
文章图片
此外 , 研究者还发现监督训练的目标特征会产生较差的结果 , 这可能与存在于特征中的类级特定信息有关 , 即这种方法对于局部掩码建模来说过于全局化 。 总的来说 , 考虑性能和计算成本之间的权衡 , 该研究最终选择了 HOG 作为 MaskFeat 的默认特征 。
方向梯度直方图(HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述方法 , 最早是在 CVPR 2005 的一篇论文《Histograms of Oriented Gradients for Human Detection》中提出的 。

文章图片
HOG 特征提取的过程如下:首先把样本图像分割为若干个像素单元 , 把梯度方向平均划分为多个区间 , 在每个单元里面对所有像素的梯度方向在各个方向区间进行直方图统计 , 得到一个多维的特征向量 , 每相邻的单元构成一个区间 , 把一个区间内的特征向量联起来得到多维的特征向量 , 用区间对样本图像进行扫描 , 扫描步长为一个单元 。 最后将所有块的特征串联起来 , 就得到了完整的特征 。
基于视频识别的实验
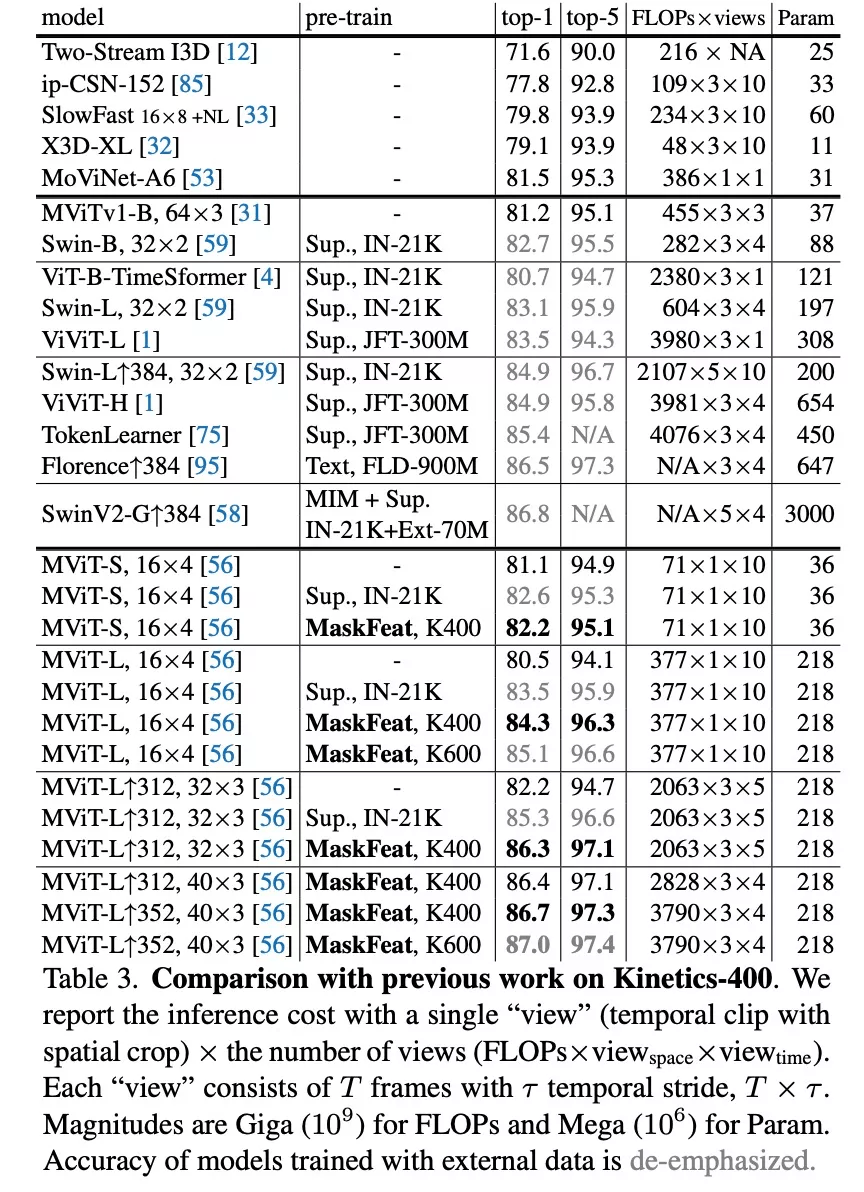
该研究在 K400 数据集上将 MaskFeat 和之前的工作进行了比较 , 结果如下表 3 所示 , 使用 MaskFeat 的 MViT-L 在 Kinetics-400 上实现了新的 SOTA——86.7% top-1 准确率 。
文章图片
迁移学习
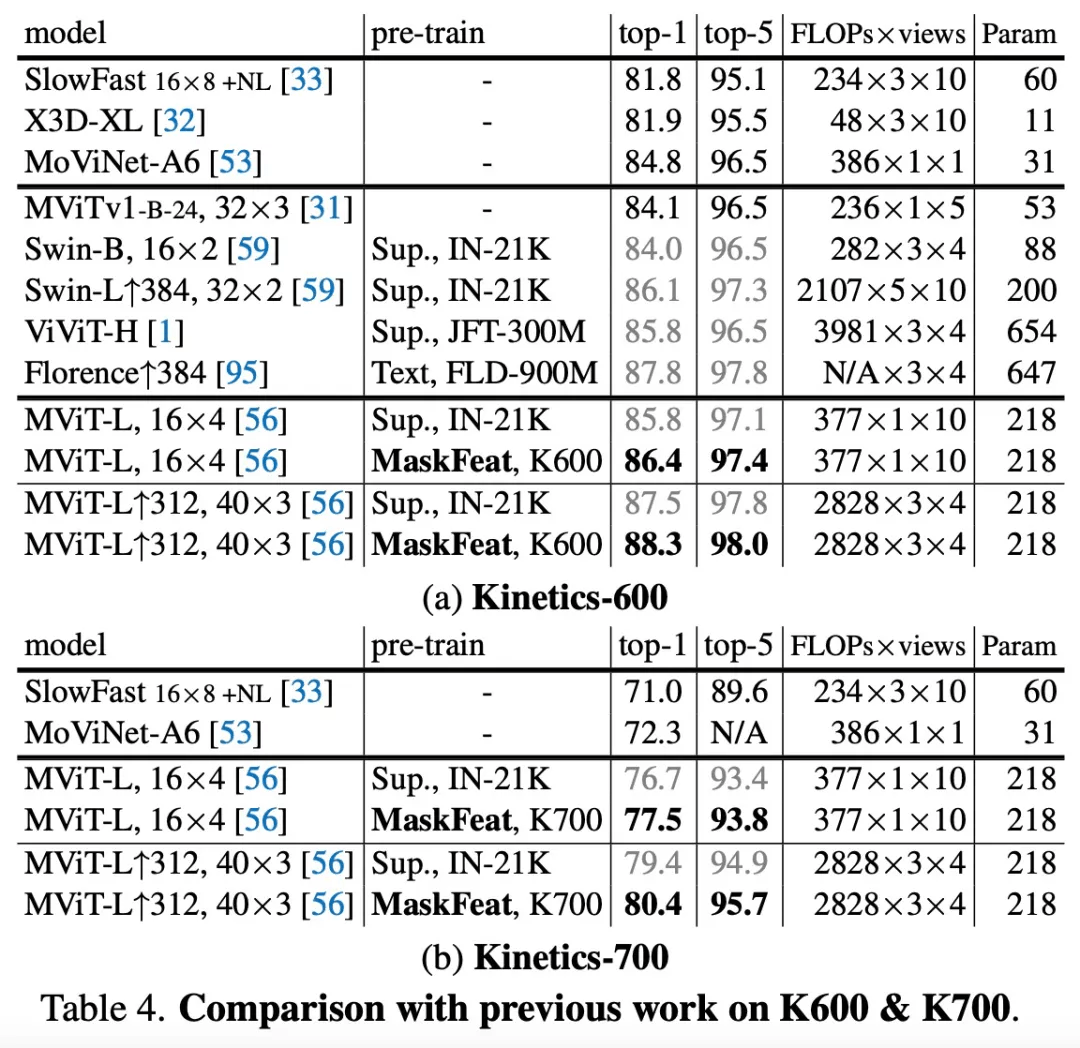
为了评估该方法在下游任务上的迁移学习性能 , 该研究在 AVA v2.2 上微调了 MViT-L↑312,40×3 Kinetics 模型 , 实验结果如上表 3 和下表 4 所示 , 在 K600 上实现了 88.3% top-1 准确率 , K700 上为 80.4% , 均实现了新的 SOTA 。
文章图片
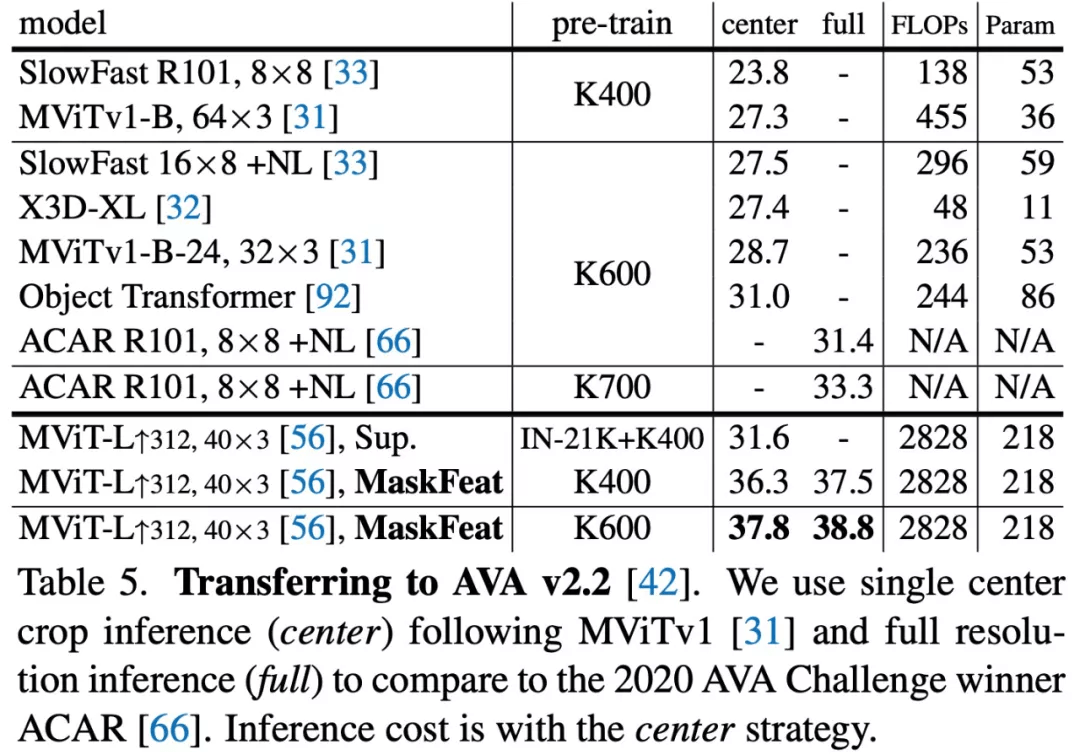
该研究在 AVA v2.2 上微调了 MViT-L↑312,40×3 Kinetics 模型 , 下表 5 给出了 MaskFeat 模型与现有方法相比的平均精度 (mAP) 。 MaskFeat 在全分辨率测试中达到了前所未有的 38.8 mAP , 大大超过了以前所有方法 。
文章图片
感兴趣的读者可以阅读论文原文了解更多研究细节 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。