首先 , 汉字字形远比字母复杂 , 9 * 14 像素的点阵大小肯定是不够描绘汉字的 , 先不说现在都打不出来的 “ biang ” 字 , 至少也要 16 * 16 像素才能满足大部分汉字的需要 。

文章图片
所以那个能自定义像素显示的图形模式 , 便成了汉字 “ 偷渡 ” 进计算机的路子之一 。
其次 , 汉字数量的庞大 , 也让点阵信息的储存成了大问题 。 几 KB 的显存与 128 K 的内存指定是不够的 , 所以外置的汉字库也是难点 。
再次 , 汉字的输入也非常难搞 。
相信看过上期打字机的朋友 , 一定还记得这个让人头疼的舒氏打字机 。
虽然汉字编码的设计 , 肯定要比明快打字机的机械设计来的容易 , 但从当时国内四五百种汉字编码方案中 , 选出最为高效、科学的一批做为输入法 , 依旧需要大量的研究与实践 。
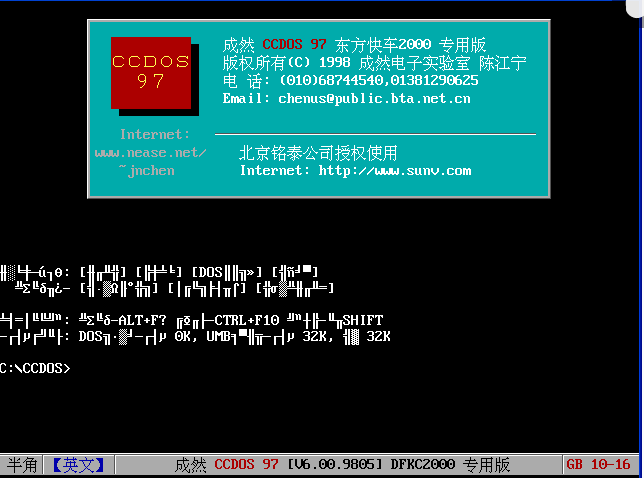
而这些问题在 1983 年发布的 CC-DOS 上 , 终于得到了初步的解决 。
这套由电子工业部第六研究所在 IBM PC 上开发出的汉字操作系统 , 第一次以软件的形式让方块汉字显示在了电脑上 。
这套软件内 , 存有 6726 个常用汉字 , 支持使用拼音、区位码和首位码输入汉字 , 接上打印机后也支持打印输出 。
后续的中文外挂平台 ▼
文章图片
最重要的是 , 这套系统能够支持 c-dBASE II 这样的中文软件 , 让不熟悉英文的人也能使用计算机办公 。
可以说 , 作为汉字迈进个人电脑的第一步 , CC-DOS 算是成功了 。
但尽管这套系统已经有了实用价值 , 问题依旧很多 。
首当其冲的就是这套系统的使用限制 , CC-DOS 1.1 版的正常使用 , 要求电脑至少配有 320 K 内存 , 2.0 版本至少要 512 K 。
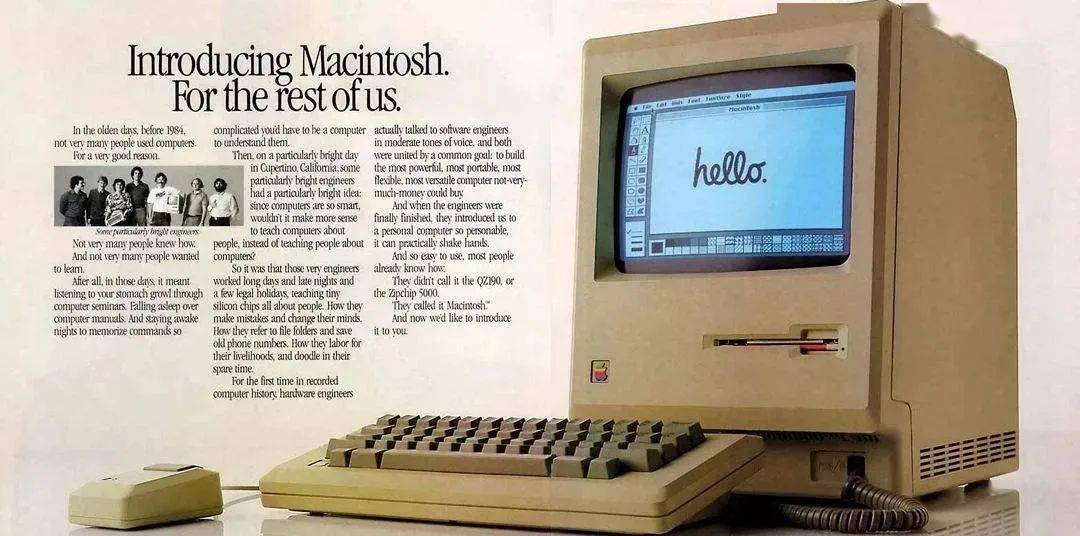
作为对比 , 1984 年乔布斯发布的麦金塔一代 , 初始内存大小也只有 128K , 售价 2500 刀 。
文章图片
除此之外 , 这种只依靠外挂软件实现中文显示的方法 , 还存在自身的局限性 :将汉字从磁盘调入内存的速度太慢 , 导致电脑在使用的过程中 , 大部分时间都在等待汉字加载 。
除了能用但不好用的软件方案外 , 还有没有别的办法呢?有 , 上硬件喽 。
硬件解决
IBM PC 的一大特点 , 就是它优秀的兼容性和拓展性 。 于是更多的研究人员将目光放在了硬件方案上 。
就在 CC-DOS 发布的同一年 , 中科院计算所的倪光南在十多年的研究后 , 推出了 LX-80 汉字图形微型机 , 成功的在硬件层面上 , 实现了汉字在计算机上的输入、编码、输出、打印等一系列问题 。
注意 , 这里所说的硬件可不是指某一个硬件 , 而是采用 Zilog 公司的 Z80 芯片开发出的一整台电脑 。
后来联想汉卡上包括汉字处理、联想输入等基本功能都是继承自 LX-80 。
虽然在技术上 LX80 是领先的 , 但当时 IBM PC 就像现在的 x86 一样 , 已经成为了事实上的计算机主流 , 如果能将 LX80 的核心技术浓缩为一张硬件拓展卡 , 那国内所有的 PC 机就都能够实现汉字环境 , 按现在的话来说就是: 不重复造轮子 。
1984 年 , 倪光南出任联想总工程师 , 开始将这一技术成果转化为实际产品 。 在几个月的通宵达旦后 , 于 1985 年 5 月正式推出了第一型联想汉卡 。
硬件的解决方案终于成功了 , 这也就意味着只处理英文的 PC 在插上汉卡后 , 就能变成一台能处理汉字的 PC , 电脑终于能最大程度上得到普及 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。