, 它包括数据挖掘、主动学习、自动标注、自动化模型调试优化、测试校验和部署发布 。 打通这些全链路, 才能让数据高效、高质回流 。
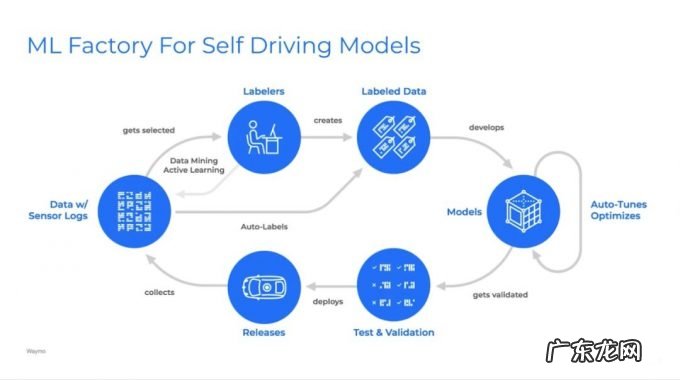
文章插图
云计算是打通数据闭环的基础, 它在资源管理调度、数据批处理/流处理、工作流管理、分布式计算、系统状态监控和数据库存储等方面提供了数据闭环的基础设施支持, 比如亚马逊AWS、微软Azure和谷歌云等 。
腾讯自动驾驶总经理苏奎峰说:“自动驾驶的核心竞争力在于数据要素和计算资源的低成本获取和高效利用 。 对数据要素进行高效收集和利用, 提高数据循环链路的速度, 是整个自动驾驶技术迭代的关键点 。 ”
- 微信怎么取消芒果连续包月? 芒果tv会员怎么取消自动续费
- 电脑qq音乐怎么下载到u盘? qq付费音乐包怎么取消自动续费
- 虚商号码不用了需要注销掉吗 手机号码暂时没用会自动注销吗
- 搜狐视频会员怎么关闭自动续费? 手机搜狐视频会员怎么取消自动续费
- 苹果手机爱奇艺会员取消不了? 苹果手机如何取消爱奇艺自动续费
- 新车6万左右自动挡最好的车 6万左右买什么车好新车自动
- 开心果是自己开口的吗 成熟后自动裂开
- 逾期怎么停止自动扣款? 支付宝银行卡解绑
- 淘宝什么输入法可以自动刷屏 什么输入法可以自动刷屏
- 索尼首次推出自动驾驶激光雷达传感器
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。