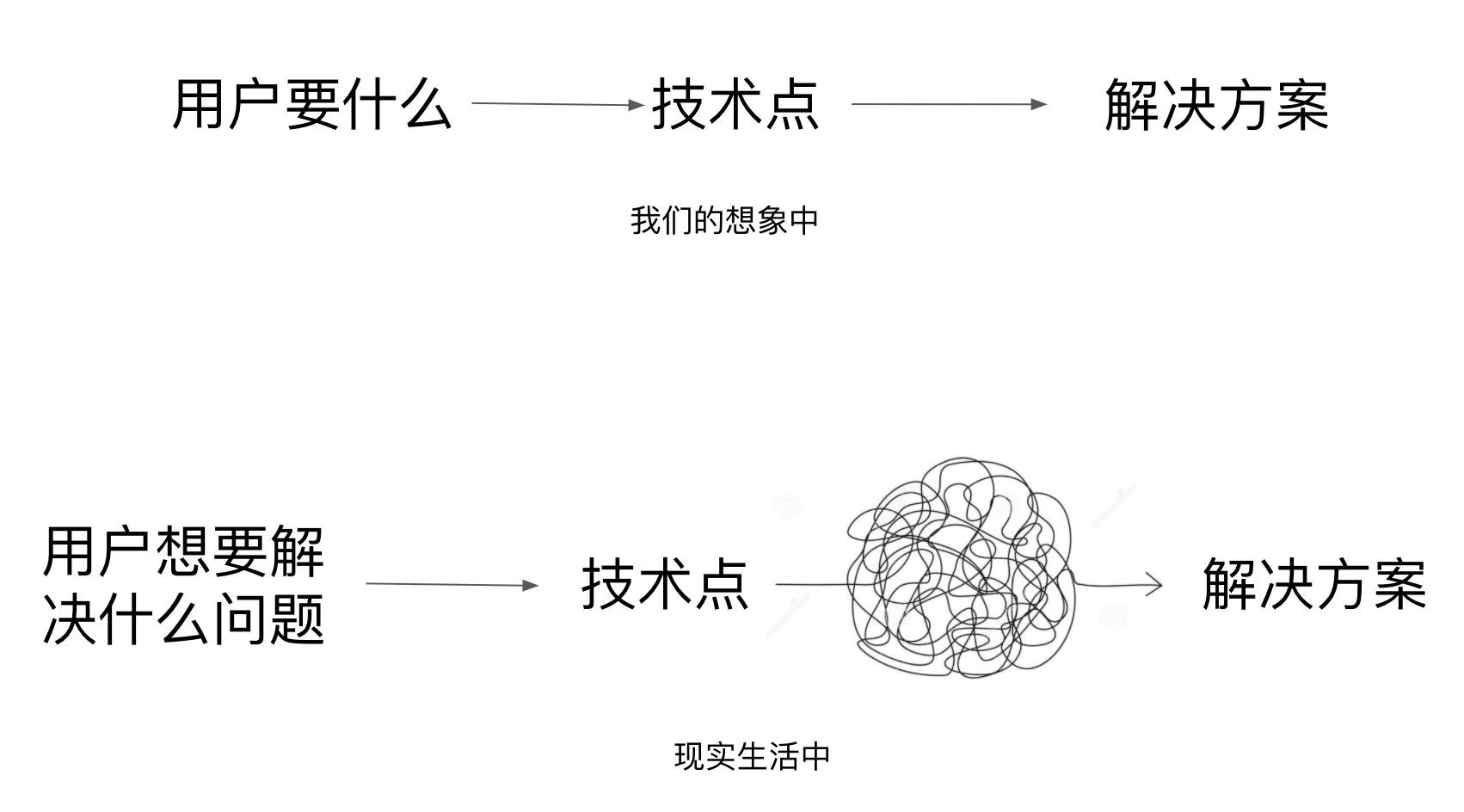
文章图片
优秀的基础软件产品经理通常会选择通用的技能点 , 用尽可能小的功能集合来包含更大的可能性(这样的灵活性是被鼓励的 , 例如:UNIX) , 所以这就对于基础软件厂商的售前和解决方案工程师提出了更高的要求:很多业务需要的「特性」是需要多个「技术点」组合出来的 , 或者通过引导到正确的问题从而提供更好的解决方案 。 下面我会通过几个例子来说明这个观点:
第一个例子 , 我们的经常被用户问到:TiDB 有没有多租户功能?
这个问题的我的回复并不是简单的「有」或者「没有」 , 而是会去挖掘用户真正想要解决的问题是什么?潜台词是什么?在多租户的例子中大概逃不出下面几种情况:
- 潜台词1:「每个业务都部署一套 TiDB , 太贵了」 , 价值点:节约成本
- 潜台词2:「我确实有好多套业务使用 TiDB, 对我来说机器成本不是问题 , 但是配置管理太麻烦 , 还要挨个升级 , 监控什么的还不能复用」 , 价值点:降低运维复杂度
- 潜台词3:「我有些场景特别重要 , 有些场景没那么重要 , 需要区别对待 , 对于不重要的我要共享 , 但是对于重要的要能隔离」 , 价值点:资源隔离+统一管控
- 潜台词4:「我有监管要求 , 例如不同租户的加密和审计」 , 价值点:合规
对于 TiDB 5.x 来说 , 大致有下面几个技术点和上面这个特性相关:
- Placement Rule in SQL(灵活的决定数据放置的功能)
- TiDB Operator on K8s
- XX(PingCAP 的一个新的产品 , 暂时还没发布 , 请期待 , 大致是一个多集群可视化管控的平台)
- TiDB Managed Cloud Service
下一步需要思考的是:世界上没有新鲜事 , 用户现在是通过什么办法解决这样的问题呢?
类似冷热分离这样的场景 , 我见过比较多的方案是冷数据用 HBase 或者其它比较低成本数据库方案(例如 MySQL 分库分表跑在机械磁盘上) , 热数据仍然放在 OLTP 数据库里 , 然后定期按照时间索引(或者分区)手动导入到冷数据集群中 。 这样对于应用层来说 , 就要知道的哪些数据去哪里查询 , 相当于需要对接两个数据源 , 而且这样的架构通常很难应对突发的冷数据读写热点(尤其是 ToC 端业务 , 偶尔会有一些「挖坟」的突发流量) 。
然后下一个问题是:我们的产品解决这个问题能给用户带来哪些不一样?如果还是需要用户手动做数据搬迁 , 或者搭建两个配置不同的 TiDB 集群 , 那其实没什么大的区别 , 在这个场景里面 , 如果 TiDB 能够支持异构集群 , 并且自动能将冷热数据固化在特定配置的机器上 , 同时支持冷数据到热数据自动交换 , 对用户来说体验是最好的:一个 DB 意味着业务的改动和维护成本最低 。 在 TiDB 5.4 里面发布了一个新的功能 , 叫做 Placement Rules in SQL, 这个功能可以让用户使用 SQL 声明式的决定数据的分布策略 , 自然可以指定冷热数据的分布策略 。 更进一步 ,对于多租户要求的更复杂数据分布方式 , 例如不同租户的数据放置在不同的物理机上 , 但是又能通过一个 TiDB 集群统一管控 , 通过 Placement Rules in SQL 这个功能也能实现 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。