更准确地讲 , 该研究有一个潜在 bi-gram 嵌入表 B ? R^v×h×d_b , 其中 v 为 bi- gram 词汇 , d_b 为 bi-gram 嵌入维度 。 然后将文本序列 bi-gram 嵌入构建为:
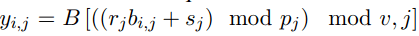
文章图片
与嵌入进行结合
最后一步是将 uni-gram 嵌入 x ? R^(l×h×d)与潜在 bi-gram 嵌入 y∈R^(l×h×db)相结合 , 形成文本序列新表示 。 bi-gram 嵌入和 uni-gram 嵌入都是独立的层归一化(LN) , 然后沿着嵌入维度连接两者以产生 w = [LN(x), LN(y)] ? R^l×h×(d+db), 并将其作为输入传递给 Transformer 网络的其余部分 。
实验结果
该研究在 C4 数据集上将 N-grammer 模型与 Transformer 架构(Vaswani 等人 , 2017 年)以及最近提出的 Primer 架构(So 等人 , 2021 年)进行了比较 。 其中 , 该研究使用 Adam 优化器 , 所有模型的学习率为 10^-3 , 而对于 n-gram 嵌入表 , 学习率为 10^-2 。
下表 1 比较了 N-grammer、Primer 和 Transformer 模型 , 其中基线 Transformer 模型有 16 层和 8 个头 , 模型维度为 1024 。 研究者在 TPU v3 上以 256 的批大小和 1024 的序列长度训练所有模型 。 研究者对 N-grammer 模型进行了消融研究 , bi-gram 嵌入维度大小从 128 到 512 不等 。 由于添加 n-gram 嵌入增加了可训练参数的数量 , 该研究还在表 1 中训练了两个大基线(Transformer-L 和 Primer-L) , 它们的参数顺序与 N-grammer 模型相同 。 然而 , 与较大的 Transformer 模型不同 , N-grammer 的训练和推理成本与嵌入层中的参数数量不成比例 , 因为它们依赖于稀疏操作 。
该研究还测试了一个简单版本的 N-grammer , 研究者直接从 uni-gram 词汇表(3.3 节中的)而不是从潜在表示中计算 n-gram(3.1 节的) 。 由表 1 可知 , 它对应于在 clusters 列中没有条目的 N- grammer 。
【引入N-gram改进Transformer架构,ACL匿名论文超越Primer等基准】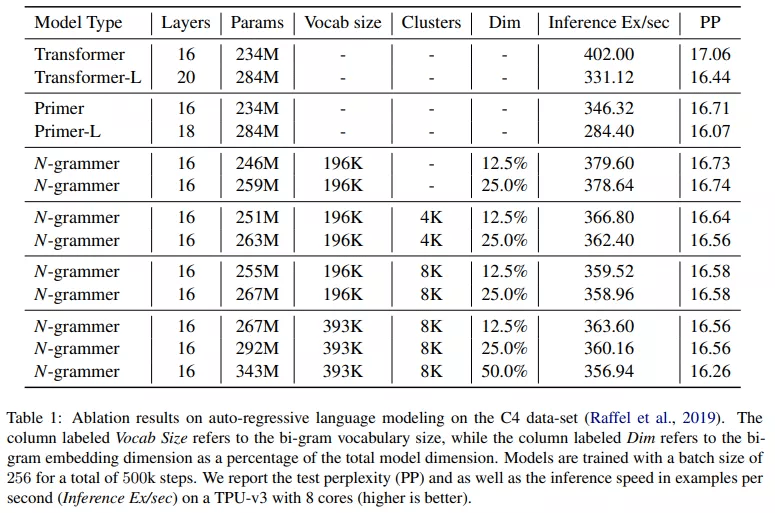
文章图片
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。