选自arXiv
作者:Jiaxi Gu等
机器之心编译
编辑:Juniper
华为诺亚方舟实验室的研究者提出了一个大规模的中文的跨模态数据库 ——「悟空」 , 并在此基础上对不同的多模态预训练模型进行基准测试 , 有助于中文的视觉语言预训练算法开发和发展 。在大数据上预训练大规模模型 , 对下游任务进行微调 , 已经成为人工智能系统的新兴范式 。 BERT 和 GPT 等模型在 NLP 社区中越来越受欢迎 , 因为它们对广泛的下游任务甚至零样本学习任务具有很高的可迁移性 , 从而产生了 SOTA 性能 。 最近的工作 , 如 CLIP、ALIGN 和 FILIP 进一步将这一范式扩展到视觉语言联合预训练 (VLP) 领域 , 并在各种下游任务上显示出优于 SOTA 方法的结果 。 这一有希望的方向引起了行业和研究人员的极大关注 , 将其视为通向下一代 AI 模型的途径 。
促成 VLP 模型成功的原因有两个 。 一方面 , 更高级的模型架构(如 ViT/BERT)和训练目标(如对比学习)通常能够提升模型泛化能力和学得表示的稳健性 。 另一方面 , 由于硬件和分布式训练框架的进步 , 越来越多的数据可以输入到大规模模型中 , 来提高模型的泛化性、可迁移性和零样本能力 。 在视觉或者语言任务中 , 先在大规模数据(例如图像分类中的 JFT-300M、T5 中的 C4 数据集)上预训练 , 之后再通过迁移学习或者 prompt 学习已被证明对提高下游任务性能非常有用 。 此外 , 最近的工作也已经显示了 VLP 模型在超过 1 亿个来自网络的有噪声图像 - 文本对上训练的潜力 。
因此 , 在大规模数据上预训练的 VLP 模型的成功促使人们不断地爬取和收集更大的图文数据集 。 下表 1 显示了 VLP 领域中许多流行的数据集的概述 。 诸如 Flickr30k、SBU Captions 和 CC12M 等公开可用的视觉语言(英语)数据集的样本规模相对较小(大约 1000 万) , 而规模更大的是像 LAION-400M 的数据集 。 但是 , 直接使用英文数据集来训练模型会导致中文翻译任务的性能大幅下降 。 比如 , 大量特定的中文成语和俚语是英文翻译无法覆盖的 , 而机器翻译往往在这些方面会带来错误 , 进而影响任务执行 。
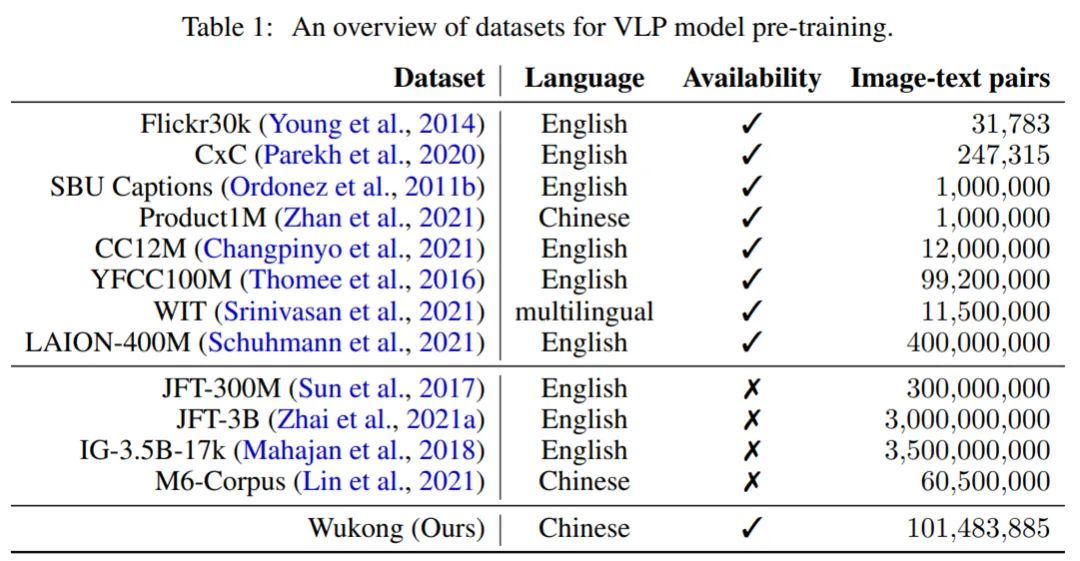
文章图片
目前 , 社区缺乏大规模公开可用的中文数据集 , 不仅导致社区发展受阻 , 而且每项工作都使用一个私密的大型数据集来实现 , 达到一个其它工作无法公平比较的惊人性能 。
为了弥补这一差距 , 华为诺亚方舟实验室的研究者发布了一个名为「悟空」的大型中文跨模态数据集 , 其中包含来自网络的 1 亿个图文对 。 为了保证多样性和泛化性 , 悟空数据集是根据一个包含 20 万个高频中文单词列表收集的 。 本文还采用基于图像和基于文本的过滤策略来进一步完善悟空数据集 , 使其成为了迄今为止最大的中文视觉语言跨模态数据集 。 研究者分析了该数据集 , 并表明它涵盖了广泛的视觉和文本概念 。

文章图片
- 论文地址:https://arxiv.org/pdf/2202.06767.pdf
- 数据集地址:https://wukong-dataset.github.io/wukong-dataset/benchmark.html
- 发布了具有 1 亿个图文对的大规模视觉和中文语言预训练数据集 , 涵盖了更全面的视觉概念;
- 发布了一组使用各种流行架构和方法预训练好的大规模视觉 - 语言模型 , 并提供针对已发布模型的全面基准测试;
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。