文章图片
随着大规模 GAN 的发展 , 领域内又涌现出一系列新型生成网络 , 如 BigGAN [19] 和 StyleGAN [20]-[22] , 以从随机噪声输入中合成高质量且具有多样性的图像 。
最近有研究表明 , GAN 可以在中间特征 [23] 和潜在空间 [24] 中有效地编码丰富的语义信息 。 GAN 反转 [25] 的方法将给定图像反转回预训练 GAN 模型的潜在空间 , 产生可由生成器重建给定图像的反转代码 , 这种方法取代了通过改变潜在代码来合成图像 。 由于 GAN 反转能够控制在潜在空间中发现的属性方向 , 因此预训练 GAN 可应用于真实图像编辑 , 而无需临时监督或昂贵的优化 。
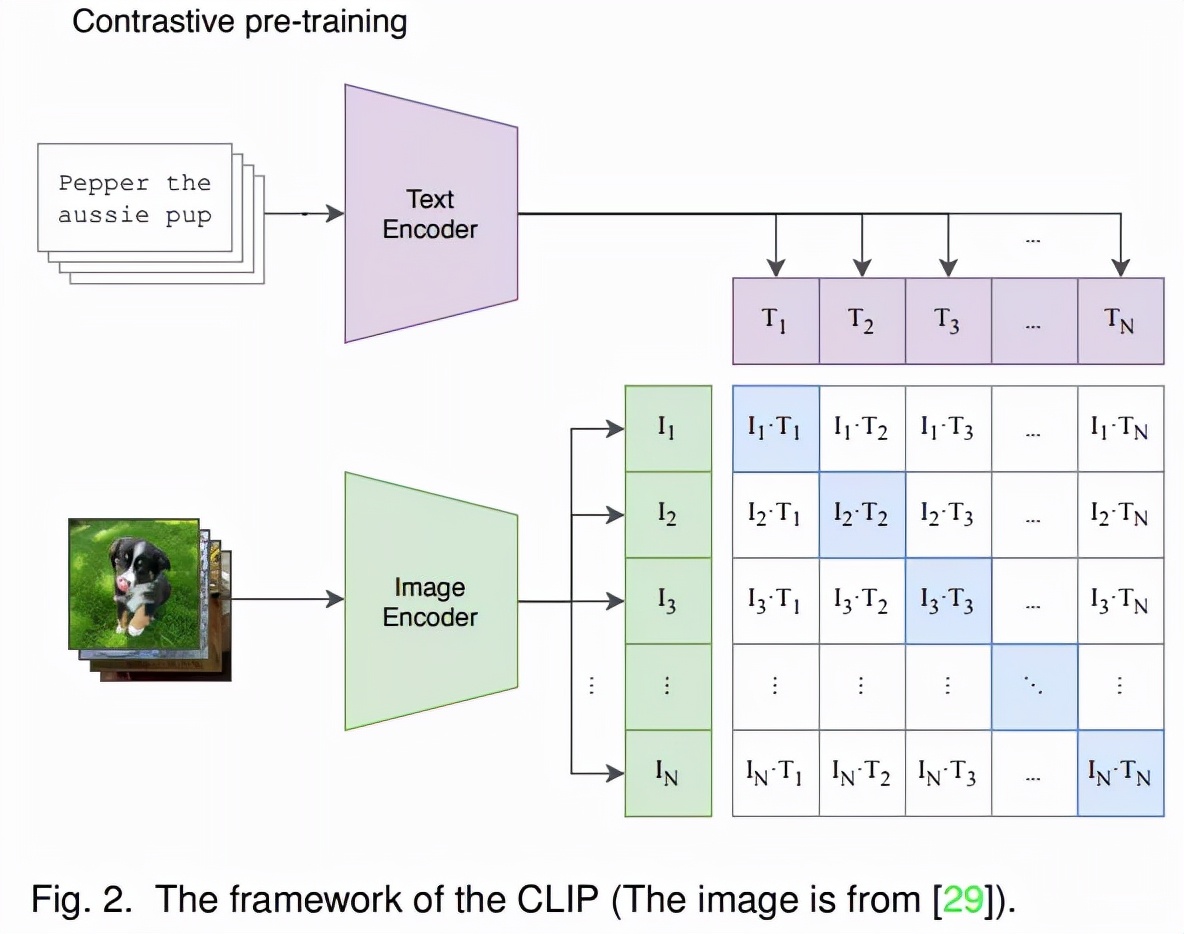
许多研究 [26][27] 都试图沿着一个特定方向改变真实图像的反转码来编辑图像的相应属性 。 在多模态指导方面 , StyleClip [28] 利用 CLIP [29] 模型的强大功能为 StyleGAN 图像处理开发了基于文本的接口 , 而无需繁琐的手动操作 。 Talk-to-Edit [30] 则提出一种交互式人脸编辑框架 , 通过操作者与机器之间的对话就能进行细粒度的操作和编辑 。
文章图片
随着允许跨模态输入的 Transformer 模型 [31] 的流行 , 语言模型 [32]、图像生成预训练 [33] 和音频生成 [34] 等多个领域都取得了显著的进步 。 Transformer 为多模态图像合成提供了一条可能的新途径 。
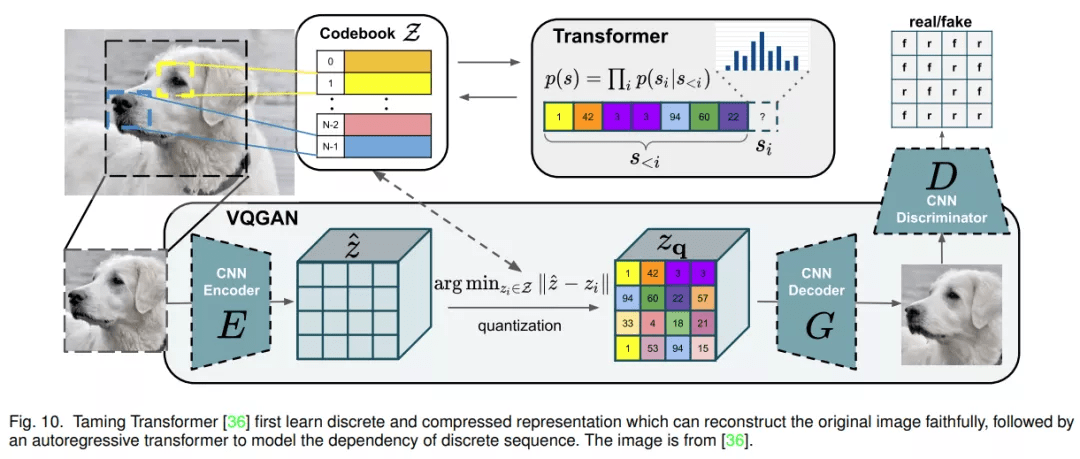
具体而言 , DALL-E [35] 表明 , 在众多图像 - 文本对上训练大规模自回归 transformer 可以通过文本 prompt 产生具有可控结果的高保真生成模型 。 Taming Transformer [36] 提出用带有鉴别器和感知损失 [37]-[39] 的 VQGAN 来学习离散图像表征 , 并证明了在高分辨率图像合成中将 CNN 的归纳偏置与 transformer 的表达能力相结合的有效性 。
文章图片
ImageBART [40] 通过学习反转多项式扩散过程来解决自回归 (AR) 图像合成问题 , 该方法通过引入语境信息来减轻 AR 模型的曝光误差(exposure bias) 。 前段时间的 NUWA [41] 提出了一种统一的多模态预训练模型 , 允许使用 3D transformer 编码器 - 解码器框架和 3DNA 机制生成或操作视觉数据(即图像和视频) 。
随着生成模型和神经渲染的发展 , 还有一些研究探索了其他类型的模型 , 例如神经辐射场 (NeRF) [42] 和扩散模型 [43][44] , 以实现多模态图像合成和编辑 。
论文的主要部分包括第 2 章 - 第 5 章的内容:
- 第 2 章介绍了图像合成和编辑中流行的指导模态的基础;
- 第 3 章全面概述了具有详细 pipeline 的多模态图像合成和编辑方法;
- 第 4 章介绍了流行的数据集、评估指标和一些典型方法的定量实验结果;
- 第 5 章讨论了多模态图像合成和编辑面临的主要挑战和未来方向 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。