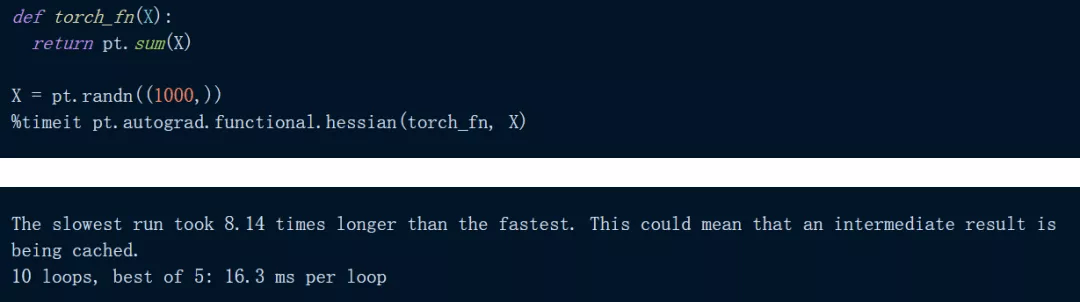
下面代码是在 PyTorch 中对一个简单的输入总和进行 Hessian:
文章图片
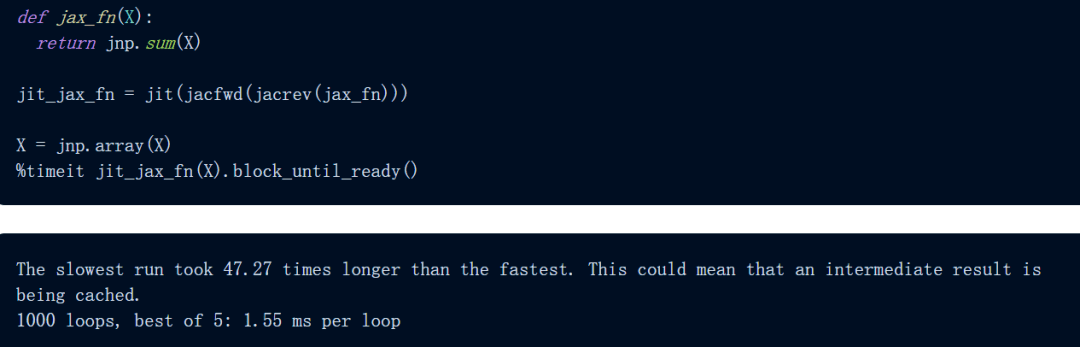
正如我们所看到的 , 上述计算大约需要 16.3 ms , 在 JAX 中尝试相同的计算:
文章图片
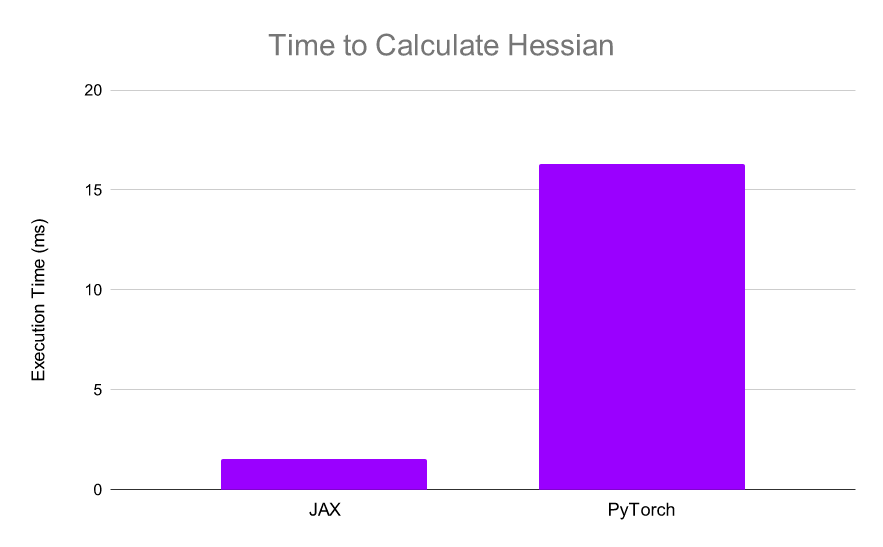
使用 JAX , 计算仅需 1.55 毫秒 , 比 PyTorch 快 10 倍以上:
文章图片
JAX 可以非常快速地计算 Hessians , 使得高阶优化更加可行 。
使用 vmap() 自动向量化
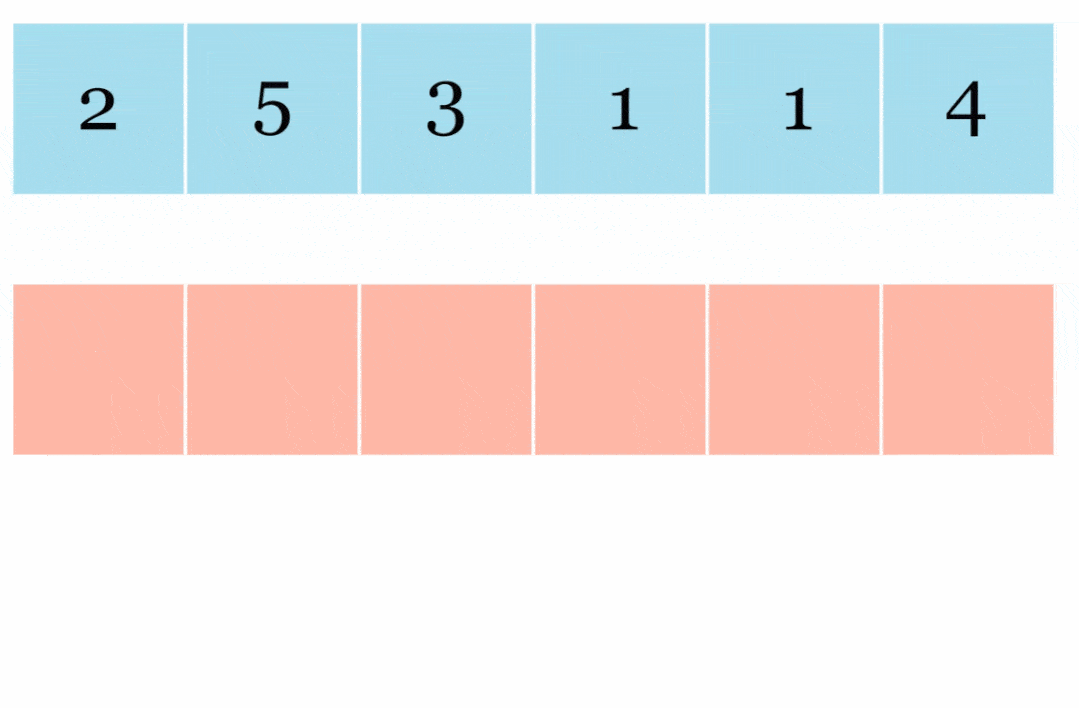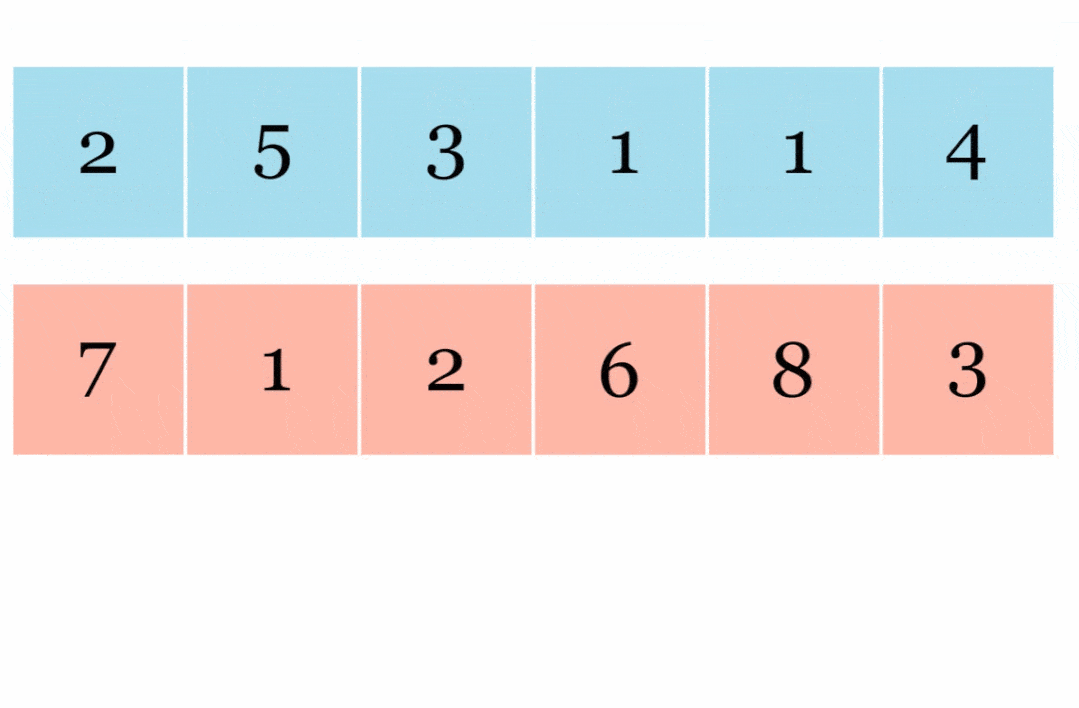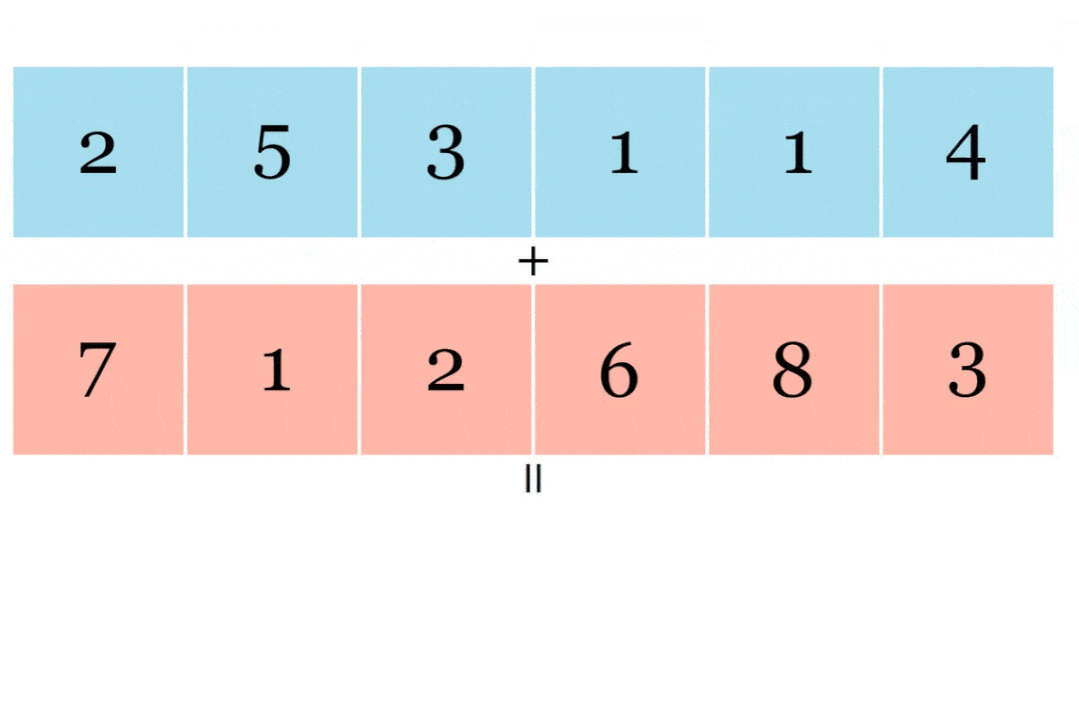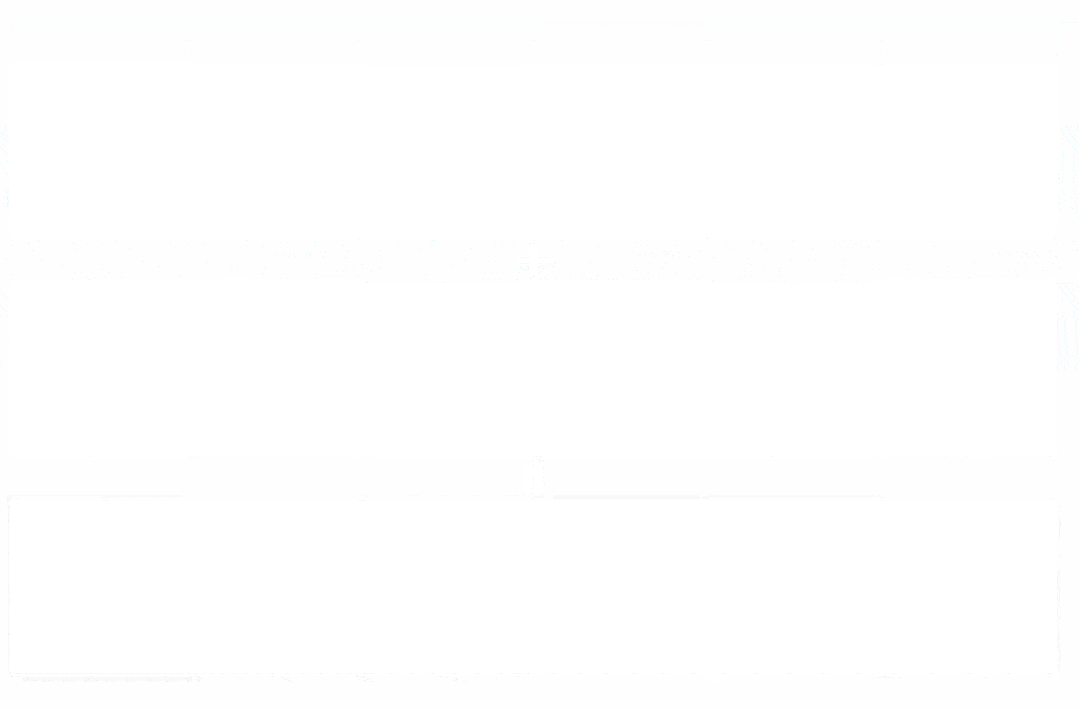
JAX 在其 API 中还有另一种变换:vmap() 自动向量化 。 以下是矢量化向量加法展示:
文章图片
使用 pmap() 实现自动并行化
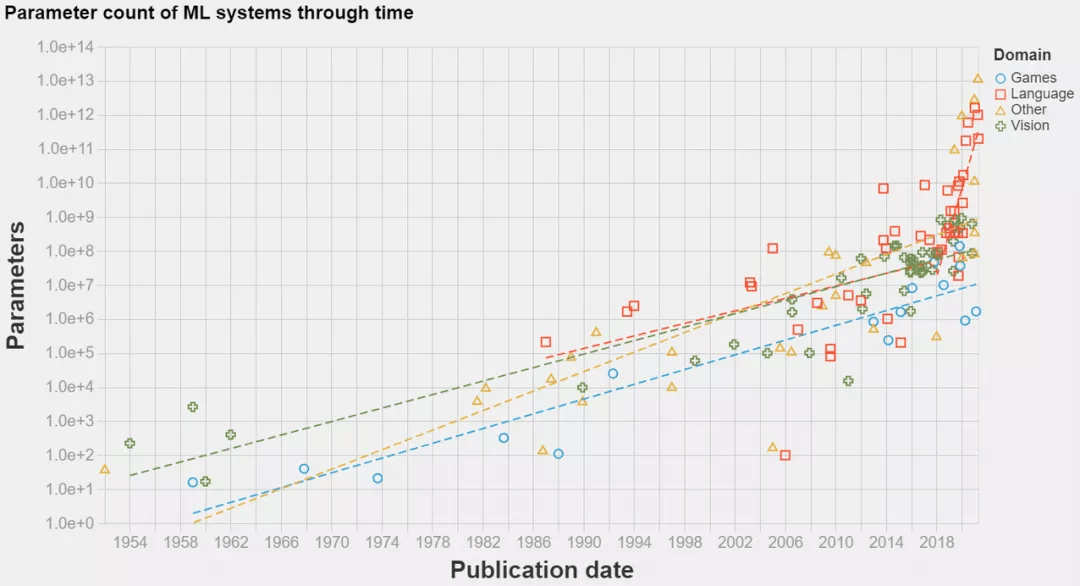
分布式计算变得越来越重要 , 在深度学习中尤其如此 , 如下图所示 , SOTA 模型已经发展到超大规模 。
文章图片
得益于 XLA , JAX 可以轻松地在加速器上进行计算 , 但 JAX 也可以轻松地使用多个加速器进行计算 , 即使用单个命令 - pmap() 执行 SPMD 程序的分布式训练 。
我们以向量矩阵乘法为例 , 如下为非并行向量矩阵乘法:
文章图片
使用 JAX , 我们可以轻松地将这些计算分布在 4 个 TPU 上 , 只需将操作包装在 pmap() 中即可 。 这允许用户在每个 TPU 上同时执行一个点积 , 显着提高了计算速度(对于大型计算而言) 。

文章图片
使用 jit() 加快功能
JIT 编译是一种执行代码的方法 , 介于解释(interpretation)和 AoT(ahead-of-time)编译之间 。 重要的是 , JIT 编译器在运行时将代码编译成快速的可执行文件 , 但代价是首次运行速度较慢 。
JIT 不是一次将一个操作分配给 GPU 内核 , 而是使用 XLA 将一系列操作编译成一个内核 , 从而为函数提供端到端编译的高效 XLA 实现 。
以下图为例 , 代码定义了一个函数:用三种方式计算 5000 x 5000 矩阵——一次使用 NumPy , 一次使用 JAX , 还有一次在 JIT 编译的函数版本上使用 JAX 。 我们首先在 CPU 上进行实验:
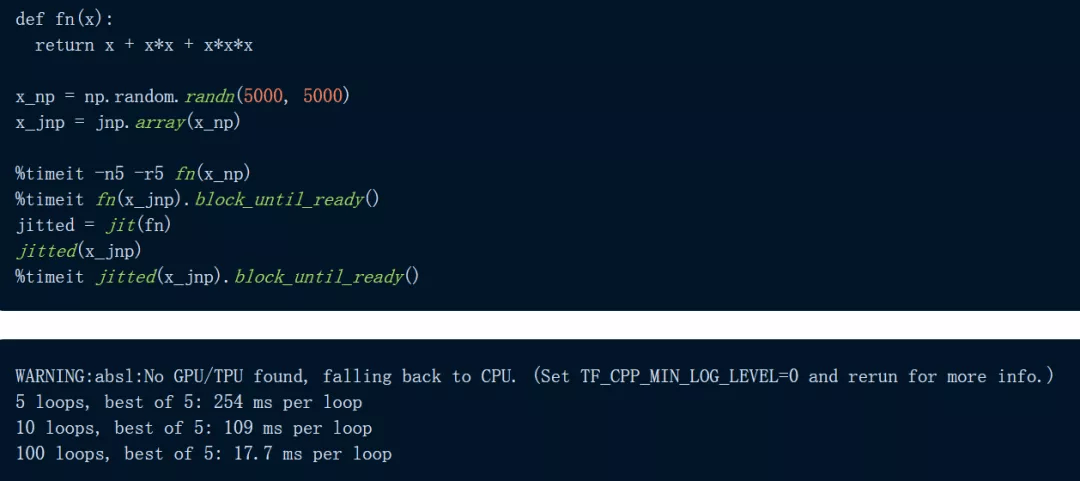
文章图片
文章图片
JAX 对于逐元素计算明显更快 , 尤其是在使用 jit 时 。
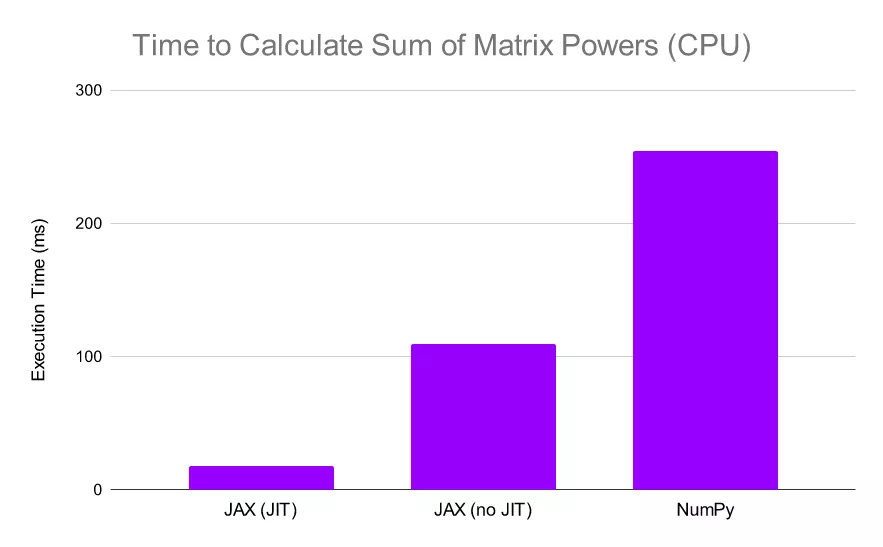
我们看到 JAX 比 NumPy 快 2.3 倍以上 , 当我们 JIT 函数时 , JAX 比 NumPy 快 30 倍 。 这些结果已经令人印象深刻 , 但让我们继续看 , 让 JAX 在 TPU 上进行计算:
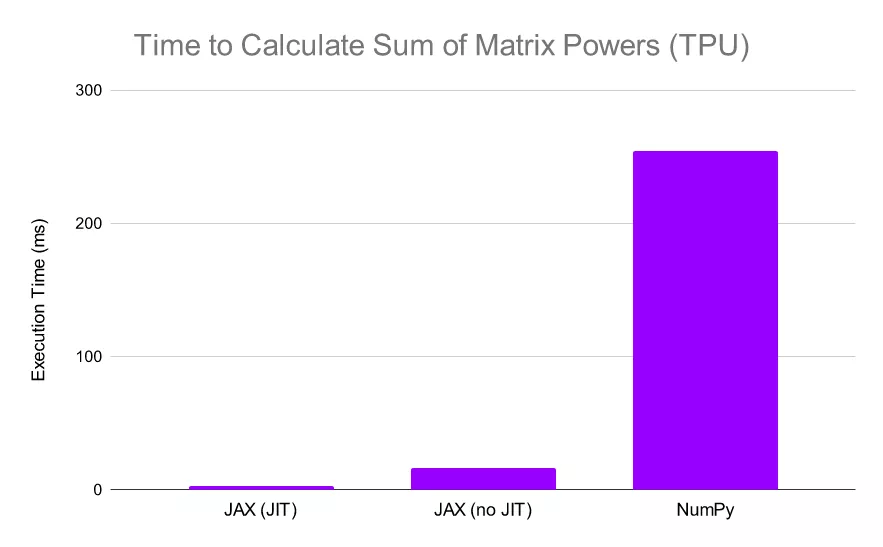
文章图片
当 JAX 在 TPU 上执行相同的计算时 , 它的相对性能会进一步提升(NumPy 计算仍在 CPU 上执行 , 因为它不支持 TPU 计算)在这种情况下 , 我们可以看到 JAX 比 NumPy 快了惊人的 13 倍 , 如果我们同时在 TPU 上 JIT 函数和计算 , 我们会发现 JAX 比 NumPy 快 80 倍 。
当然 , 这种速度的大幅提升是有代价的 。 JAX 对 JIT 允许的函数进行了限制 , 尽管通常允许仅涉及上述 NumPy 操作的函数 。 此外 , 通过 Python 控制流进行 JIT 处理存在一些限制 , 因此在编写函数时须牢记这一点 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。