在实现过程中, 该研究采用了简单有效的自底向上层级 K-means 算法, 具体算法流程如下:

文章图片
在该训练框架中 , 每进行一轮学习后 , 由于网络参数的更新 , 图像的表征也随之更新 。
因此 , 在每个训练epoch之前, 均通过当前的网络参数提取整个数据集的图像表征 , 对提取到的图像表征应用如上所述的层级 K-means 算法得到一系列具有树状结构的层级原型, 这些层级原型将在接下来的训练过程中用于指导对比学习的样本选择 , 从而将层级化的语义信息融入到图像表征中 。
选择性对比学习
在得到了一系列具备层级结构、潜在地表征某一类别的原型向量后, 可以基于这些原型向量选择更加符合语义结构的对比学习样本.
- 选择性实例对比学习
此前的方法 (如 NPID、MoCo 等) 将同一图像经过不同随机数据增强后的版本作为正样本对 , 而将不同图像作为负样本对 。 这样的方式存在一个关键的问题:所选择的负样本对可能属于相同类别 , 从而使得相同类别的样本在表征空间中互相远离 , 这将在某种程度上破坏模型所学习到的表征有效性 。
出现这一问题的根本原因在于没有额外的类别信息指导对负样本的选择 。 如果我们知道类别信息 , 则可以将同类负样本剔除 (这些同类负样本也可以称为假负样本) , 从而避免带来梯度噪声 。 在自监督的情况下 , 虽然没有准确的类别信息 , 但我们通过此前的层级聚类过程得到了一系列聚类标签 。 在这些聚类标签的帮助下, 可以近似地达到剔除假负样本的目的:如果一对样本属于相同的聚类中心, 则从负样本对中剔除即可 。
更进一步地 , 考虑到聚类标签的不确定性 , 该研究通过接受 - 拒绝采样的方式对负样本进行选择 。 对于一个图像表征z , 层级聚类的结果可以导出该图像在第l层所属的聚类中心
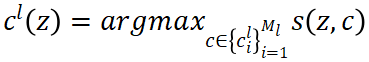
文章图片
(其中s(·)是相似度函数 , 在该研究中通过 cosine 相似度实现);这一聚类中心代表了该图像在这一层中所属的类别 。 接下来 , 对于候选负样本
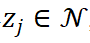
文章图片
, 它被选择的作为负样本的概率为:
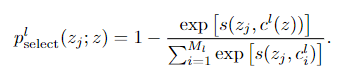
文章图片
直观而言, 一个候选负样本被选择的概率可以近似被描述为「与目标样本属于不同聚类中心的概率」经过选择过程后, 更高质量的负样本集 将被用于计算 InfoNCE 损失. 在多个层级聚类中心指导下, 最终的选择性实例对比学习 (Instance-wise Contrastive Selective Coding, ICSC) 的损失函数为:
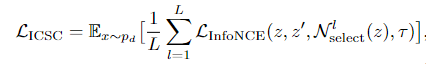
文章图片
- 选择性原型对比学习
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。