机器之心专栏
机器之心编辑部
来自上海交通大学、Mila 魁北克人工智能研究所以及字节跳动的研究者提出了一种具有层级语义结构的自监督表征学习框架 , 在 ImageNet 数据集上预训练的模型在多个下游任务中取得了 SOTA 性能 。层级结构无处不在 , 自然界中存在「界 - 门 - 纲 - 类 - 科 - 属 - 种」这样的层级关系, 大规模自然图像数据集中也天然存在 。 例如 , ImageNet 数据集的类别标签本身就是基于 WordNet 层级形成的, 我们总是可以「刨根问底」地找到某个类别的「父类」 。 举例而言 , 拉布拉多犬是一种犬类 , 而犬类又是一种哺乳动物 。 这就形成了拉布拉多犬 -> 犬类 -> 哺乳动物的层级关系 。

文章图片
近年来, 计算机视觉领域涌现出一大批有效的自监督预训练模型 , 如 NPID、SimCLR、MoCo 等 , 它们能够从大规模数据集中通过自监督的方式学习潜在的图像语义表征 , 从而提升预训练模型在各项下游任务(如物体分类、目标检测、语义分割)的迁移性能 。
这些自监督预训练框架通常基于对比学习实现. 对比学习通过定义正负样本对 , 并在表征空间中最大化正样本对之间的相似度而最小化负样本对之间的相似度, 从而达到「同类相吸、异类互斥」的目的 。 在不可获得分类标签的情况下 , NPID、MoCo、SimCLR 通过实例判别 (Instance Discrimination) 任务 , 将同一图像经过不同随机数据增强后作为正样本对 , 而将不同图像作为负样本对 , 从而学习对数据增强具有不变性的图像表征 。
然而, 现有的自监督对比学习框架存在两个问题:
- 缺乏对上述层级语义结构的建模;
- 负样本对的定义可能存在噪声:随机选择的两张图像可能属于相同类别 。

文章图片
- 论文地址: https://arxiv.org/abs/2202.00455
- 项目地址: https://github.com/gyfastas/HCSC
方法
文章图片
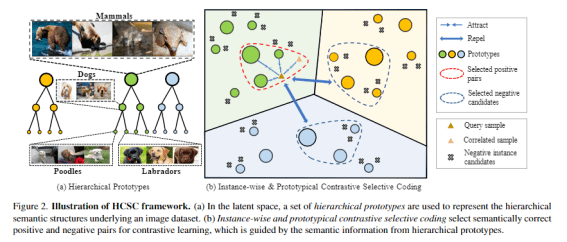
该工作的方法论框架包含两个重要的模块: 一个是层级语义结构的构建与维护, 另一个是基于层级语义结构的选择性对比学习 。
层级语义表征
研究者注意到 , 层级语义结构天然可以通过树状结构来描述:如果将树中的某个节点认为是一个语义类别, 则父节点可以认为是它的上层类别 , 例如「拉布拉多犬」的父节点可以认为是「犬类」 , 而其兄弟节点可以包括「贵宾犬」、「萨摩犬」等 。 这样的树状结构显然具备一个性质:同一父节点的两个子节点必然也共享更上层的祖先节点 , 例如「贵宾犬」与「萨摩犬」同为犬类, 它们也同为哺乳动物 。
那么 , 如何在图像的表征空间中构建这样的树状结构呢?在缺少类别标签的无监督场景中 , 可以通过对图像特征聚类的方式获得图像的潜在语义类别 。 聚类中心则可以被认为是代表着某种语义类别的「原型向量」 , 基于自底向上的层级聚类思想, 在这些聚类中心的基础上进一步进行聚类则可以得到更高层级的潜在语义类别 。 在这一过程中, 语义类别的树状结构自然地得以维护:在某层聚类中为相同类别的图像 , 在上层中仍然保持为相同类别 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。