文章图片
模型
基准
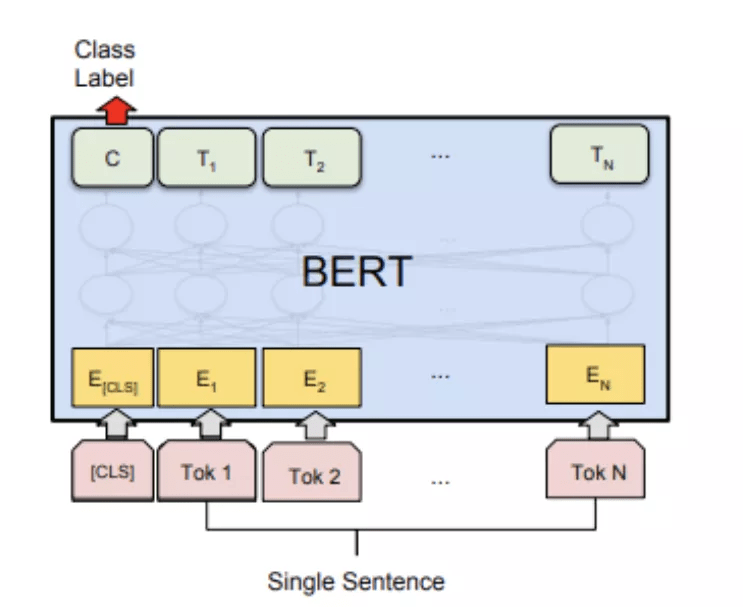
实体类型推断任务 , 本质上是一个文本的多分类任务 , 因此在模型的选择上 , 采用了预训练模型 + finetune 的方式作为基准(baseline) 。
文章图片
特征选择
需要分类的实体 , 本身包含名称、正文内容、多个属性对和关键词等特征 。 为了挑选出最佳的特征组合 , 阿里安全进行多组对照试验 , 最终得出结论:输入为「实体名 + 数据源 + 摘要 + 属性名 + 关键词」效果最好 。
预训练模型
阿里安全尝试了多种预训练模型 , 其中 Roberta-large 效果最好 。
层级损失
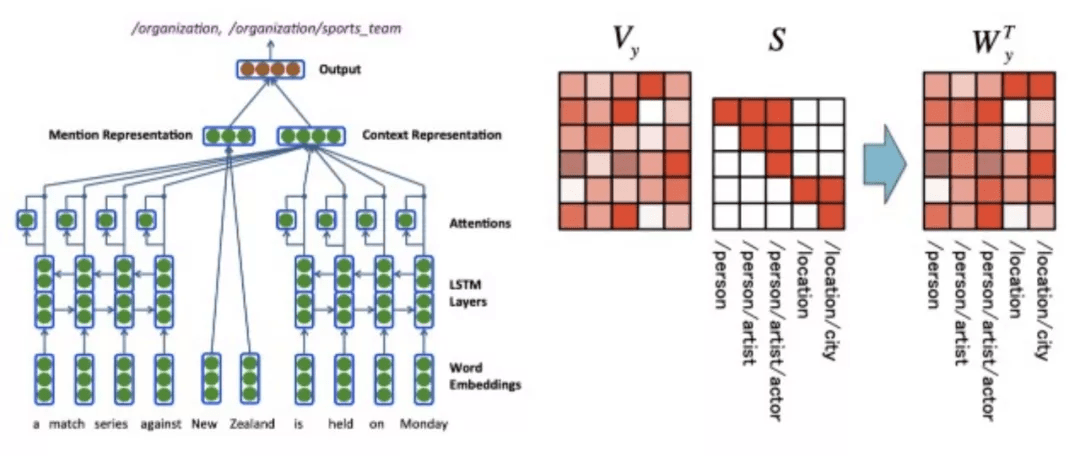
越细粒度的类别 , 父子标签所占的比重应该是不一样的 。 例如 , 如果选择了子标签 , 那么较粗的粒度肯定要选择父标签 , 而传统的损失函数在优化时 , 就是将它们平等对待的 。 因此 , 引入了层次分类最常用的几种损失 , 有效地解决了上述问题 , 并选用层级损失(Hierarchy loss)作为最终方案 。
文章图片
层级标签示意图
模型数据相互迭代优化方案
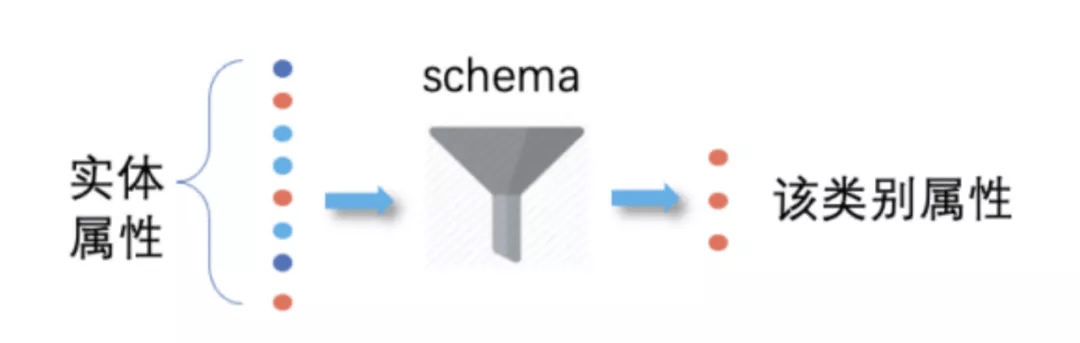
该方案类似于强化学习的思想 , 模型和数据相互正向优化 , 直至收敛 。 以游戏为例 , 通常会出现游戏类型这样的 schema 字段 , 反之 , 若一个实体若出现游戏类型 , 则大概率是游戏 。 类似游戏类型这样的 schema 或 keyword , 称之为「必杀」特征 。 这种方式类似漏斗 , 可以通过必杀属性 , 进而过滤出具体类别的实体 , 如下图所示:
文章图片
必杀属性示意图
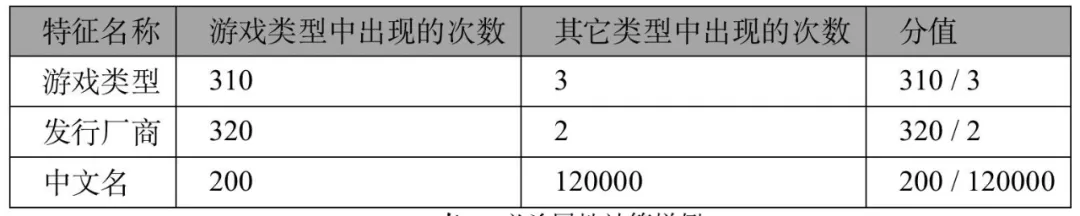
基于第一部分生成的 train , 构建了一套自动生成「必杀」特征的逻辑 , 如下(1)对所有标签为游戏的数据进行统计 , 生成如下统计结果:
- 游戏类型 310 次
- 发行厂商 320 次
- 中文名 2000 次
文章图片
必杀属性计算样例
利用分值大于 6 的「必杀」特征 , 重新打标数据 。 除了「必杀」属性之外 , 阿里安全基于「模式匹配法」统计相同属性出现的频率 。 一方面 , 可以过滤掉低频属性 , 另一方面 , 基于假设:待验证实体的属性与 M 类属性共现的次数远远大于 N 类属性共现次数 , 可以判断该实体属于 M 类 。 用这种方法纠正了错误实体分类 , 如下图所示:
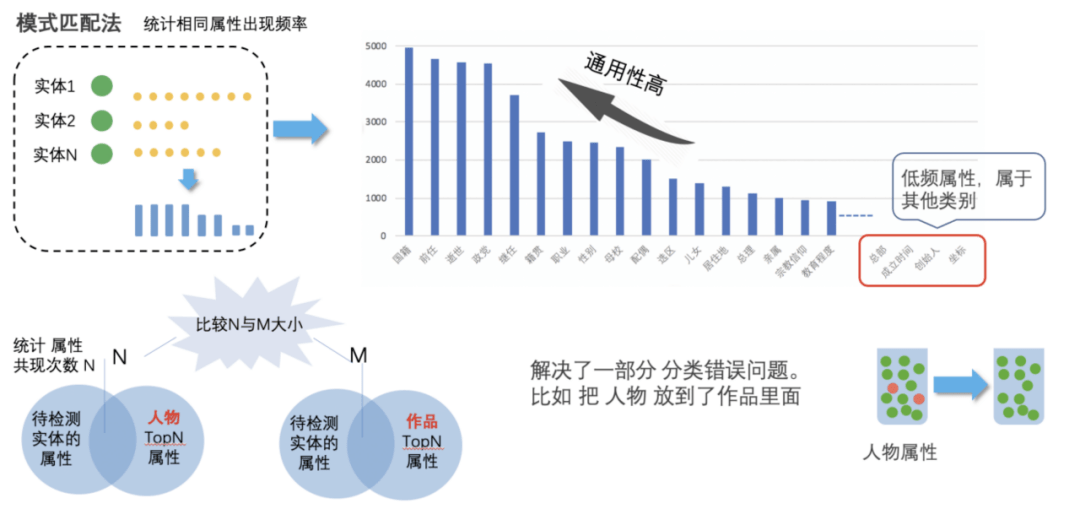
文章图片
整体迭代的过程如下:
文章图片
模式匹配法示意图
应用场景
【筛选风险词、用实体类型推断限售商品,阿里安全夺冠知识图谱大赛】违规商品检测
各电商平台上每天都会出现各种各样的新产品 , 当面对新型商品时 , 如何判断其是否属于违规的商品类型则成为了一个非常重要的事情 。 当出现以一个新的商品种类的时候 , 实体类型推断模块可以借助商品的描述信息 , 对此品类的商品进行类型推断 , 从而自动发现一些新的禁限售商品 , 从而提升违规商品的防控水位 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。