文章图片
而我们从系统厂商浪潮信息上述的系统级创新不难判断 , 其不仅对于计算产业的发展趋势早有认知(例如率先推出采用GPU加速的AI服务器实例 , 并至今引领这一市场) , 且已经通过自身的系统级创新能力正在化解摆在业内面前、让新的计算架构真正落地所面临的挑战(如我们前述阻碍AI芯片充分发挥算力产生的产业链鸿沟) 。 而这也是中国系统厂商霸榜MLPerf?榜单背后的又一个重要原因 。
服务数字经济 , 智算时代迎挑战仍需更多
众所周知 , ICT产业的创新最终都是要为市场和用户服务 。 而在人工智能为代表的智算时代同样如此 。 我们前述AI计算系统创新的根本目的 , 最终还是要让算力、算法和数据去服务数字经济 , 去支撑科研创新 , 去推动智慧转型 , 这就需要加大以AI计算为核心的智能计算中心—这一新型人工智能基础设施建设 , 以此推动AI产业化、产业AI化和政府治理的智能化 。
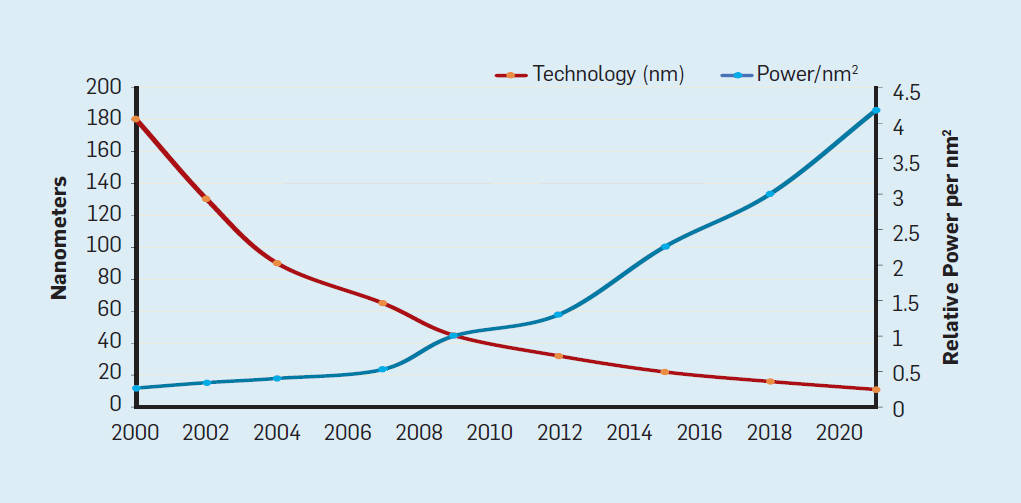
但随之而来的 , 面对智算中心建设所需大规模AI算力部署 , AI算力平台建设将面临高功耗、高电流密度、高总线速率、高系统复杂度的新挑战 。
对此 , 中国工程院院士、浪潮首席科学家王恩东认为 , 要想释放多元算力价值、促进人工智能创新 , 一是要重视智算系统的创新 , 加大人工智能新型基础设施建设 , 把从技术到应用的链条设计好 , 从体系结构、芯片设计、系统设计、系统软件、开发环境等各个领域形成既分工明确又协同创新的局面;二是要加快推动开放标准建设 , 通过统一的、规范的标准 , 将多元化算力转变为可调度的资源 , 让算力好用、易用 。
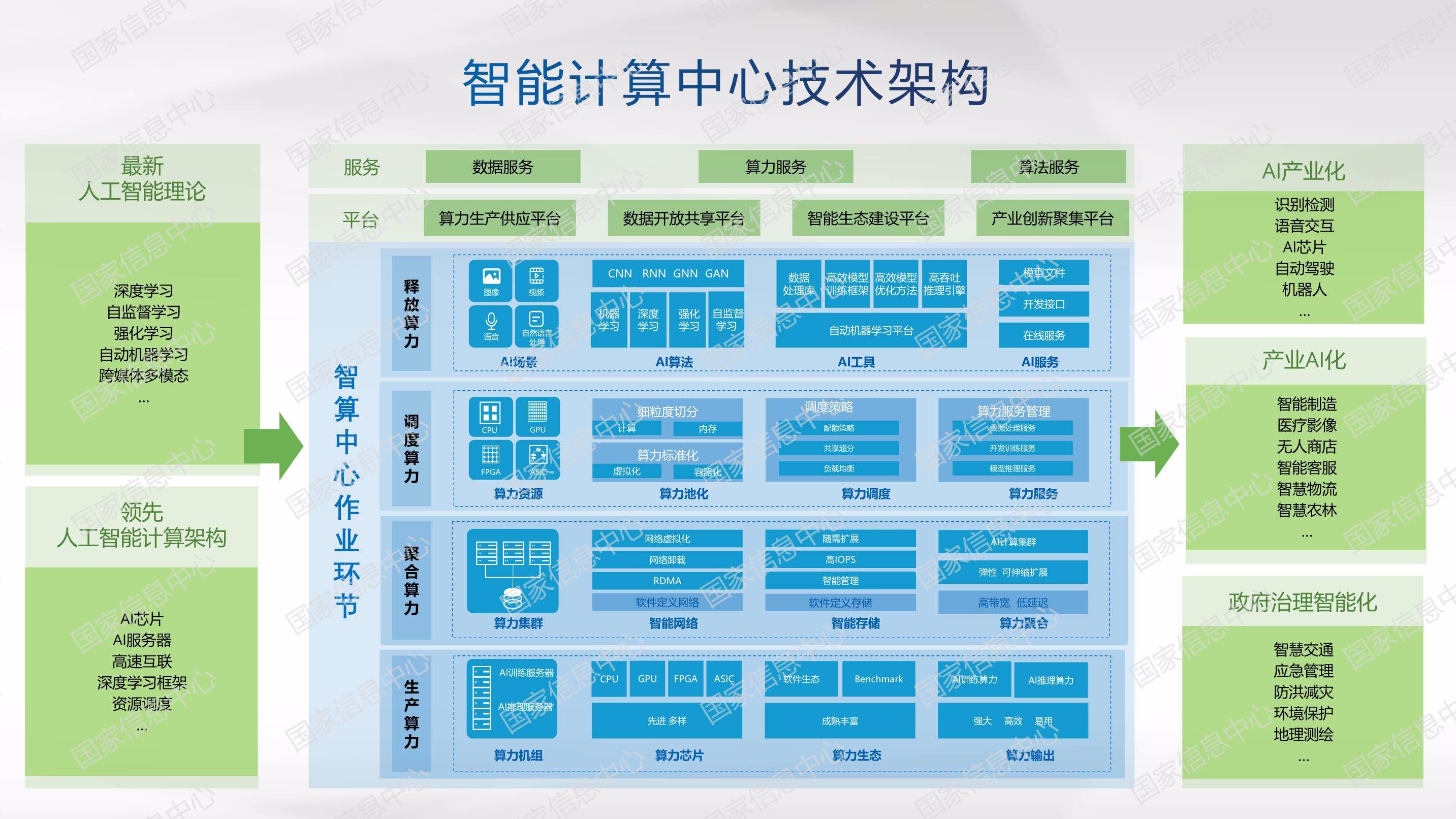
不知业内从王恩东院士的言论看到了什么?我们看到的是 , 系统级创新在智算中心的建设中依然是重中之重 , 毕竟AI计算是智算中心的核心 , 而AI服务器又是智算中心生产算力的“动力机组” , 是产出强大算力的源泉 。 而放置于智算系统(例如智算中心) , 系统创新又被赋予了更宽泛的内涵 , 即不仅应是算力的生产 , 还应包括聚合、调度和释放 , 同时需要产业链相关参与者在遵守统一、规范的标准之下 , 通力协作 , 各施所长 , 打造智算生态 。
实际的情况是 , 去年发布的《智能计算中心规划建设指南》已经就上述做了明确的说明 。 而系统厂商 , 无论是在算力的生产、聚合、调度和释放 , 还是在打造生态方面 , 已走在了业内的前列 。
文章图片
以浪潮信息为例 , 除了我们前述的在算力生产层面的系统级创新外 , 在算力调度层面 , 浪潮AIStation人工智能开发平台能够为AI模型开发训练与推理部署提供从底层资源到上层业务的全平台全流程管理支持 , 帮助企业提升资源使用率与开发效率90%以上 , 加快AI开发应用创新(解决了算力的效率问题);在聚合算力方面 , 浪潮持续打造更高效率更低延迟硬件加速设备与优化软件栈;在算力释放上 , 浪潮AutoML Suite为人工智能客户与开发者提供快速高效开发AI模型的能力 , 开启AI全自动建模新方式 , 加速产业化应用 。
总结:综上 , 我们看到 , 系统厂商在MLPerf?中能取得优异成绩的能力 , 是建立在其对市场及客户应用场景的理解之上 , 而其在产品研发、客户需求、实际应用中所获得的洞察和理解 , 又指导着MLPerf?测试 , 是其能够取得优异成绩的一个重要原因 。 与此同时 , 系统厂商在MLPerf?测试中的探索和创新也反过来帮助其更好地回馈产业客户的实际应用 , 以此形成一种良性的循环 。 而这种良性循环 , 在保持系统厂商持续领先的同时 , 更重要的是会加速AI产业化和产业AI化的落地 。 而在智算中心到来的时代 , 这种能力和良性循环又会被放大 , 进而促进中国数字经济的发展 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。