机器之心报道
机器之心编辑部
今年多模态图像合成与编辑方向大火 , 前有 DALL-E、GauGAN2 , 后有统一的多模态预训练模型「女娲」 。 来自新加坡南洋理工大学的研究者对这一领域内的进展和趋势做了系统的调查梳理 。现实世界中的信息存在于各种模态之中 , 多模态信息之间的有效交互和融合对于计算机视觉和深度学习研究中多模态数据的创建和感知起着关键作用 。 凭借在多模态信息交互建模方面的强大能力 , 多模态图像合成和编辑已成为近年来的热门研究课题 。
与提供显式线索的传统视觉指导不同 , 多模态指导为图像合成和编辑提供了直观、灵活的手段 。 另一方面 , 该领域在特征与固有模态差距的对齐、高分辨率图像合成、公平评估指标等方面也面临着挑战 。
基于此 , 来自新加坡南洋理工大学的研究者做了一项调查 , 全面地将近来多模态图像合成和编辑的进展背景化 , 根据数据模态和模型架构制定分类法 , 并撰写了一篇综述论文 。

文章图片
- 论文地址:https://arxiv.org/pdf/2112.13592.pdf
- 项目地址:https://github.com/fnzhan/MISE
文章图片
论文内容概览
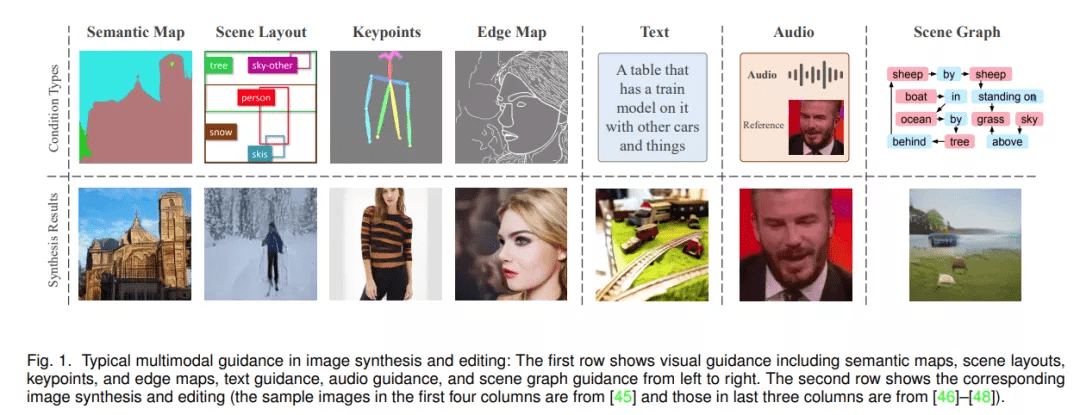
图像合成和编辑旨在创建逼真图像或编辑具有自然纹理的真实图像 , 近年来大多基于生成对抗网络(GAN)[1] 。 为了实现更可控的生成 , 一个主流研究方向旨在根据一定的指导条件生成和编辑图像 。 通常 , 分割图和图像边缘等视觉线索已被广泛采用 , 以实现卓越的图像合成和编辑性能 。 除了这些视觉线索之外 , 文本、音频和场景图等跨模态指导提供了一种更直观、更灵活的视觉概念表达方式 。 然而 , 从不同模态的数据中有效检索和融合异构信息仍是图像生成和编辑的巨大挑战 。
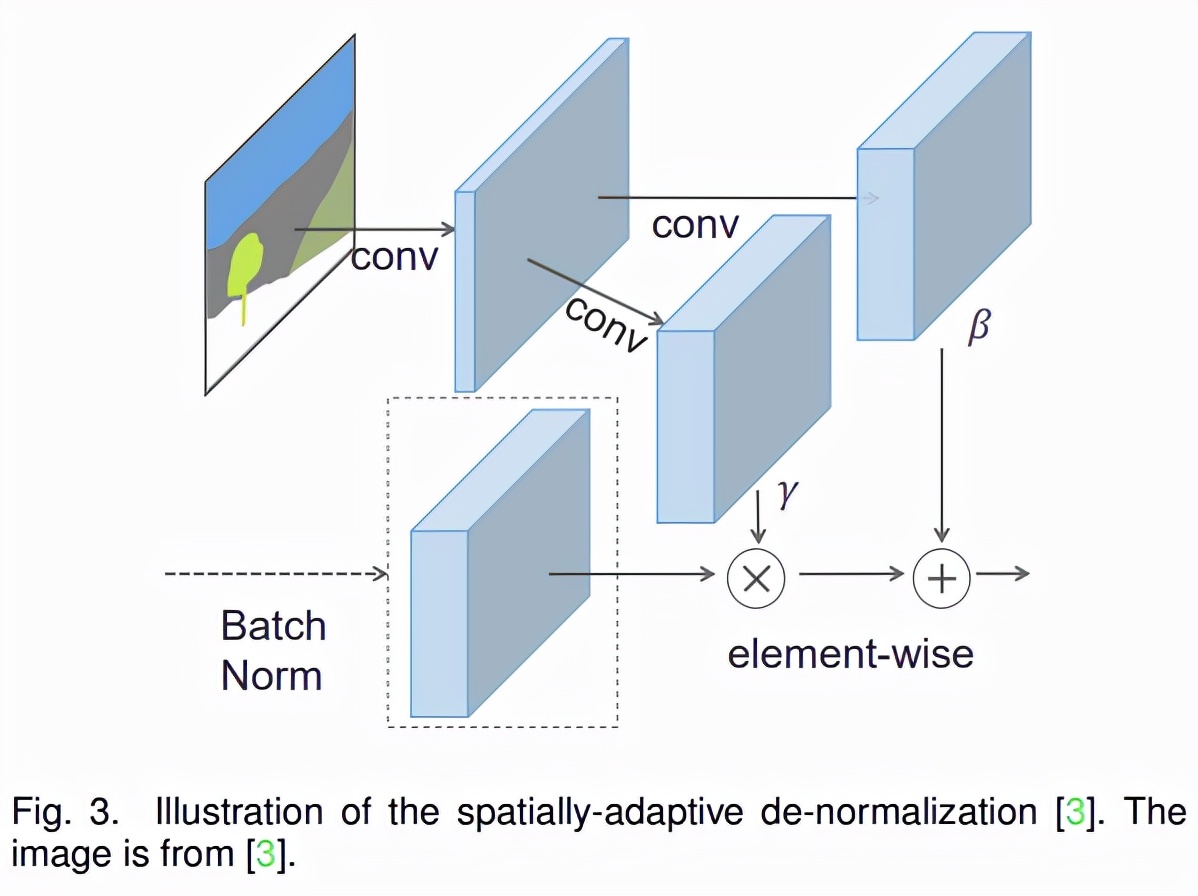
【DALL-E、「女娲」刷屏背后,多模态图像合成与编辑领域进展如何?】作为多模态图像合成领域的一项先驱工作 , E. Mansimov 等人 (2015)[5] 的工作表明循环变分自动编码器可以生成以文本为条件的新型视觉场景 。 随着生成对抗网络 I. Goodfellow 等人 (2014)[1]、P. Isola 等人(2017)[2]、 T. Park 等人(2019)[3]、 M. Mirza 等人(2014)[6]、 M. Arjovsky 等人(2017)[7]、 C.-H. Lin 等人(2018)[8] 等多项研究的发展 , 多模态图像合成的工作得到了极大的推进 。
文章图片
S. Reed 等人 2016 年的论文《Generative adversarial text to image synthesis》[11]扩展了条件 GAN [6], 以基于文本描述生成自然图像 。L. Chen 等人 2017 年的论文《Deep cross-modal audio-visual generation》[12] 用条件 GAN 实现音乐表演的跨模态视听生成 。 然而 , 这两项先驱研究仅能对图像分辨率相对较低(例如 64 × 64)的有限数据集(例如 CUB-200 Birds [13] 和 Sub-URMP [12])进行合成 。 在过去几年中 , 改进的多模态编码 [14][15]、新型架构[16][17] 和循环结构[18] 使得该领域取得了显著的进步 。 另一方面 , 早期的研究主要集中在多模态图像合成上 , 很少关注多模态图像编辑任务 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。