开始建立术语的一个好方法是阐明这些词语想要和不想要传达的意思 。 后者对我们来说尤其重要 , 因为我们不希望术语唤起特定于任何具体学科的直觉 。 例如 , 将决策者成为有机体会干扰将它看作机器 , 就像在人工智能中一样 。 决策者的本质在于它的行动具有一定的自主性 , 对输入非常敏感 , 并对未来的输入具有倾向性影响 。 对于决策者的一个很好的称呼是智能体 , 它的定义是「扮演积极决策或产生特定效果的人或物」 。 人工智能领域通常使用智能体来表述决策者 , 可能是机器或人 。 智能体也比决策者更可取 , 因为它意味着自主性和目的性 。
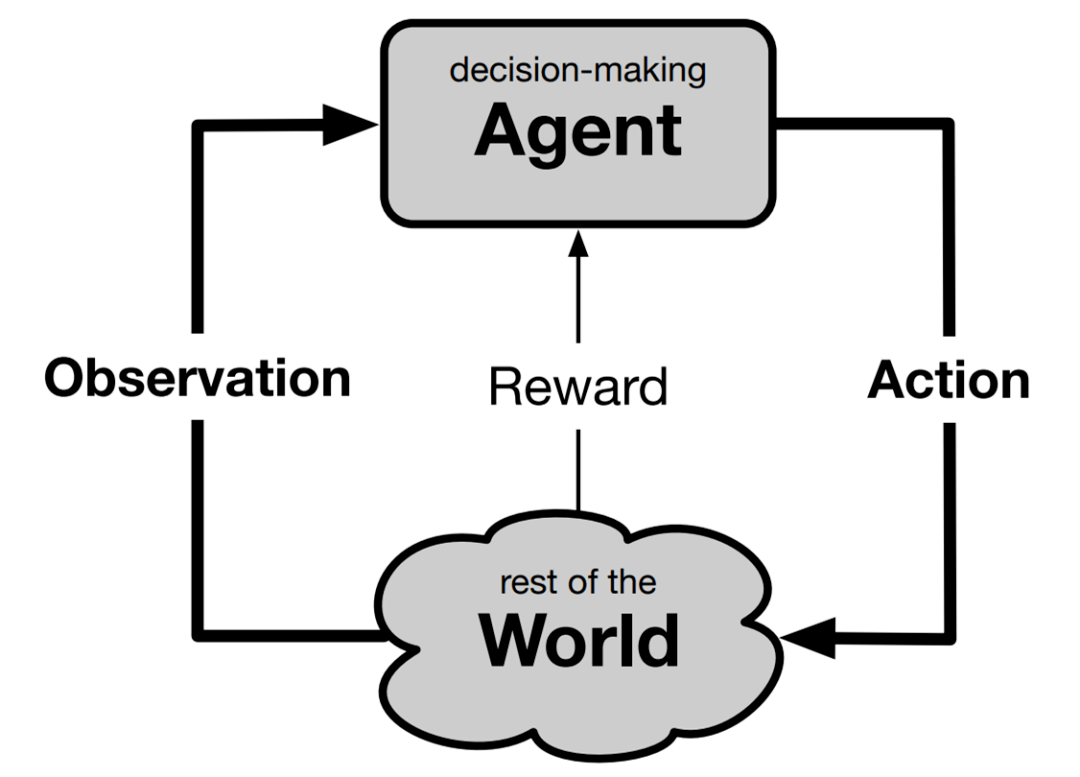
那么决策智能体与什么进行交互呢?答案是它能与所有不是智能体的一切事物产生交互 , 这可以被称作它的环境或世界 。 这两个术语与特定学科没有强关联 , 但本文选择世界的原因在于它更简单 , 同时不与任何特定学科产生关联的方式令人印象深刻 。 如下图所示 , 为了完成智能体与世界交互的场景 , 我们必须为每个方向上传递的信号命名 。 可以很自然地说 , 智能体采取了行动 , 并接收到了感知或观察 。 这里使用了观察 , 因为它是用于此目的的既定术语 , 并且避免了关于机器是否有感知的形而上学讨论 。 在标准用法中 , 观察指的是可能不完整的关于世界状态的信息 。
文章图片
基本规则
【强化学习教父新论文探索决策智能体的通用模型:寻找跨学科共性】前面的讨论阐释了 Sutton 在术语方面想要遵循的基本规规则和步骤 , 具体如下:
1)确定词语想要表达的独立于学科的含义;
2)找到一个能够捕获该含义且不会过度偏向一个或另一个学科的常识词语;
3)重复前两个步骤 , 直到发现跨学科共性 。
Sutton 遵循的第二种基本规则不是关于术语 , 而是关乎内容 。 当我们想要开发一个通用决策模型时 , 应该包含和排除哪些方面?他试图遵循的规则是涵盖领域(field)的交集而不是并集 。 也就是说 , 为了包含一个方面 , 它仅出现在一个领域是不够的 , 至少要与其他很多(如果不是全部)领域产生关联 。 通用模型的各个方面随时间推移必须普遍适用于所有决策 , 以实现一个目标 。
通用模型中不应有任何特定于我们世界的内容 , 例如视觉、目标、三维空间、其他智能体或语言 。 我们排除的简单例子是使人们与众不同并异于其他动物的所有事物 , 或者动物通过进化以适应它们生态环境的所有特定知识 。 这些都是人类学和行为学中特别重要的主题 , 真正提高了我们对自然智能系统的理解 , 但在通用模型中没有位置 。 同样地 , 我们排除了由人类设计师在人工只能系统中构建的所有领域知识 , 以开发出需要更少训练的应用 。 所有这些在各自学科内部都很重要 , 但与旨在应用于跨学科的通用模型是无关的 。
除了促进跨学科互动之外 , 通用决策模型可能还有其他用途 。 由于现有学科和它们的价值已经建立 , 因此很容易看到学科内部的共性成果 。 了解自然系统具有清晰的科学价值 , 创建更有用的工程产品具有显著的实用价值 。 但是 , 如果不考虑智能决策与自然决策的关系 , 也不考虑智能决策产品的实际效用 , 那么理解智能决策的过程是不是就没有科学价值呢?Sutton 认为是这样 。 智能决策不是目前已确定的科学 , 但也许有一天会成为独立于生物学或其工程应用的决策科学 。
加性奖励
现在来讨论决策智能体的目标 。 现在 , 大多数学科根据在智能体直接控制之外产生的标量信号来指定智能体的目标 , 因此我们将其生成置于世界中 。 在一般情况下 , 这一信号在每个时间步到达 , 目标是最大化总和 。 这种加性奖励可用于将目标表述为折扣总和或有限范围内总和 , 也或者是基于每个时间步的平均奖励 。 用于表述奖励的名称有很多 , 比如报酬(payoff)、收益(gain)或者效用(utility) , 以及最小化奖励时的成本(cost) 。 如果允许成本为负 , 则成本和最小化在形式上是等价的 。 一个更简单但仍然流行的目标概念是要达到的世界状态 。 目标状态有时也可以用 , 但不如加性奖励通用 。 例如 , 目标状态无法维护目标 , 也无法明确说明时间成本与不确定性之间的权衡 , 但所有这些都可以通过加性框架轻松地处理 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。