文章图片
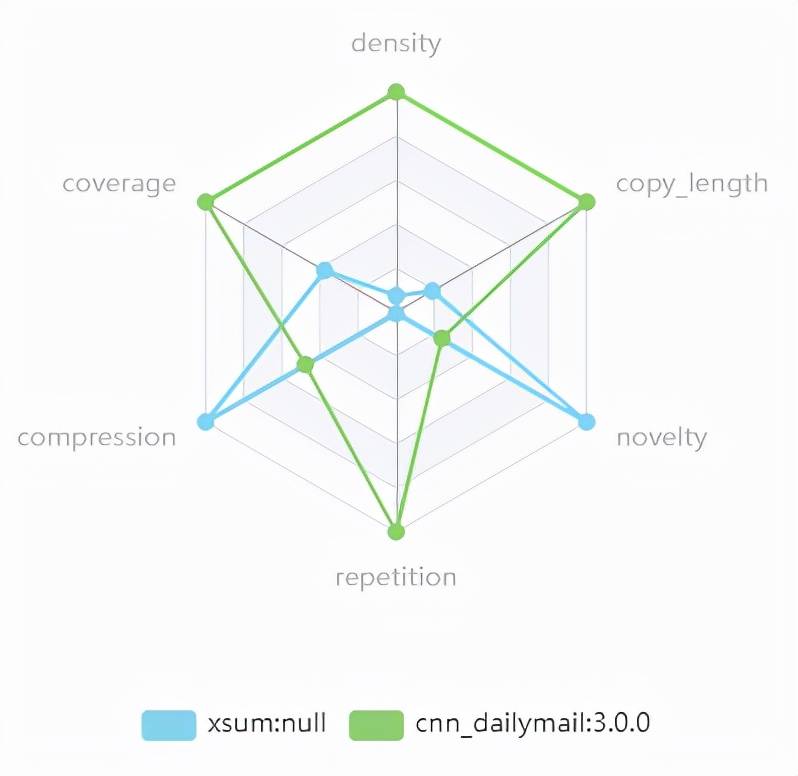
文章图片
5. 数据集推荐
我们常常有个好的 idea , 却不清楚应该选用哪些合适的数据集 , 随着越来越多的数据集被提出 , 如何为给定的应用选择正确的数据集变得更加困难 。
DataLab 尝试在这方面提供些帮助 。 具体说来 , 给定一个研究想法的描述 , DataLab 可以根据语义搜索出比较适配的数据集 , 并且给出排序得分 。 我们用一个例子测试对比了下 DataLab 和 Google Dataset Search:我们发现前者可以比较精准地找到一个符合描述的数据集 , 而 Google Dataset Search 直接失效 。
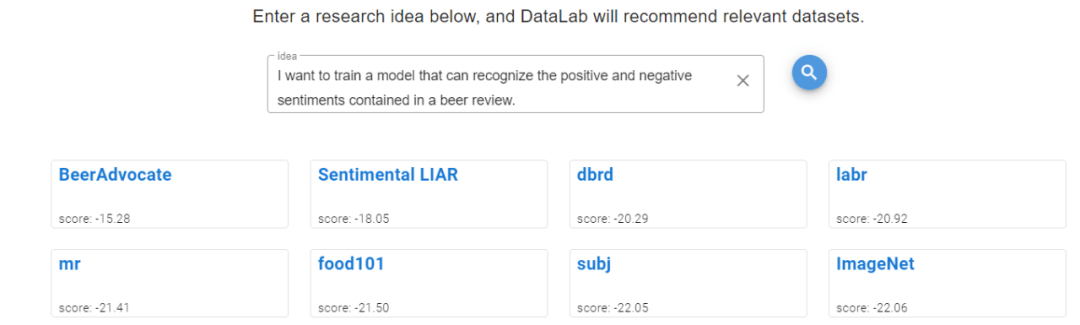
下图 6:DataLab 和 Google Dataset Search 对于同一个学术 idea 而推荐的数据集 。
文章图片
(a) DataLab 为给定的 idea 而推荐的数据集的结果页面 。

文章图片
(b)Google Dataset Search 为给定的 idea 的搜索结果(没有结果返回)
6. 全球视野分析
(1)语言地图
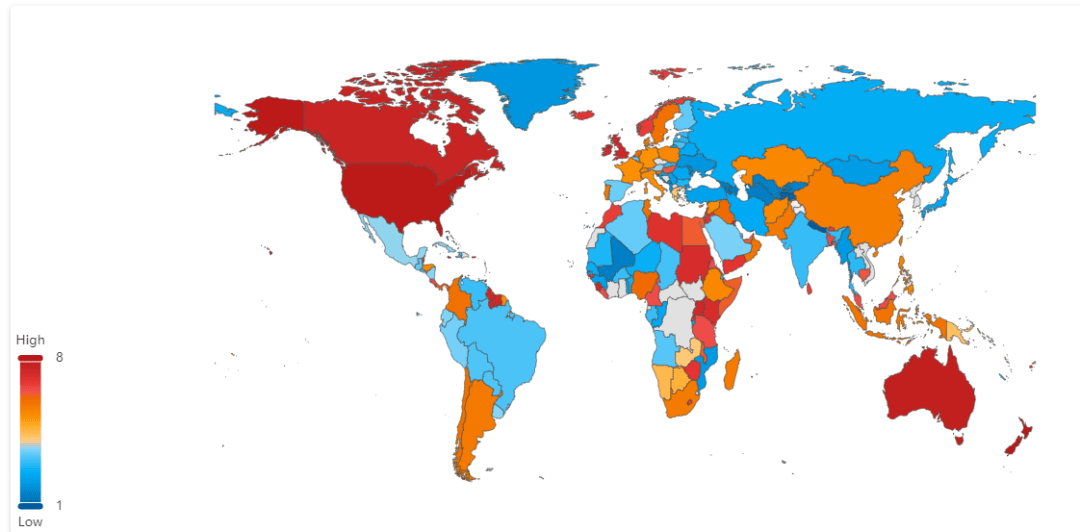
语言地图是用来从地理的角度分析哪些语言研究得多 , 哪些语言研究得少 , 从而告诉我们未来应该更关注构建哪些语言的数据集 。
如下图 7 , 颜色越红表示该国语言的数据集被研究得越多 。 我们可以很容易看出哪些国家语言的数据集很丰富(红色) , 相比而言 , 中文数据集是相对匮乏(橙色) 。
文章图片
图 7:语言地图
(2)NLP 模型谁家强?
以数据集为单位 , 根据依赖其实现模型性能的排序 , 以及对应的实现机构 , 我们可以对不同机构设计的 NLP 系统的性能上进行排序 , 并且判断不同机构更擅长的 NLP 任务 , 如下图 8 所示 。
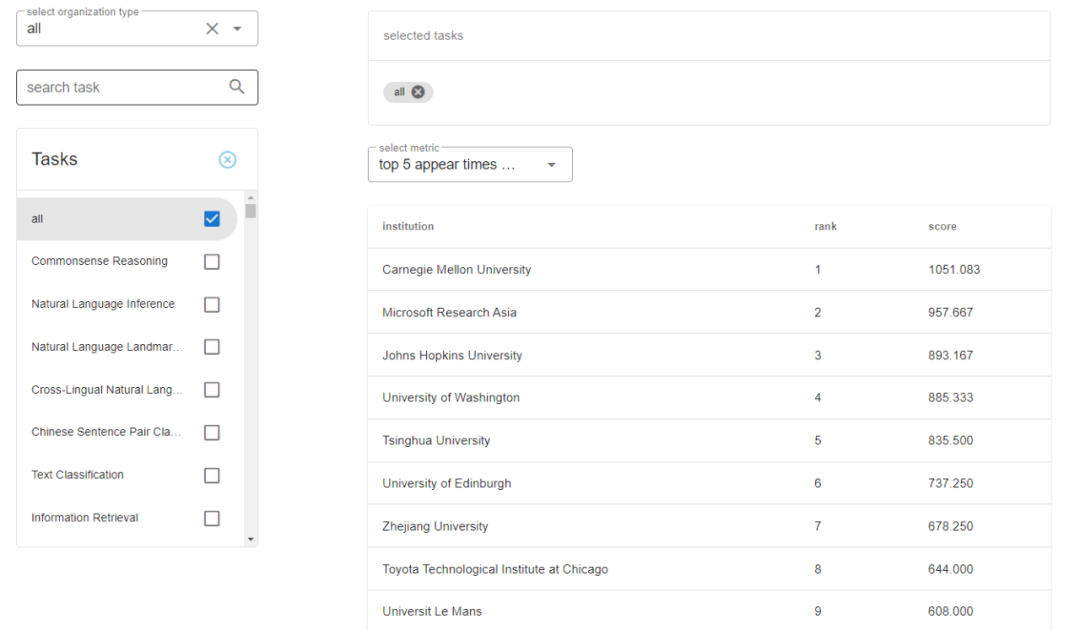
文章图片
图 8:全球机构在 NLP 系统性能上的排名
未来展望
我们希望平台的统一可以让集体智慧更容易发挥作用 。 未来 , DataLab 将继续向多个方向扩展:
- 探索并包含更多不同的数据类型 。 目前 , DataLab 仅包含文本类型的数据集 , 随着进一步优化 , DataLab 将逐渐支持其他领域不同类型的数据集 , 例如图像、多模态和声音等;
- 扩展更多的操作 。 目前 , DataLab 包含的操作有预处理、prompting、数据编辑等操作 。 随着引入不同任务的系统 , DataLab 有望探索系统组合等技术 , 实现高精度的自动数据标注 , 从而一定程度上为用户减少数据标注的成本;
- 促进该领域更好的进步 。 不同平台的统一能够让用户快速找到相关数据集(数据集推荐) , 定位合适的数据集(数据可理解性) , 快速进行数据的处理(预处理、prompting 等) , 从而一定程度上让学术研究更容易 。
[1] https://www.tensorflow.org/datasets
[2] Datasets: A Community Library for Natural Language Processing
[3] PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
[4] Annotation Artifacts in Natural Language Inference Data
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。