训练 IMDB 采用 blurr 库 , 该库将 fast.ai 和 Hugging Face Transformers 集成在一起 。 除了向 fast.ai 添加 Transformers 训练和推理支持外 , blurr 还集成了每 batch token 化和 fast.ai 文本数据加载器 , 后者根据序列长度对数据集进行随机排序 , 以最大限度地减少训练时的填充(padding) 。
XSE-ResNet50 和 RoBERTa 采用单精度和混合精度训练的方式。 XSE-ResNet50 训练图像大小为 224 像素 , 混合精度 batch 大小为 64 , 单精度 batch 大小为为 32 。 RoBERTa 混合精度 batch 大小为 16 , 单精度 batch 大小为 8 。
为了探索 CPU 使用极限 , 我还训练了一个 XResNet18 模型 , 图像大小为 128 像素 , batch 大小为 64 。
blurr 地址:https://ohmeow.github.io/blurr/
结果
当进行混合精度训练时 , SageMaker Studio Lab 的 Tesla T4 优于 Google Colab 的 Tesla P100 , 但在训练全单精度模型时表现稍差 。
XSE-ResNet50
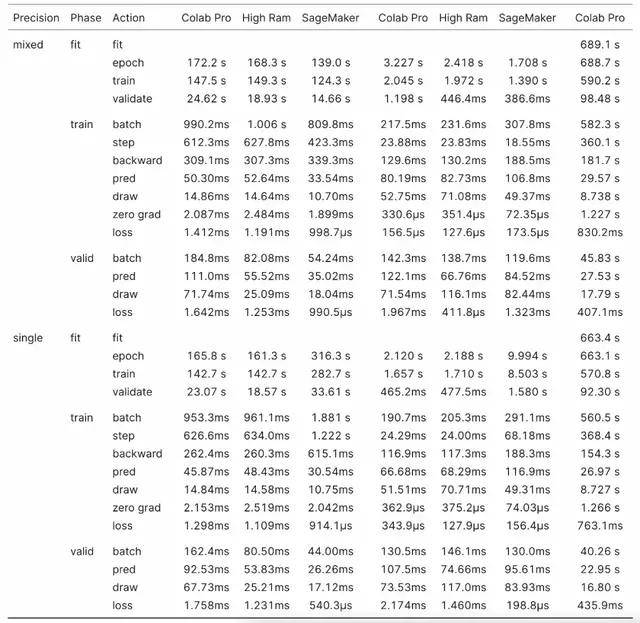
在相似的设置下 , Colab Pro High RAM 和 SageMaker 比较 , XSE-ResNet50 在 SageMaker 上的总体训练速度提高了 17.4% 。 仅查看训练循环(training loop)时 , SageMaker 比 Colab Pro 快 19.6% 。 SageMaker 在所有操作中都更快 , 但有一个明显的例外:在向后传递中 , SageMaker 比 Colab Pro 慢 10.4% 。
当以单精度训练 XSE-ResNet50 时 , 结果相反 , SageMaker 的执行速度比 Colab Pro High RAM 慢 95.9% ,训练循环比 Colab Pro 慢 93.8% 。
文章图片
XSE-ResNet50 Imagenette 简单分析器结果
RoBERTa
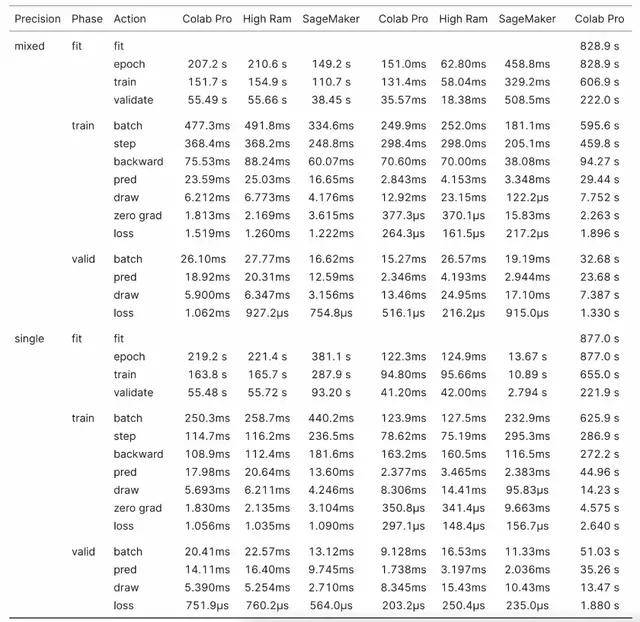
混合精度训练 RoBERTa ,SageMaker 进一步领先 Colab Pro , 执行速度提高了 29.1% 。 SageMaker 在训练循环期间比 Colab Pro 快 32.1% , 并且在所有操作中 SageMaker 都更快 , 除了在计算损失时 , SageMaker 比 Colab Pro 慢 66.7% 。
在单精度下 , SageMaker 训练的结果再次翻转 , 总体上 SageMaker 比 Colab Pro 慢 72.2% 。 训练循环比 Colab Pro 慢 67.9% 。 当以单精度训练 XSE-ResNet50 时 , 由于向后传递和优化器步骤 , SageMaker 比 Colab Pro 慢了 83.0% , 而 SageMaker 执行所有其他操作的速度快了 27.7% 。
奇怪的是 , Colab Pro High RAM 实例的训练速度比普通 Colab Pro 实例慢 , 尽管前者有更多的 CPU 核和 CPU RAM 以及相同的 GPU 。 然而 , 它们之间的差异并不大 。
文章图片
表 3:RoBERTa 基准结果
XResNet18
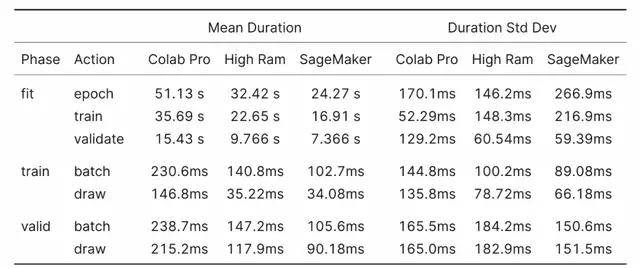
对于 XResNet18 基准测试 , 了解绘制动作测量内容很关键 。 XResNet18 基准测试是从数据加载器绘制 batch 之前到开始 batch 操作之间的时间 。 数据加载器的 prefetch_factor 设置为默认值 2 , 这意味着研究者尝试在训练循环调用它们之前提前加载两个 batch 。 其中包括前向和后向传递、损失和优化器 step 和零梯度操作 。
绘制动作越低 , 实例 CPU 就越能满足需求 。
这里的结果符合预期 , 更多的 CPU 核意味着更少的绘制时间 , 并且在相同的核数下 , 较新的 CPU 的性能优于较旧的 CPU 。
文章图片
表 4:XResNet18 基准结果
Colab Tesla K80
由于免费 Colab 实例的 Tesla K80 的 RAM 比其他 GPU 少四分之一 , 因此我将混合精度 batch 大小也减少了四分之一 。 此外 , 我没有运行任何单精度测试 。
我运行了两个 epoch 的 Imagenette 基准测试 , 并将 IMDB 数据集从 20% 的样本减少到 10% 的样本 , 并将训练长度减少到一个 epoch 。
Colab K80 在半数 Imagenette epoch 上进行训练花费的时间大约是 Colab Pro 实例的两倍 。 与 Colab P100 相比 , 在 Colab K80 上进行等效的 IMDB 训练时间要长 3 倍 。 如果可能的话 , 应避免使用 K80 对除小型模型以外的任何其他模型进行训练 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。