选自 Google AI
机器之心编译
编辑:杜伟、陈萍
还记得谷歌大脑团队去年 6 月份发布的 43 页论文《Scaling Vision with Sparse Mixture of Experts》吗?他们推出了史上最大规模的视觉模型 V-MoE , 实现了接近 SOTA 的 Top-1 准确率 。 如今 , 谷歌大脑开源了训练和微调模型的全部代码 。【150亿参数,谷歌开源了史上最大视觉模型V-MoE的全部代码】在过去几十年里 , 深度学习的进步是由几个关键因素推动的:少量简单而灵活的机制、大型数据集、更专业的硬件配置 , 这些技术的进步使得神经网络在图像分类、机器翻译、蛋白质预测等任务中取得令人印象深刻的结果 。
然而 , 大模型以及数据集的使用是以大量计算需求为代价的 。 最近的研究表明 , 增强模型的泛化能力以及稳健性离不开大模型的支持 , 因此 , 在训练大模型的同时协调好与训练资源的限制是非常重要的 。 一种可行的方法是利用条件计算 , 该方法不是为单个输入激活整个网络 , 而是根据不同的输入激活模型的不同部分 。 这一范式已经在谷歌提出的 pathway(一种全新的 AI 解决思路 , 它可以克服现有系统的许多缺点 , 同时又能强化其优势)愿景和最近的大型语言模型研究中得到了重视 , 但在计算机视觉中还没有得到很好的探索 。
稀疏门控混合专家网络 (MoE) 在自然语言处理中展示了出色的可扩展性 。 然而 , 在计算机视觉中 , 几乎所有的高性能网络都是密集的 , 也就是说 , 每个输入都会转化为参数进行处理 。
去年 6 月 , 来自谷歌大脑的研究者提出了 V-MoE(Vision MoE ) , 这是一种基于专家稀疏混合的新视觉架构 。 当应用于图像识别时 , V-MoE 在推理时只需要一半的计算量 , 就能达到先进网络性能 。 此外 , 该研究还提出了对路由算法的扩展 , 该算法可以在整个 batch 中对每个输入的子集进行优先级排序 , 从而实现自适应图像计算 。 这允许 V-MoE 在测试时能够权衡性能和平滑计算 。 最后 , 该研究展示了 V-MoE 扩展视觉模型的潜力 , 并训练了一个在 ImageNet 上达到 90.35% 的 150 亿参数模型 。

文章图片
论文地址:https://arxiv.org/pdf/2106.05974.pdf
代码地址:https://github.com/google-research/vmoe
V-MoE
谷歌大脑在 ViT 的不同变体上构建 V-MoE:ViT-S(mall)、ViT-B(ase)、ViT-L(arge) 和 ViTH(uge) , 其超参数如下:
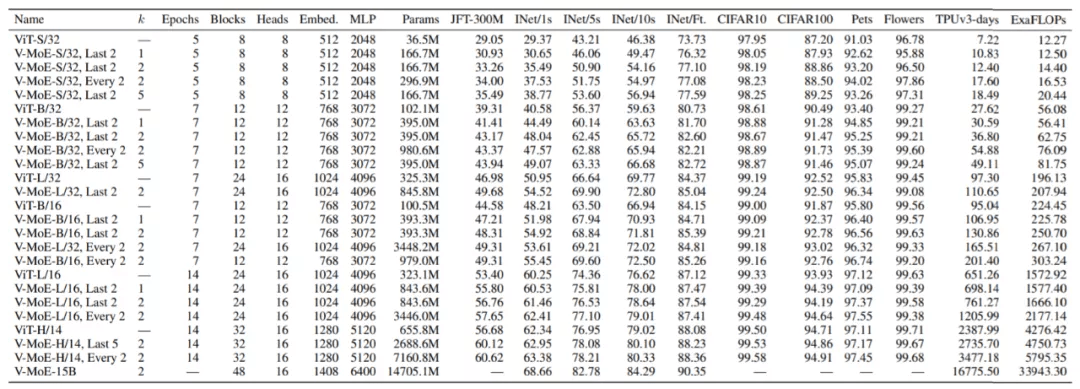
文章图片
ViT 已被证明在迁移学习设置中具有良好的扩展性 , 在较少的预训练计算下 , 比 CNN 获得更高的准确率 。 ViT 将图像处理为一系列 patch , 输入图像首先被分成大小相等的 patch , 这些 patch 被线性投影到 Transformer 的隐藏层 , 在位置嵌入后 , patch 嵌入(token)由 Transformer 进行处理 , 该 Transformer 主要由交替的自注意力和 MLP 层组成 。 MLP 有两个层和一个 GeLU 非线性 。 对于 Vision MoE , 该研究用 MoE 层替换其中的一个子集 , 其中每个专家都是一个 MLP , 如下图所示:
文章图片
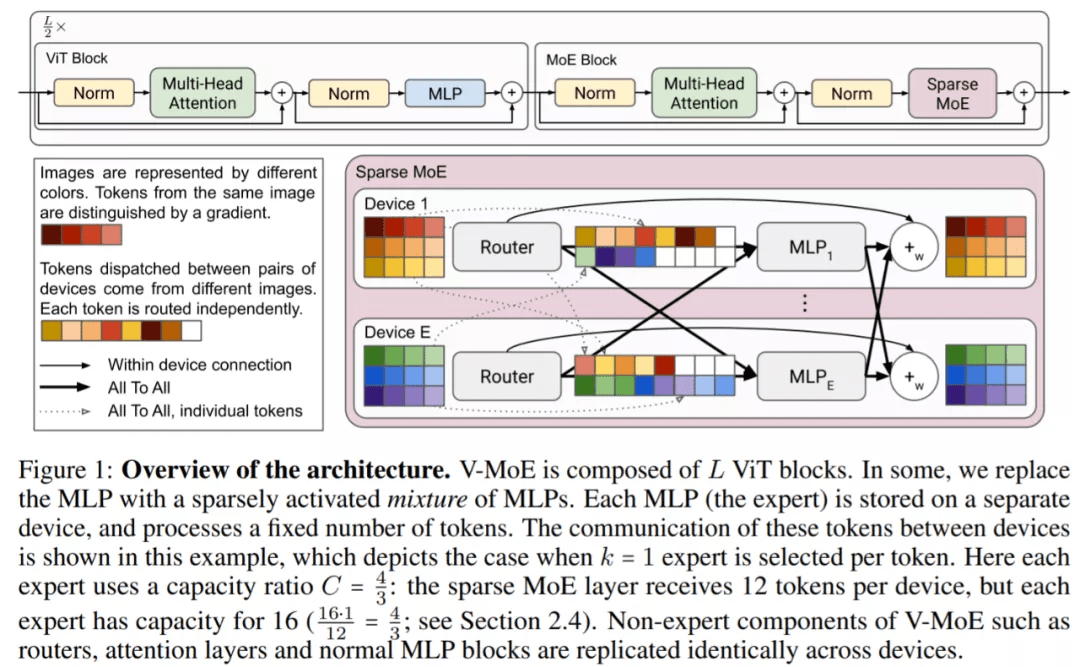
为了大规模扩展视觉模型 , 该研究将 ViT 架构中的一些密集前馈层 (FFN) 替换为独立 FFN 的稀疏混合(称之为专家) 。 可学习的路由层为每个独立的 token 选择对应的专家 。 也就是说 , 来自同一图像的不同 token 可能会被路由到不同的专家 。 在总共 E 位专家(E 通常为 32)中 , 每个 token 最多只能路由到 K(通常为 1 或 2)位专家 。 这允许扩展模型的大小 , 同时保持每个 token 计算的恒定 。 下图更详细地显示了 V-MoE 编码器块的结构 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。