「为了加速训练 , 我们用到了非饱和神经元和一个非常高效的 GPU 卷积操作实现 。 」
事实证明 , AlexNet 作者花了相当多的时间将耗时的卷积操作映射到 GPU 上 。 与标准处理器相比 , GPU 能够更快地执行特定任务 , 如计算机图形和基于线性代数的计算(CNN 包含大量的此类计算) 。 高效的 GPU 实现可以帮他们缩短训练时间 。 他们还详细说明了如何将他们的网络映射到多个 GPU , 从而能够部署更深、更宽的网络 , 并以更快的速度进行训练 。
拿 AlexNet 作为一个研究案例 , 我们可以找到一个回答开篇问题的线索:尽管算法方面的进展很重要 , 但使用专门的 GPU 硬件使我们能够在合理的时间内学习更复杂的关系(网络更深、更大 = 用于预测的变量更多) , 从而提高了整个网络的准确率 。 如果没有能在合理的时间框架内处理所有数据的计算能力 , 我们就不会看到深度学习应用的广泛采用 。
如果我是一名 AI 从业者 , 我需要关心处理器吗?
作为一名 AI 从业者 , 你希望专注于探索新的模型和想法 , 而不希望过多担心看起来不相关的问题 , 如硬件的运行方式 。 因此 , 虽然理想的答案是「不 , 你不需要了解处理器」 , 但实际的答案是「可能还是要了解一下」 。 如果你非常熟悉底层硬件以及如何调试性能 , 那么你的推理和训练时间就会发生变化 , 你会对此感到惊讶 。
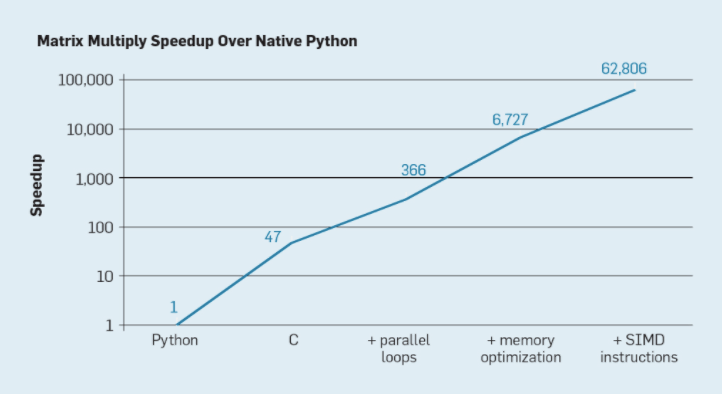
文章图片
各种并行化技术对于矩阵乘法的加速效果 。
如果不懂硬件 , 你所花的时间可能会多 2-3 倍 , 有时甚至多一个数量级 。 简单地改变做矩阵乘法的方式可能帮你收获巨大的性能提升(或损失) 。 性能欠佳可能会影响你的生产力以及你可以处理的数据量 , 并最终扼杀你的 AI 周期 。 对于一家大规模开展人工智能业务的企业来说 , 这相当于损失了数百万美元 。
那么 , 为什么不能保证得到最佳性能呢?因为我们还没有有效地达到合理的「user-to-hardware expressiveness」 。 我们有一些有效利用硬件的用例 , 但还没泛化到「开箱即用」的程度 。 这里的「开箱即用」指的是在你写出一个全新的 AI 模型之后 , 你无需手动调整编译器或软件堆栈就能充分利用你的硬件 。

文章图片
AI User-to-Hardware Expressiveness 。
上图说明了「user-to-hardware expressiveness」的主要挑战 。 我们需要准确地描述用户需求 , 并将其转换成硬件层(处理器、GPU、内存、网络等)能够理解的语言 。 这里的主要问题是 , 虽然左箭头(programming frameworks)主要是面向用户的 , 但将编程代码转换为机器码的右箭头却不是 。 因此 , 我们需要依靠智能的编译器、库和解释器来无缝地将你的高级代码转换为机器表示 。
这种语义鸿沟难以弥合的原因有两个:
1)硬件中有丰富的方法来表达复杂的计算 。 你需要知道可用的处理元素的数量(如 GPU 处理核心)、你的程序需要的内存数量、你的程序所展示的内存访问模式和数据重用类型 , 以及计算图中不同部分之间的关系 。 以上任何一种都可能以意想不到的方式对系统的不同部分造成压力 。 为了克服这个问题 , 我们需要了解硬件 / 软件堆栈的所有不同层是如何交互的 。 虽然你可以在许多常见的场景中获得良好的性能 , 但现实中还有无尽的长尾场景 , 你的模型在这些场景中可能表现极差 。
2)虽然在计算世界中 , 软件是慢的 , 硬件是快的 , 但部署世界却在以相反的方式运行:深度学习领域正在迅速变化;每天都有新的想法和软件更新发布 , 但构建、设计和试生产(流片)高端处理器需要一年多的时间 。 在此期间 , 目标软件可能已经发生了显著的变化 , 所以我们可能会发现处理器工程师一年前的新想法和设计假设已经过时 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。