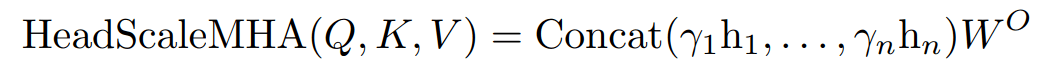
文章图片
额外层归一化以及将所有组件放在一起 。 在 Pre-LN transformer 中 , 每个层 l 将输入 x_l 做出如下修改:

文章图片
相反 , NormFormer 将每个输入 x_l 修改如下:
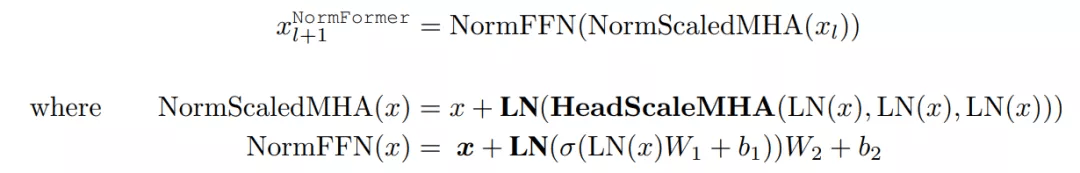
文章图片
其中 , 新引入了 bolded operations 。
实验结果
对于因果语言模型(Casual Language Model) , 研究者预训练的 CLM 模型分别为 Small(1.25 亿参数)、Medium(3.55 亿参数)、Large(13 亿参数)和 XL(27 亿参数) 。
他们训练了 3000 亿个 token 的基线模型 , 并用等量的 GPU 小时数训练 NormFormer 模型 , 由于归一化操作的额外开销 , 后者通常会减少 2%-6% 的 steps 和 tokens 。
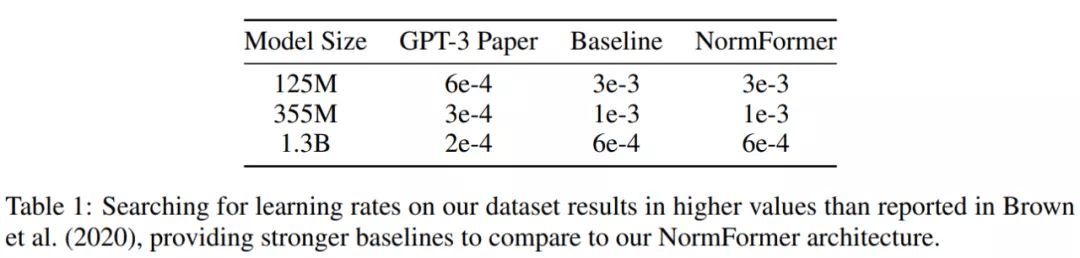
在使用的数据集上 , 研究者发现 GPT-3 中提出的学习率不是最理想的 。 因此 , 对于除了 27 亿参数之外的每个大小的基线和 NormFormer 模型 , 他们通过训练 5 万 steps 的模型并从 {1e?4, 6e?4, 3e?4, 6e?4, 1e?3, 3e?3} 中选择性能最佳的学习率来对学习率进行调整 。 这一过程中获得的学习率如下表 1 所示 , NormFormer 的学习率是 GPT-3 的 3-5 倍 。
文章图片
对于掩码语言模型(Masked Language Model, MLM) , 研究者采用了 Liu et al. (2019)中使用的 RoBERTa-base、Pre-LN 架构和超参数 。 对于基线模型 , 他们对 100 万个 token 预训练了 200 万个 batch , 是原始 roberta-base 训练预算的 1/4 。 相较之下 , NormFormer 在相同时间内运行了 192 万个 batch 。
对于预训练数据 , 研究者在包含 CC100 英语语料库以及由 BookCorpus、英文维基百科和 Common Crawl 过滤子集组成的 Liu et al. (2019)的数据英语文本集合上对所有模型进行预训练 。
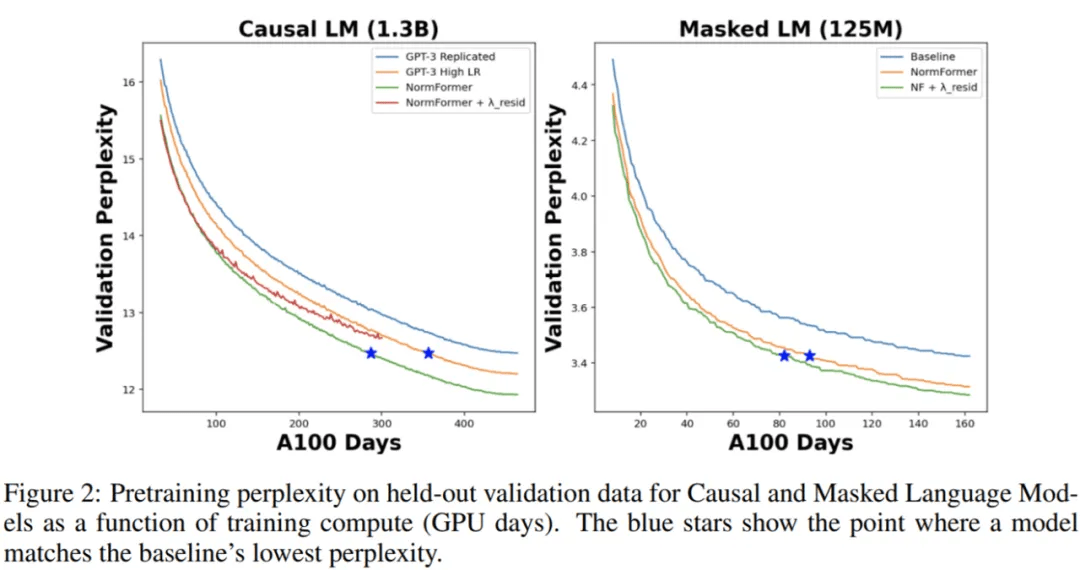
在下图 2 中 , 研究者将 CLM 和 MLM 的预训练困惑度表示训练时间 , 即 GPU days 。 可以看到 , NormFormer 的训练速度明显更快 , 并且在给定训练计算预算下实现了更好的验证困惑度 。
文章图片
研究者在下游任务上也观察到了类似的趋势 。 如下表 2 所示 , 研究者使用 Brown et al. (2020)中的任务和 prompt 来观察 CLM 模型的零样本准确率 。 同样地 , NormFormer 在所有大小上均优于 GPT-3 。

文章图片
对于 MLM 模型 , 研究者在下表 3 中报告了在 GLUE 上的微调准确率 。 再次 , NormFormer MLM 模型在每个任务上都优于它们的 Pre-LN 模型 。
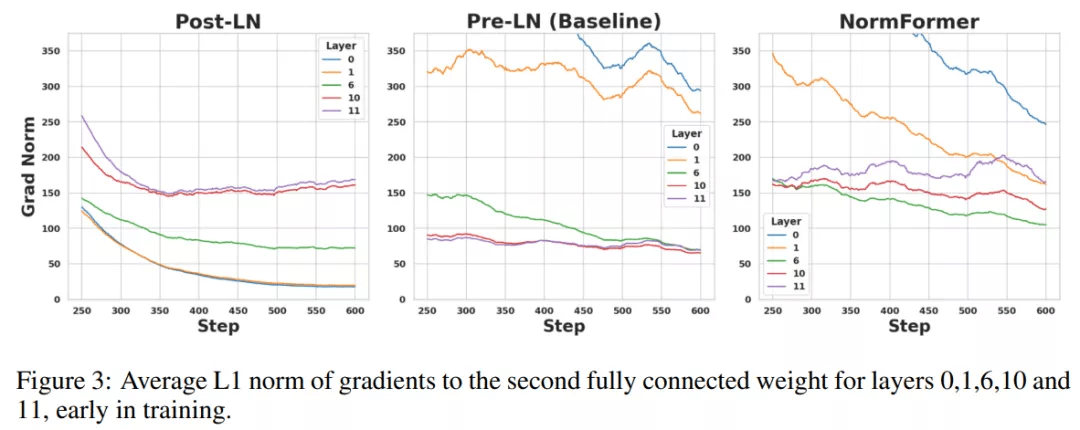
文章图片
为了度量架构的稳定性 , 研究者使用具有极大峰值学习率的学习率计划对其进行训练 , 使得学习率每个 step 增加一点 , 直到损失爆炸 。 图 5 显示了与基线相比 , NormFormer 模型在此环境中可以承受更多的更新 。
【归一化提高预训练、缓解梯度不匹配,Facebook的模型超越GPT-3】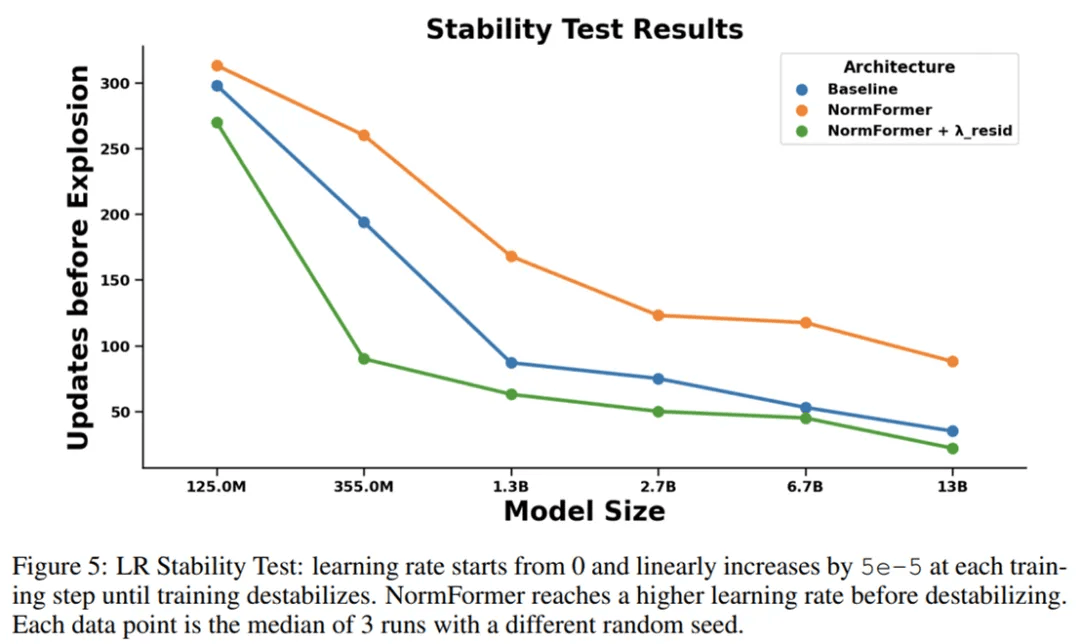
文章图片
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。