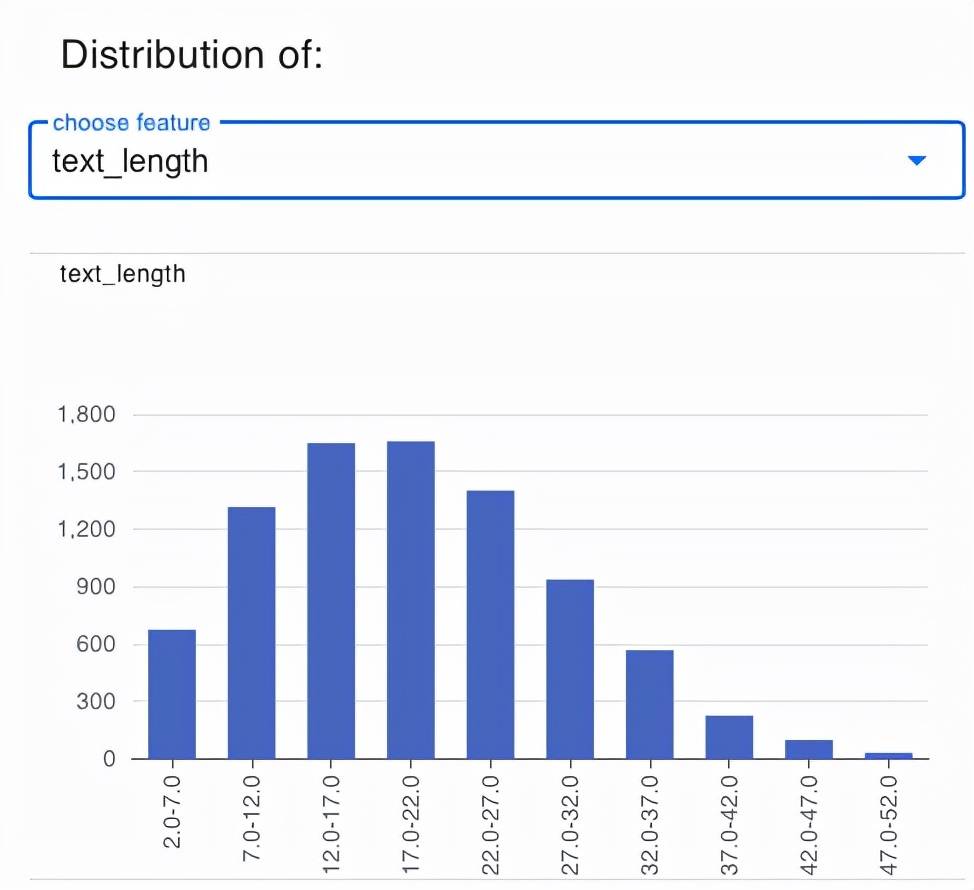
【CMU携手NUS、复旦推出DataLab:打造文本领域数据分析处理Matlab】细粒度分析指的是 , 我们从多个不同的角度去认识一个数据集的特性 。 下图 2 为 SST 数据集(自然语言处理中关于情感分析的流行数据集)中的样本按照不同文本长度划分的分布图 。
文章图片
图 2:SST 数据集的样本按照不同文本长度划分的统计分布图
使用 DataLab , 用户可以选择任意支持的分析角度 , 实现一键化操作 。 DataLab 还支持数据集级别的整体分析 , 欢迎登录网站试玩 。
2. 数据集中存在的 「偏见」
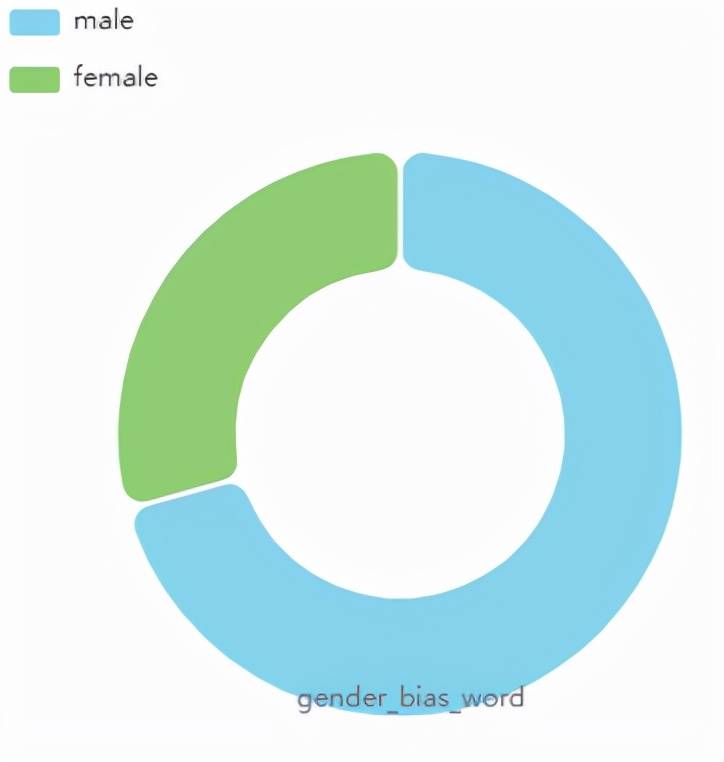
DataLab 可以帮助用户一键化地识别数据集中的「偏见」 。 目前支持三种分析:
- 性别偏见
- 仇恨言论
- artifacts
文章图片
图 3:SST2 数据集的性别偏见分布
再比如 , 利用 DataLab , 我们容易复现 Gururangan et al.[4] 在 SNLI 数据集(自然语言处理中关于两个句子关系推理流行的数据集)上发现的一个很有名的 artifact 现象:hypothesis 越长的句对 (premise-hypothesis) 通常是「neutral」关系 , 如下图 4 所示 。

文章图片
图 4:SNLI 数据集的 artifact 现象
3. Prompt 的分析
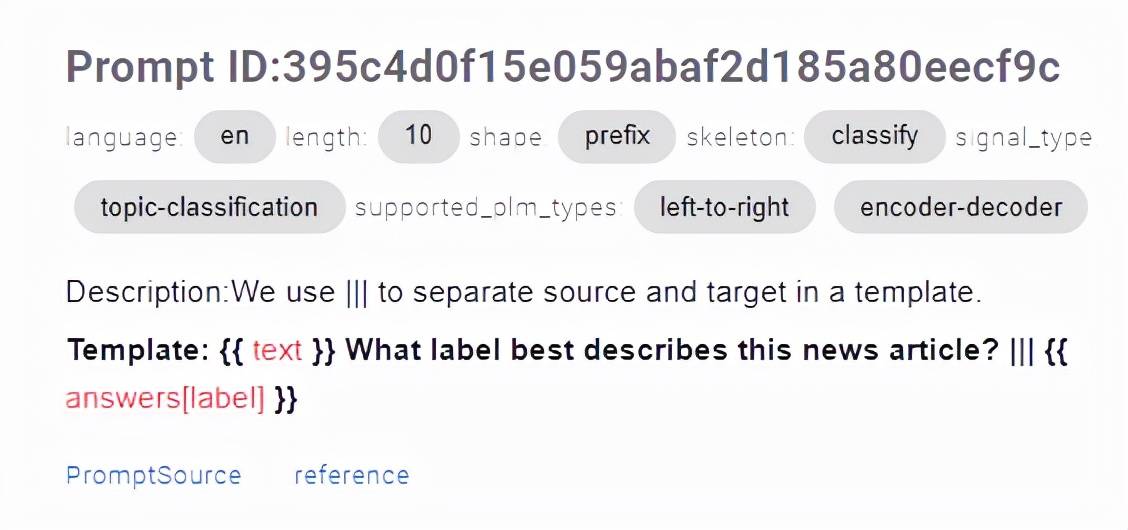
Prompt Learning 已经得到了相当多的关注 , 因为它能更好地利用预训练的语言模型中有利于许多 NLP 任务的知识 。 在实际应用中 , 什么是好的「Prompt」是一个具有挑战性的问题 。 下图 5 为DataLab 定义 Prompt 的一个例子 。
文章图片
(a)Prompt的定义
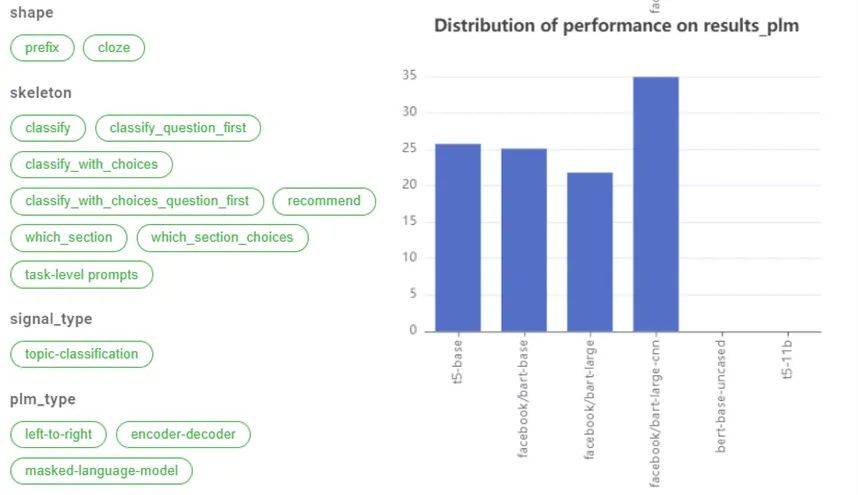
文章图片
(b)属性;(c)同一个数据集Prompts在不同PLM上的结果
DataLab 目前不但支持了 3000 多个已经设计好的 Prompt(包含 PromptSources 公布的 2000 多个) , 覆盖了上百个数据集 , 并且为 Prompt 设计了一个模式 , 使得每一个 Prompt 可以被许多不同的角度刻画 。 图 5 为 DataLab 定义的 Prompt 例子 , 包括 Prompt 的特征 (如长度、形状等)、属性 (如模板、答案等)、支持的预训练语言模型 , 以及它在不同的预训练语言模型的结果(图 5 下右) 。 该设计不仅可以帮助研究者更好地设计 Prompt , 还可以分析什么是好的 Prompt 。
4. 对比两个数据集差异
在做研究时 , 了解两个数据集之间的详细差异在很多方面都很重要 , 例如 , 它可以帮助我们解释模型训练在不同数据集上的不同行为 。 然而 , 分析它们的差异是一项繁琐的工作 , 通常需要设计不同的特征并且在不同的数据集上去计算 。 DataLab 将这一过程自动化 , 并帮助研究人员以非常方便的方式进行两两数据集分析 。
我们选取了两个文本摘要的数据集进行测试 ,然后会得到关于这两个数据集全方面的比较 , 如下雷达图 , 两个数据集各自特点可以清晰的被刻画 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。