文章图片
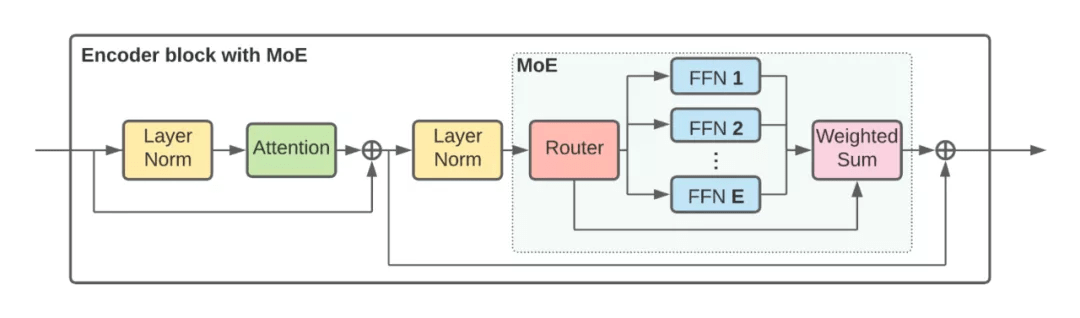
V-MoE Transformer 编码器块
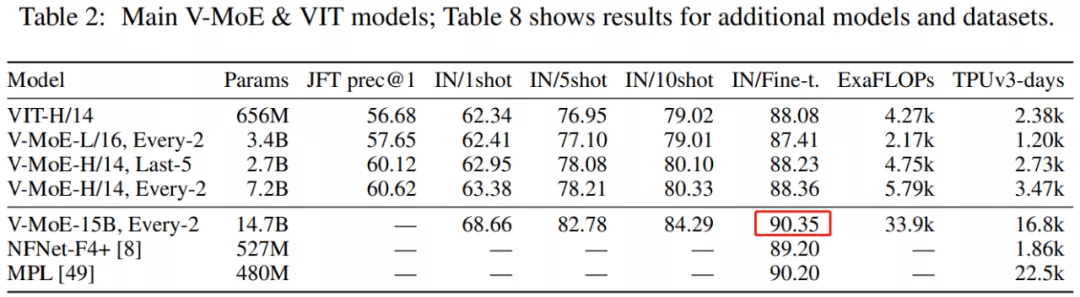
实验结果
谷歌大脑首先在大型图像数据集 JFT-300M 上对模型进行一次预训练 。
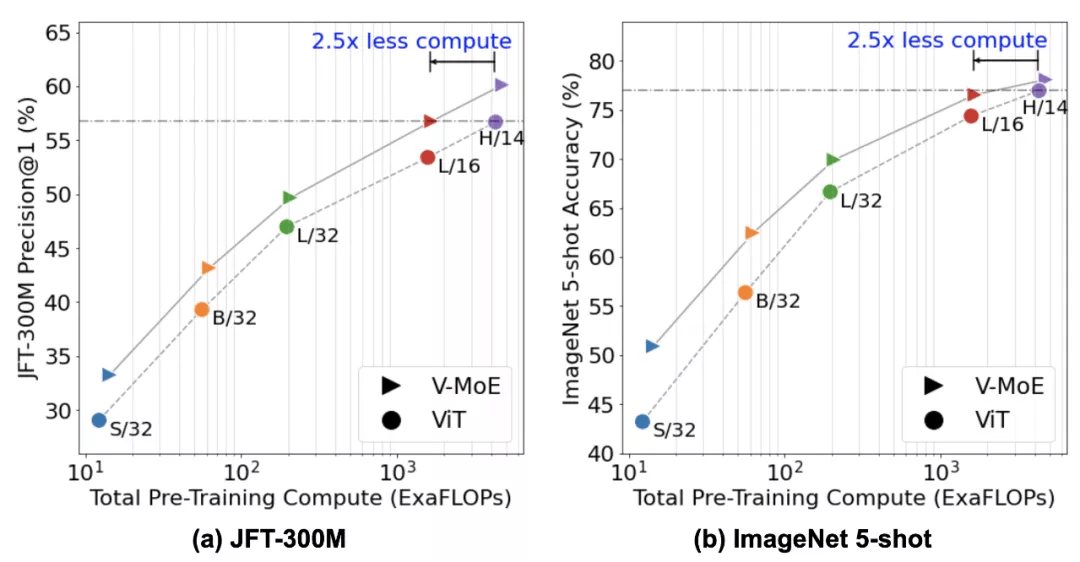
下图左展示了模型在所有大小(从 small s/32 到 huge H/14)时的预训练结果 。 然后 , 使用一个新的 head(一个模型中的最后一层)将模型迁移至新的下游任务(如 ImageNet) 。 他们探索了两种迁移设置:在所有可用的新任务示例上微调整个模型或者冻结预训练网络并使用少量示例仅对新 head 调整(即所谓的小样本迁移) 。
下图右总结了模型迁移至 ImageNet 的效果 , 其中每个图像类别仅在 5 张图像上训练(叫做 5-shot transfer) 。
文章图片
左为 JFT-300M 数据集上的 Precision@1 曲线图;右为 ImageNet 5-shot 的准确率曲线图 。
对于这两种情况 , 谷歌大脑发现 , 在给定训练计算量时 , 稀疏模型显著优于密集模型或者更快地实现相似性能 。 为了探索视觉模型的极限 , 他们在 JFT-300M 扩展数据集上训练了一个具有 150 亿参数、24 个 MoE 层(出自 48 个块)的模型 。 这个迄今为止最大的视觉模型在 ImageNet 上实现了 90.35 的 Top-1 准确率 。
文章图片
优先路由
在实践中 , 由于硬件限制 , 使用动态大小的缓冲区(buffer)效率不高 , 因此模型通常为每个专家使用预定义的缓冲区容量 。 一旦专家变「满」 , 超出此容量的分配 token 将被丢弃并不会被处理 。 因此 , 更高的容量会产生更高的准确性 , 但它们的计算成本也更高 。
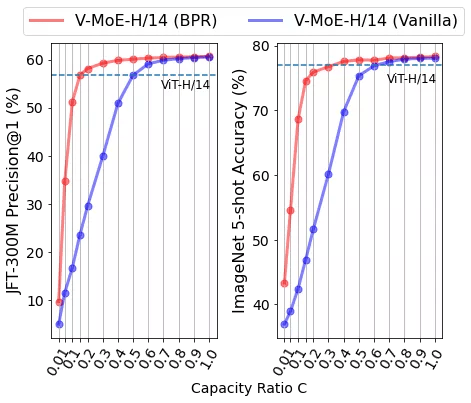
谷歌大脑利用这种实现约束来使 V-MoE 在推理时更快 。 通过将总组合缓冲区容量降低到要处理的 token 数量以下 , 网络被迫跳过处理专家层中的一些 token 。 该模型不是以某种任意方式选择要跳过的 token(就像以前的工作那样) , 而是学习根据重要性分数对它们进行排序 。 这样可以保持高质量的预测 , 同时节省大量计算 。 他们将这种方法称为批量优先级路由(Batch Priority Routing, BPR), 动态示意图如下所示:

文章图片
在高容量下 , Vanilla 和优先路由都可以很好地处理所有 patch 。 但是 , 当减小缓冲区大小以节省计算时 , Vanilla 路由选择处理任意 patch , 通常导致预测不佳;BPR 智能地优先选择处理重要 patch , 使得以更低的计算成本获得更佳的预测 。
事实证明 , 适当地删除 token 对于提供高质量和更有效的推理预测至关重要 。 当专家容量减少时 , Vanilla 路由机制的性能会迅速下降 。 相反 , BPR 对低容量更为稳健 。
文章图片
总体而言 , 谷歌大脑观察发现 , V-MoE 在推理时非常灵活:例如 , 可以减少每个 token 选择的专家数量以节省时间和计算 , 而无需对模型权重进行任何进一步的训练 。
探索 V-MoE
由于关于稀疏网络的内部工作原理还有很多待发现 , 谷歌大脑还探索了 V-MoE 的路由模式 。 一种假设是 , 路由器会根据某些语义背景(如「汽车」专家、「动物」专家等)学会区分并分配 token 给专家 。
为了测试这一点 , 他们在下面展示了两个不同 MoE 层的图 , 一个非常早期(very early-on) , 另一个更靠近 head 。 x 轴对应 32 个专家中的每一个 , y 轴显示图像类别的 ID(从 1 到 1000) 。 图中每个条目都显示了为与特定图像类对应的 token 选择专家的频率 , 颜色越深表示频率越高 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。