- 如何更好的定位哪些Hive任务可以迁移,哪些不可以
- 如何让业务部门无感知的从Hive迁移到Spark SQL
- 如何进行对比分析,确认任务迁移前后的运行效果
在迁移业务job时 , 我们需要知道这个部门有哪些人 , 由于Azkaban在执行具体job时会有执行人信息 , 所以我们可以根据执行人来推测有哪些job 。 分析程序使用了元数据系统的某些表数据和azkaban相关的一些库表信息 , 用来帮助我们收集迁移的部门下有多少hive job , 以及该hive job有多少sql , sql语法通过率是多少 , 当然在迁移时还需要查看Azkaban的具体执行耗时等信息 , 用于帮助我们在精细化调参的时候大致判断消耗的资源是多少 。
由于线上直接检测某条sql是否合乎spark语义需要具有相关的读写权限 , 直接开放权限给分析程序不安全 。 所以实现的思路是通过使用元数据系统存储的库表结构信息 , 以及azkaban上有采集业务job执行的sql信息 。 只要拥有某条sql所需要的全部库表信息 , 我们就能在本地通过重建库表结构分析该条sql是否合乎spark语义(当然线上环境和本地是有不同的 , 比如函数问题 , 但大多情况下是没有问题的) 。
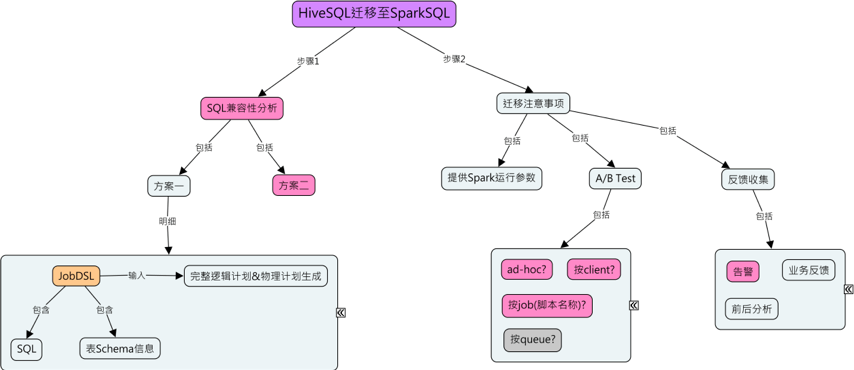
文章图片
图3-1-1
以下为某数据部通过分析程序得到的SQL通过率
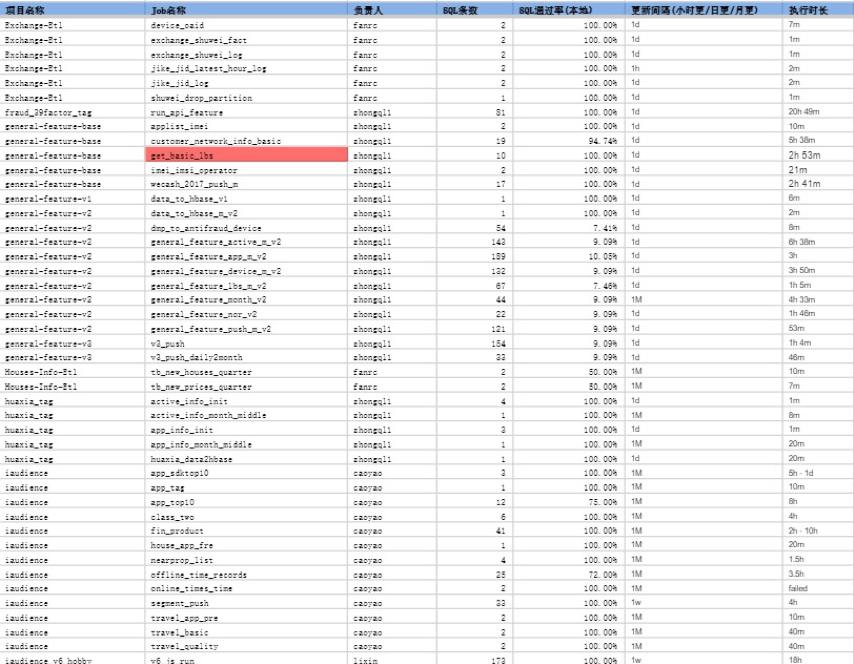
文章图片
3.2 SQL执行引擎的无感知切换
目前业务方使用Hive的主要方式是通过beeline去连接hiveserver2 , 由于livy也提供了thriftserver模块 , 所以beeline也可以直接连接livy 。 迁移的策略就是先把合乎Spark语法的SQL发往livy执行 , 如果执行失败再切换到Hive进行兜底执行 。
beeline可获取用户SQL , 启动beeline时通过thrift接口创建livy session , 获取用户sql发送给livy 执行 , 期间执行进度等信息可以查询livy获得 , 同时一个job对应一个session , 以及每启动一次 beeline对应一个session , 当job执行完毕或者beeline被关闭时 , 关闭livy session 。 (如果spark不能成功执行则走之前hive的逻辑)
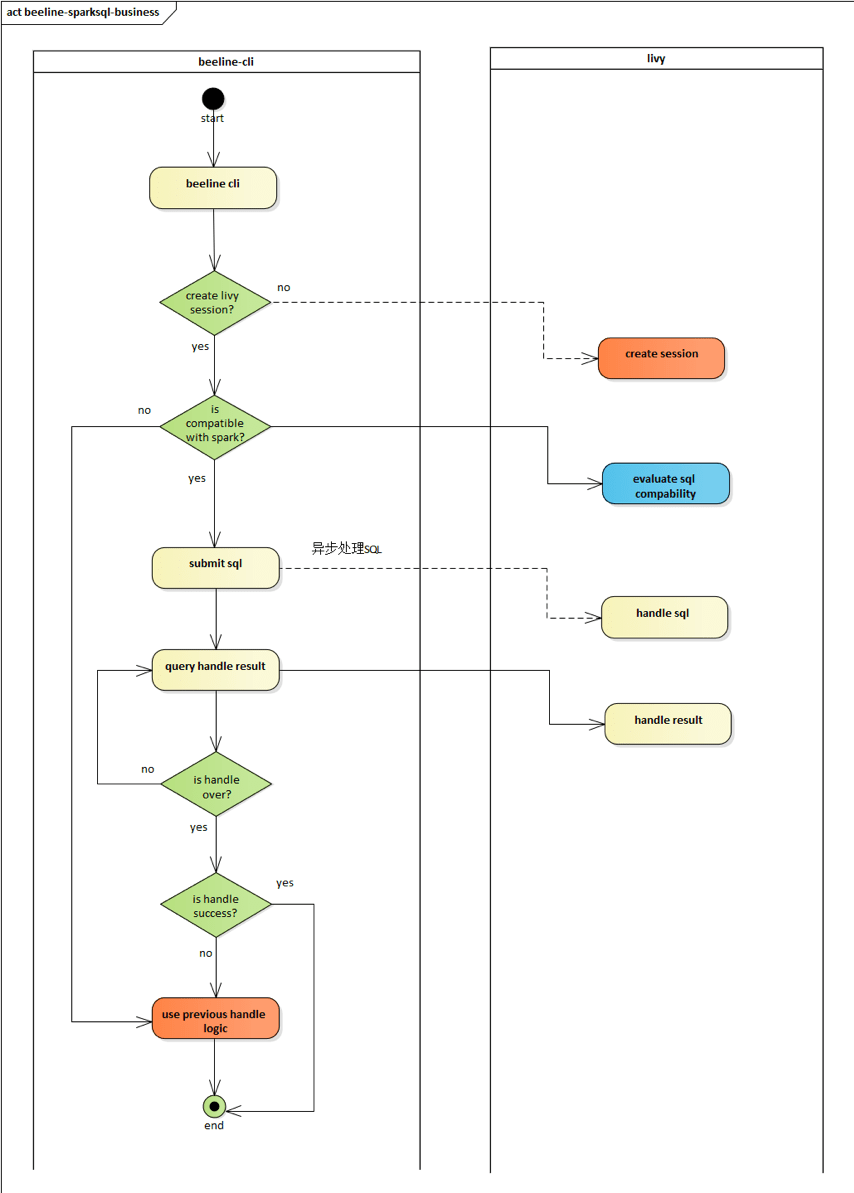
文章图片
图3-2-1
有了以上切换思路以后,我们开始着手beeline程序的修改设计
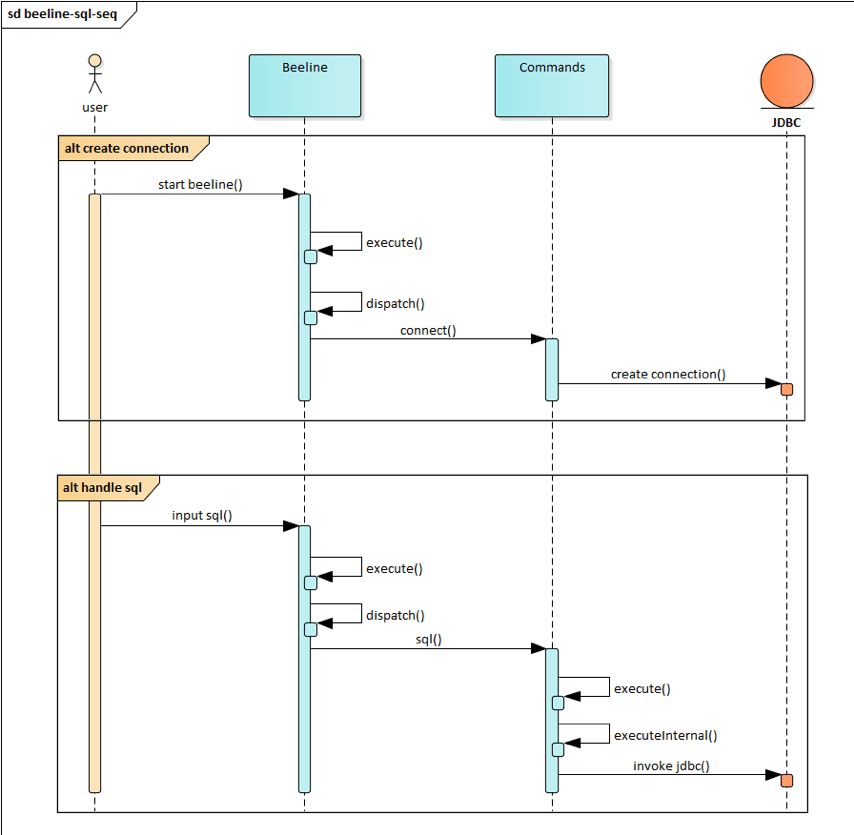
beeline重要类图如图3-2-2所示, Beeline类是启动类 , 获取用户命令行输入并调用Commands类去 执行 , Commands负责调用JDBC接口去执行和获取结果, 单向调用流程如图3-2-3所示 。
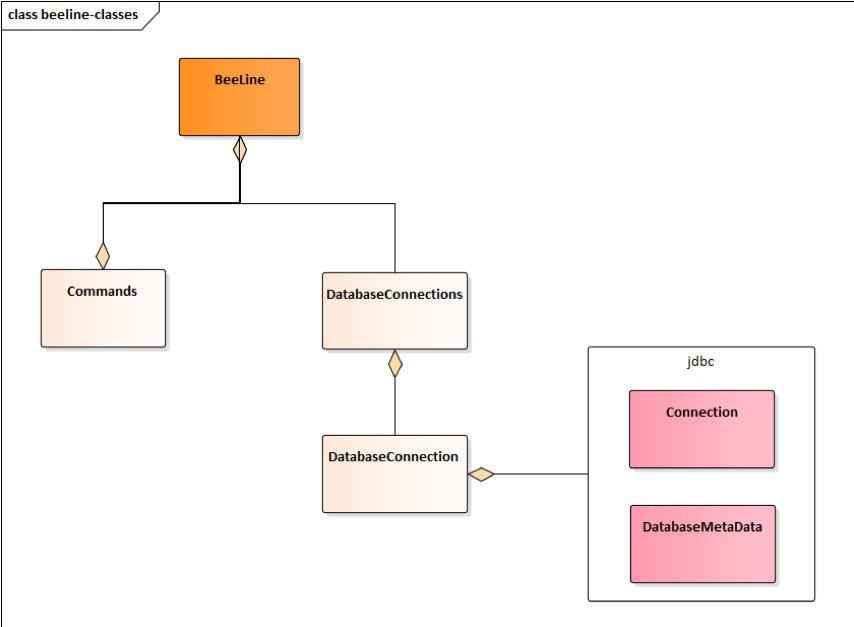
文章图片
图3-2-2
文章图片
图3-2-3
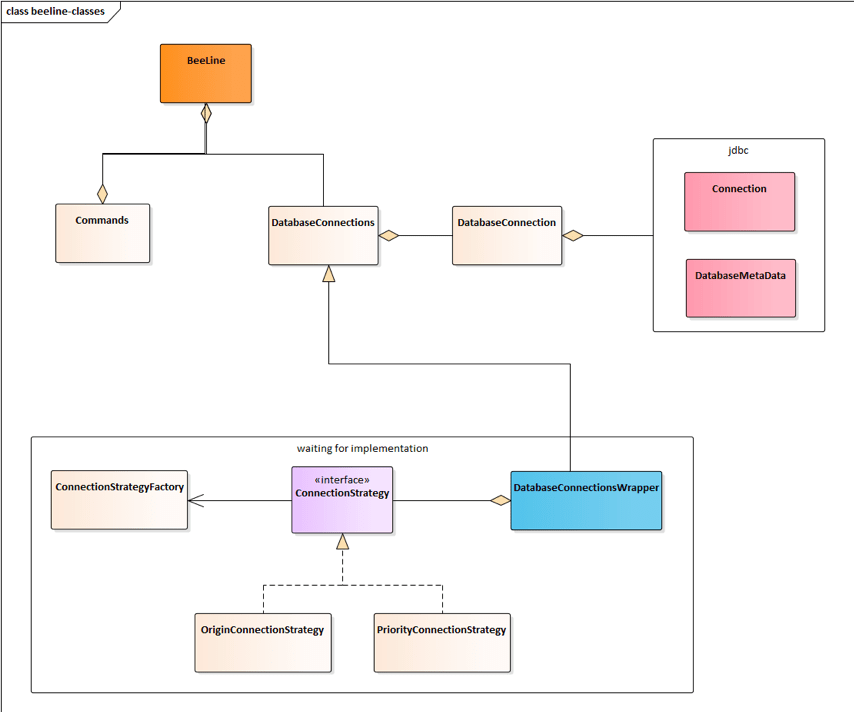
由图3-2-2和图3-2-3可知 , 所有的操作都是通过DatabaseConnection这个对象去完成的 , 持有这个 对象的是DatabaseConnections这个对象 , 所以多计算引擎切换 , 通过策略适配
DatabaseConnections对象 , 这样就能在不修改其他代码的情况下切换执行引擎(即获取不同的 connection)
文章图片
图3-2-4
3.3 任务迁移黑名单
前文有说到,当一个Hive任务用SQL分析程序走通,并且在迁移程序用livy进行Spark任务提交以后,还是会有可能执行失败,这个时候我们会用Hive进行兜底执行保障任务稳定性 。 但是失败的SQL会有多种原因,有的SQL确实用Hive执行稳定性更好,如果每次都先用Spark SQL执行失败以后再用Hive执行会影响任务效率,基于以上目的,我们对迁移程序开发了黑名单功能,用来保障每个SQL可以找到它真正适合的执行引擎,考虑到beeline是轻量级客户端 , 识别的功能应该放在livy-server侧来做 , 开发一个类似HBO的功能来将这样的异常SQL加入黑名单 , 节省迁移任务执行时间 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。