模型架构
由于视觉和文本模态的编码器是解耦的 , 因此可以为这两种模态探索不同的编码器架构 。 研究者试验了三种视觉编码器变体(即 ResNet、Vision Transformer 和 Swin Transformer)以及一个单一的类 BERT 文本编码器来训练中文 VLP 模型 。
预训练目标
跨模态对比学习是一种从成对的图像 - 文本数据中训练模型的特别有效的方法 , 它可以通过区分成对和不成对的样本同时学习两种模态的表示 。 研究者遵循 FILIP(Yao 等人 , 2022)中的公式标记 , 使用
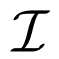
文章图片
去定义图像样本集合 , 同时
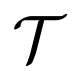
文章图片
代表文本数据 。 给定一个图像样本
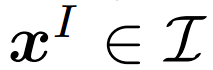
文章图片
和一个文本样本
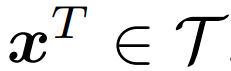
文章图片
, 该模型的目标是让联合多模态空间中的配对的图像和文本表示接近 , 不配对的则远离 。
在这项工作中 , 研究者探索了两种衡量图像和文本之间相似度的方法 。 图像和文本的学得表示分别标记为
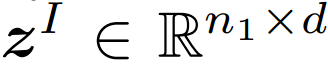
文章图片
和
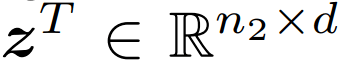
文章图片
。 这里 , n_1 和 n_2 是每个图片和文本中的(未填充的)词 token 的数量 。
LiT-tuning
研究者受到了最近提出的一种微调范式 LiT-tuning(Locked-image Text tuning)的启发 , 该范式表明权重固定的图像编码器和可学习的文本编码器在 VLP 模型中效果最好 。 他们在对比学习设置中也采用了同样的方式 , 即只更新文本编码器的权重 , 而不更新图像编码器的权重 。
具体而言 , 研究者采用的 LiT-tuning 方法旨在教一个中文的文本编码器从一个现有的图像编码器中读取合适的表示 , 该图像编码器是在英文数据集上预训练过 。 他们还为每个编码器添加了一个可选的可学习线性变换层 , 它将两种模式的表示映射到相同的维度 。 LiT-tuning 之所以效果很好 , 是因为它解耦了用于学习图像特征和视觉语言对齐的数据源和技术(Zhai 等人 , 2021b) 。 并且 , 图像描述器事先使用相对干净或(半)手动标记的图像进行了良好的预训练 。
研究者将这一想法扩展到多语言数据源 , 并尝试将在英文数据源上预训练的固定了的图像编码器和可训练的中文文本编码器对齐 。 此外 , LiT-tuning 方法显著加快了训练过程并减少了内存需求 , 因为它不需要为视觉编码器计算梯度 。
实验结果
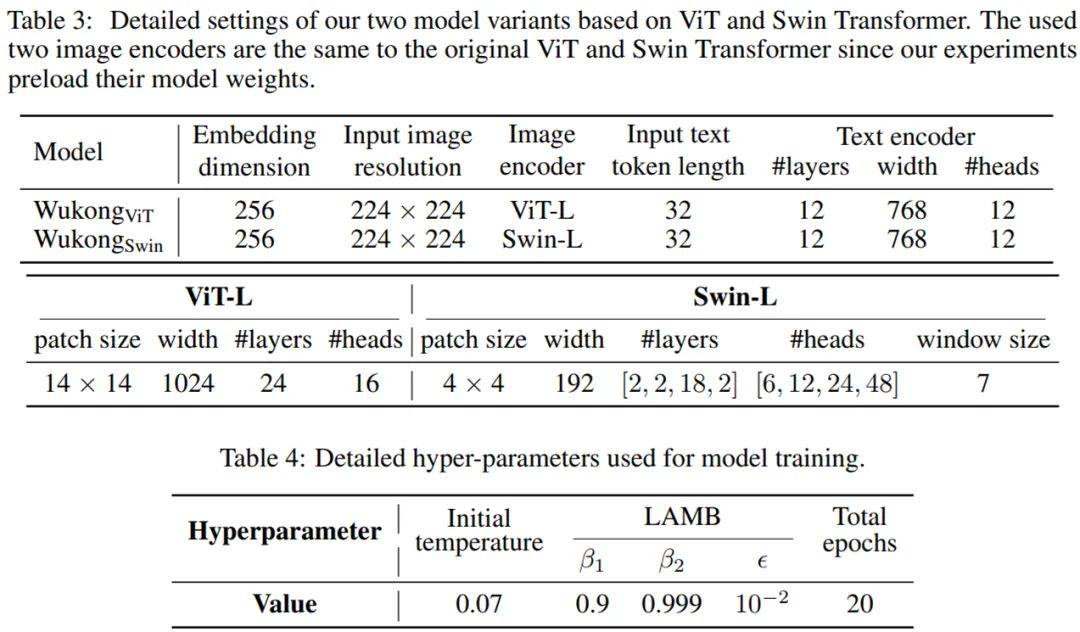
下表 3 描述了模型参数和视频编码器的细节 。
文章图片
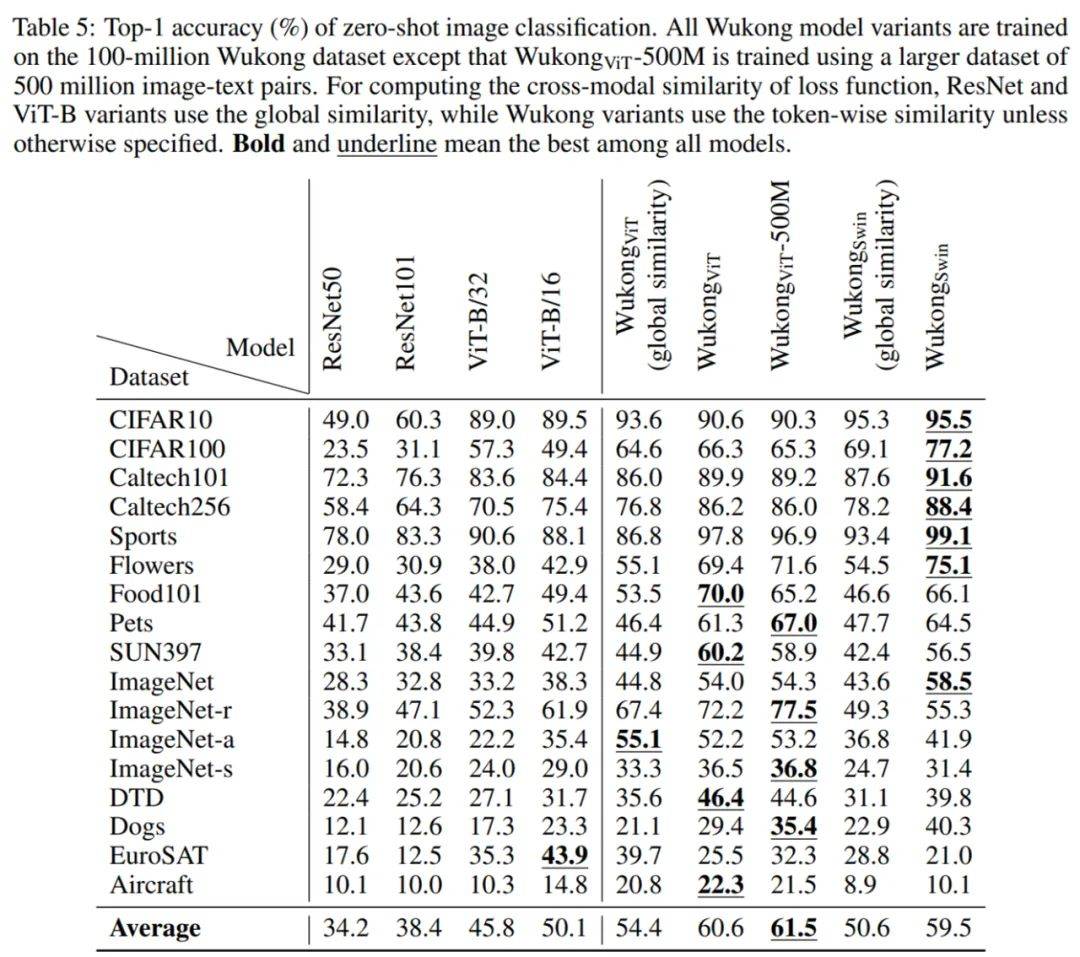
零样本图像分类 。 研究者在 17 个零样本图像分类任务上评估预训练模型 。 零样本图像分类的结果如下表 5 所示 。 他们比较了使用不同视觉编码器的多个 LiT -tuning 模型 , 即从 CLIP 或 Swin Transformer 加载现有的视觉编码器并在训练阶段固定它们的权重 。 结果发现 , 使用 token 水平的相似度比使用全局相似度会带来更显著的改进 。
文章图片
图文检索任务 。 研究者在两个子任务 , 即以图搜文和以文搜图上做了评估 。 下表 6 和表 7 分别显示了零样本设定和可以微调的图文检索的结果 。 对于零样本设置 , 相比其它模型 , Wukong_ViT 在 4 个数据集中的 3 个上取得了最好的结果 , 而 Wukong_ViT-500M 在更大的 MUGE 数据集上取得了最好的结果 。 对于微调设置 , Wukong_ViT-500M 则在除 AIC-ICC 之外的所有数据集上都取得了最好的结果 , 其中 Wukong_ViT 效果最好 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。