碳排放核算方法
我们团队其实是将碳排放统计公式做了一个多维的延伸 。 比如 , 我们会用不同的数据源 , 包括遥感、GPS 、环境监测站点等数据来计算活动水平 , 然后引入通过实测和人工智能等方法获得实时核算的、较准确的排放因子来计算碳排放 。
这里补充一句 , 我们当时做此事有一个动机 , 即在新冠疫情开始的时候 , 我们想知道疫情到底能导致多少碳排放的变化 , 如果根据刚提到的简单计算方法得到两年前的碳排放量 , 实际上对于我们现在的政策制定都没有太大的意义 。
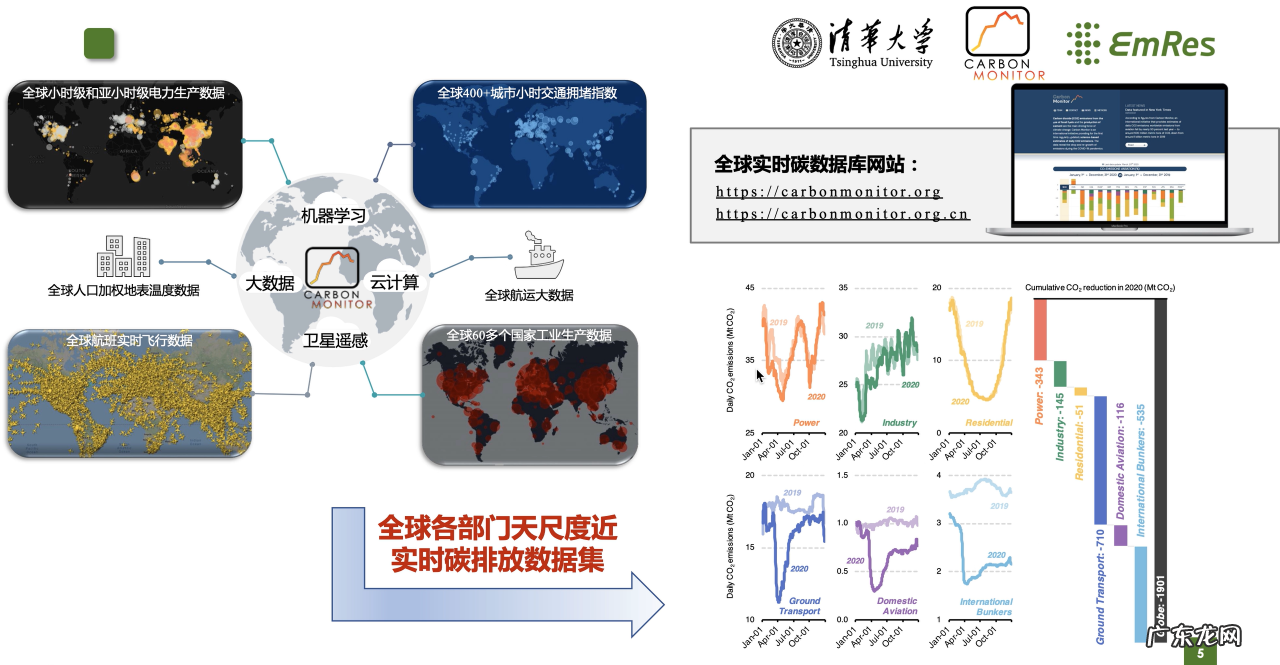
因此 , 从整体流程架构来看 , 我们选择采取多源大数据的统计方法 , 通过建立一套从原始数据到排放数据的碳核算模型 , 最终覆盖了全球从电力、地面交通、航空、工业、居民消费、海运等六大部门的碳排放 。 基于这些数据 , 我们就可以看到碳排放随季节、日期 , 包括一些突发事件等的变化情况 。 除此之外 , 我们对数据源和核算方法都有完整的不确定性评估 , 是一套可靠的科学方法 。
那给大家简单展示一下 。 左下图是我们的多源数据统计的结果 , 右图是六个部门以天为尺度的碳排放变化 , 这是一个非常大的飞跃 , 将原来一年只有一个数据点的情况转变为我们现在一天一个数据点的现状 。 对应的这个成果 , 我们也建立了自己的网站 , 展示了相应的数据和成果 。
文章插图
相关数据表达展示
从实际意义来看 , 如图 , 从1750年到2000年只有大概 250 个碳排放数据点 , 从2000年之后 , 我们每一天都可以有一个数据点 , 那这样反应出来的碳排放的变化和信息量与往日完全不是一个等级的 。 因此 , 我们这个结果也因为它的实时性 , 受到了Nature杂志一年内多次的头版头条的报道 , 同时也被联合国环境署等一些机构用于他们2020年碳排放的基础数据 , 而其他数据库并没有这个特点 。

文章插图
实时碳数据统计
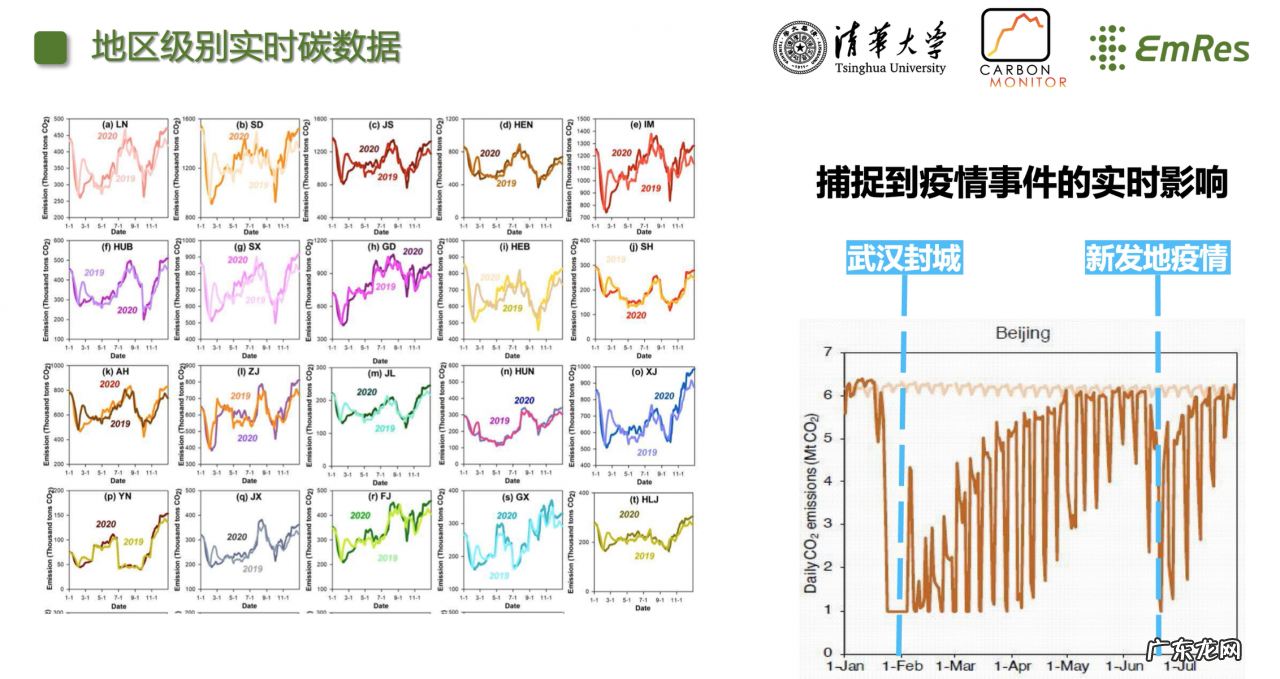
刚才讲的是全球尺度的 , 我们也在做一些更小尺度展示碳排放的一些工作 , 提高碳数据的应用价值与科学价值 。 比如 , 我们近期刚发布了GRACED全球每日碳排放地图 , 可以覆盖到全球90%以上的国家和地区 , 空间分辨率达到了0.1*0.1经纬度 , 涵盖了电力、工业等部门 。 具体采用的方法是以 CarbonMonitor 为基础 , 然后用我们自己掌握的点源和同源排放污染物的数据 , 将碳排放具体分配到每一个 0.1*0.1度的网格当中 。
例如 , 图中是中国省级的以天为尺度的二氧化碳排放变化的成果 。 那我们拿到这些数据之后可以看到什么呢?首先很明显就可以捕捉到疫情事件的实时影响 。 如果大家还记得武汉封城的这一天 , 就可以明显的看到碳排放的急剧变化 。 对于新发地的疫情 , 也可以看到相应的变化量 。 这个数据的价值在于可以为地方政府和企业提供一个低碳措施的放大器 , 实时掌握碳排放这一不易观察的数据变化 。
文章插图
地区级别实时碳数据
那说到碳中和 , 另外一个很关键的点就是碳汇 , 因为人类生产生活的方式决定了有一些二氧化碳是不可能被完全消除的 , 所以除了不断地推动低碳的发展 , 另外一个很重要的点就是提高碳汇 。
我们团队和微软亚洲研究院在去年展开了建立全球负碳排放数据库的工作 。 实际上和碳排放的这个思路是一样的 , 具体是借助微软的机器学习能力 , 加上团队已建立的自然/人工碳汇数据和模型 , 最后生成了一个全球首个高分辨率的负碳模型 。
- 都市丽人公告:原CEO离职 创始人郑耀南回归经营一线
- 市场要闻 | 辉瑞CEO称奥密克戎不可能完全突破现有疫苗,市场恐慌过度了?
- 出海日报丨中国连续12年保持非洲最大贸易伙伴国地位;Twitter联合创始人杰克·多西辞去CEO一职
- 社交巨头新任印度裔CEO何许人?马斯克:人才
- 市场热捧,微软CEO却抛售半数持股,发生了什么?
- 行业地震,推特创始人多西辞任CEO,全身心投入比特币?
- Twitter:杰克·多西辞去CEO一职,CTO接任
- 36氪首发|橡鹭科技完成亿元天使轮融资,原美团核心高管老K担任CEO
- 创壹科技CEO梁子康:创造柳夜熙,我们核心在于“内容力” | 2021WISE元宇宙·机器人峰会
- 大族机器人CEO王光能:机器人与人工智能结合,是未来机器人的发展方向 | 2021WISE元宇宙·机器人峰会
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。