机器之心报道
编辑:张倩、蛋酱
虽然 1.3B 的 InstructGPT 在参数量上还不及 GPT-3 的百分之一 , 但它的表现可比 GPT-3 讨人喜欢多了 。给定一些示例作为输入 , GPT-3 等大型语言模型可以根据这些「提示(prompt)」去完成一系列自然语言处理任务 。 然而 , 它们有时会表现出一些出人意料的行为 , 如编造事实、生成有偏见或有害的文本 , 或者根本不遵循用户的指示 。 比如在下面这个例子中 , 用户给出的指示是:「用几句话向一个 6 岁的孩子解释一下登月」 , GPT-3 的的输出显然是不着边际 。
【GPT-3胡言乱语怎么办?OpenAI:重新调教一下,新版本更「听话」】

文章图片
这是因为 , GPT-3 被训练成基于互联网文本的大数据集预测下一个单词 , 而不是安全地执行用户想要它执行的语言任务 。 换句话说 , 这些模型的输出与用户的意图并不一致 。 对于在数百个应用中部署和使用的语言模型来说 , 避免这些意想不到的行为尤其重要 。
通过训练语言模型按照用户的意图行动 , OpenAI 在调整语言模型方面取得了新进展 。 这里的「意图」既有明确的(如遵循指令) , 也有隐含的(如尊重事实、不带有偏见或恶意等) , 他们希望改进后的模型是有用的(帮助用户解决他们的问题)、诚实的(不编造信息或误导用户)、无害的(不对人或环境造成身体、心理或社会伤害) 。
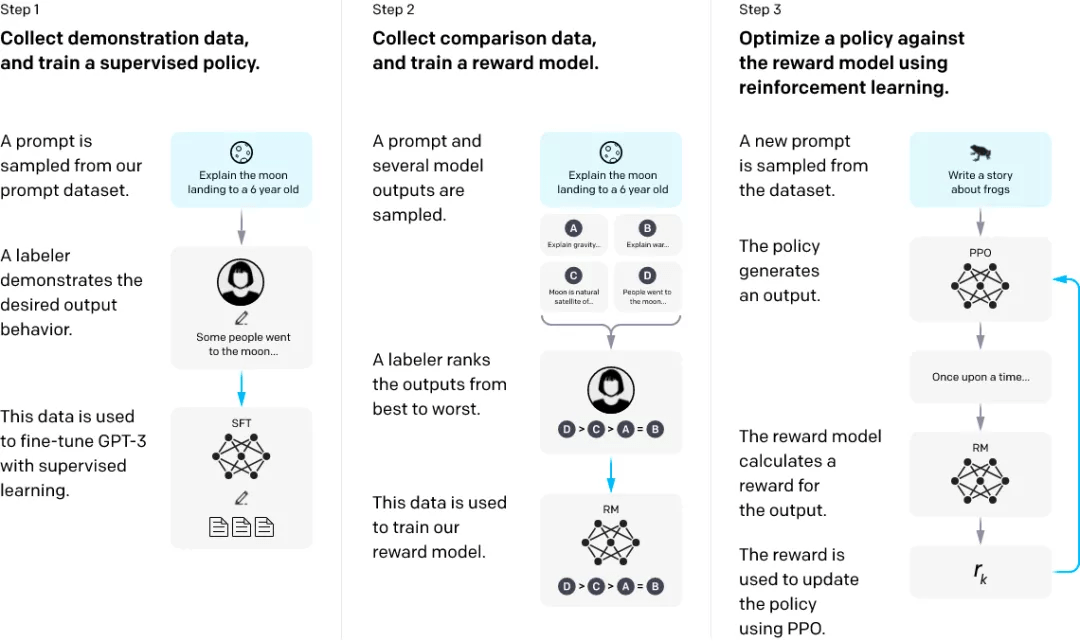
为了达成这一目标 , 他们使用了利用人类反馈的强化学习方法(RLHF)对 GPT-3 进行微调 , 使其遵循广泛的书面指令 。 这项技术利用人类的偏好作为奖励信号来微调 GPT-3 。 这一过程让 GPT-3 的行为与特定人群(主要是 OpenAI 的标注者和研究人员)的既定偏好保持一致 , 而不是更广泛的「人类价值」概念 。 他们将得到的模型称为 InstructGPT 。
在面对同一指令(用几句话向一个 6 岁的孩子解释一下登月)时 , InstructGPT 给出了如下的输出结果:

文章图片
研究者主要通过让标注者对测试集上的模型输出质量进行评分来评估模型 , 测试集包含来自「held-out」标注者的 prompt , 还在一系列公共的 NLP 数据集上进行了自动评估 。 他们训练了三种尺寸的模型(1.3B、6B 和 175B 参数) , 所有的模型都使用 GPT-3 架构 。 其主要发现如下:
1、标注者明显更喜欢 InstructGPT 的输出 , 而不是 GPT-3 。 在测试集中 , 来自 1.3B InstructGPT 模型的输出优于来自 175B GPT-3 的输出 , 尽管前者的参数量还不到后者的 1/100 。
2、与 GPT-3 相比 , InstructGPT 输出的真实性有所提高 。
3、与 GPT-3 相比 , InstructGPT 输出的有害性略有改善 , 但偏见程度并没有 。
4、可以通过修改 RLHF 微调过程来最小化模型在公共 NLP 数据集上的性能倒退 。
5、模型可以泛化至「held-out」标注者的偏好 , 这部分标注者没有参与任何训练数据的生产 。
6、公共的 NLP 数据集并不能反映 InstructGPT 语言模型的实际效果 。
7、InstructGPT 模型显示出了泛化至 RLHF 微调分布之外的指令的潜力 。
8、InstructGPT 仍然会犯一些简单的错误 。
所以总的来看 , 通过人类的反馈进行微调是一个很有前途的方向 , 可以使语言模型与人类的意图保持一致 , 但在提高它们的安全性和可靠性方面还有很多工作要做 。
方法
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。