Hadoop作为部署数据湖最常用的技术 , 以其生态为核心的大数据框架已经十分成熟 。 随着数据总量和形式的不断增长 , 存算分离成了大数据架构发展的主流方向 。
此前 , 杉岩数据对Hadoop生态中HDFS当前存在的一些局限性作了分析 , 并介绍了基于杉岩数据高性能存储引擎的大数据存算分离场景存储解决方案 。 本文将进一步介绍在实际项目落地过程中 , 杉岩数据MOSFS存算分离方案处理新老架构更替的具体方法与操作步骤 。
场景分析 :从存算一体到存算分离
场景一:新建独立计算平台采用存算分离架构
第一次建设大数据计算平台就直接采用存算分离架构 , 同时在有新业务系统扩展时规划搭建独立的计算平台场景 。 这是新大数据平台搭建且独立运作的场景 , 不涉及到老数据的使用 , 也是最简单的存算分离落地场景 。
场景二:新建大数据平台完全替换原有平台
直接新建更强的大数据计算平台完全替换原有计算平台 , 在计算平台升级换代时采用存算分离架构 。 该场景下原有平台的计算与存储直接淘汰 , 但由于存在历史数据 , 需要将原有的HDFS数据迁移到新的分离存储中 。
场景三:独立部署分离存储扩容HDFS
在实际数据湖建设项目中 , 更多是利旧场景 , 在新增独立分离存储外 , 将继续使用原有的计算平台 , 同时原有HDFS的存储空间与数据需要保留 , 以实现HDFS空间的整体扩容 。
杉岩数据MOSFS实现存算分离平滑落地
针对存在老HDFS数据的后两种场景 , 杉岩数据推出大数据存算分离场景的存储解决方案 , 可通过MOSFS支持的符号链接方式 , 实现对原有HDFS的纳管与数据自动迁移 , 使用提供的自动化工具通过特定步骤操作即可便捷地完成 。

文章图片
图 MOSFS纳管迁移HDFS实现存算分离
步骤一:执行初始化 , 实现MOSFS到HDFS映射通路
使用MOSFS迁移工具在HDFS的指定路径(比如/name目录)执行初始化命令 , 执行之后通过MOSFS的客户端访问mosfs://name/ , 就能完整访问HDFS对应/name目录里的内容 , 两者是完全等价的 。 在完成初始化操作之后 , MOSFS就具备了读写HDFS存储空间的能力 , 该过程原有数据流程没有更改 , 所以业务系统的运行完全无感 。

文章图片
步骤二:计算平台切换schema为mosfs
将fs.hdfs.impl的配置修改为MOSFS的实现 , 此修改实现上层计算组件访问存储的schema切换为mosfs:// 。 初始化已经完成了MOSFS到HDFS的通路建立 , 因此当完成配置修改并重启计算组件后 , 各个组件便可通过mosfs://的方式来读写原有HDFS存储的数据 。 该步骤的执行涉及到计算组件的重启 , 但是业务受影响的时间很短 。
步骤三:同步目录结构 , 实现读写分流
完成上一步骤后 , 业务的数据读写还在原有的HDFS中执行 , 再使用自动化工具执行目录同步 。 执行完成后 , MOSFS的命名空间中会按照HDFS中相同的拓扑结构创建所有目录及对应的文件 , 但文件依旧会以符号链接的方式映射到HDFS中的相同文件上 。 这时业务侧读数据时 , 依旧会通过符号链接方式直接读取原有HDFS存储中的对应文件 , 而写操作则会在MOSFS的存储空间中直接写入新的文件 。
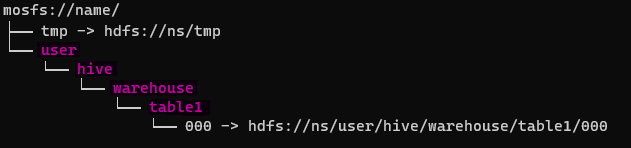
文章图片
此步骤在实现新老数据读写分流的同时 , 对业务层无影响 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。