本来在线下的分享中还有关于‘分库分表’ vs TiDB 的例子 , 因为篇幅关系就不展开了 , 感兴趣的可以按照上面的思路去思考 。
更隐式 , 但更大更长期的价值:可观测性和 Troubleshooting 能力
最后一部分 , 大家也能看到 , 最近其实我一直在努力的传达这个 Message , 对于一个基础软件产品来说 , 一个重要的长期竞争力和产品价值来自于可观测性和 Troubleshooting 能力 。 这个世界没有完美的软件 , 而且对于有经验的开发者来说 , 快速的发现和定位问题的能力是必备的 , 对于基础软件的商业化来说 , 服务支持效率和 Self-serving 也是规模化的基础 。 我这里说一些我们最近做的一些新的事情 , 以及未来面临的挑战 。
TiDB Clinic (tiup diag)
为什么要做这个事情?过去我们在做故障诊断的时候 , 是一个痛苦的过程 , 除了我在之前的关于可观测性的文章中提到的老司机的经验只在老司机脑子里的问题外 , 我观察到其实消耗时间的大头来自于收集信息 , 尤其是部署在用户自己的环境中 , 用户对于系统诊断并不熟悉 , 求助我们的服务支持的时候 , 经常的对话是:
服务支持:请运行这个命令 xxx , 然后告诉我结果
客户:(2小时后才给了结果)
服务支持:不好意思 , 麻烦在你们的监控界面上看某个指标的图表
客户:截图给你了
服务支持:不好意思的 , 时间段选错了 。。。 然后调整一下 grafana 的规则 , 再来一遍
客户:!@##¥#¥%
服务支持(隔了几天换了个人值班):请运行这个命令 xxx , 然后告诉我结果
客户:之前不是给过了吗?
这样一来一回异步又低效的问题诊断是很大的痛苦的来源 , 以及 oncall 没办法 scale 的核心原因之一 。 用户的痛点是:
- ‘你就不能一次性要完所有的信息吗?我并不知道给你哪些’
- ‘信息太大太多太杂 , 我怎么给你?’
- ‘我的 dashboard 在内网里 , 你看不到 , 我也只能截图’
- ‘我不能暴露业务信息 , 但是可以提交诊断信息’
- ‘原来猜测的方向不太对 , 需要另一些 metric 来验证’
- ‘无法完整重现故障现场的 metrics 和系统状态 , 我希望自由的操作Grafana’
- ‘不同的服务支持人员对于同一个用户的上下文共享’
- 通过 tiup 一键自动收集和系统诊断相关的各种指标
- 通过不断学习的规则引擎 , 自动化诊断一些常见错误
- 针对不同租户的诊断信息存储和回放平台(类似 SaaS)
对于用户来说 , 只需要在集群内执行一个简单的命令 , 就会生成上面这样的一个链接 , 把重要的诊断信息与 PingCAP 的专业服务支持人员共享 , 我们在后台可以看到:
文章图片
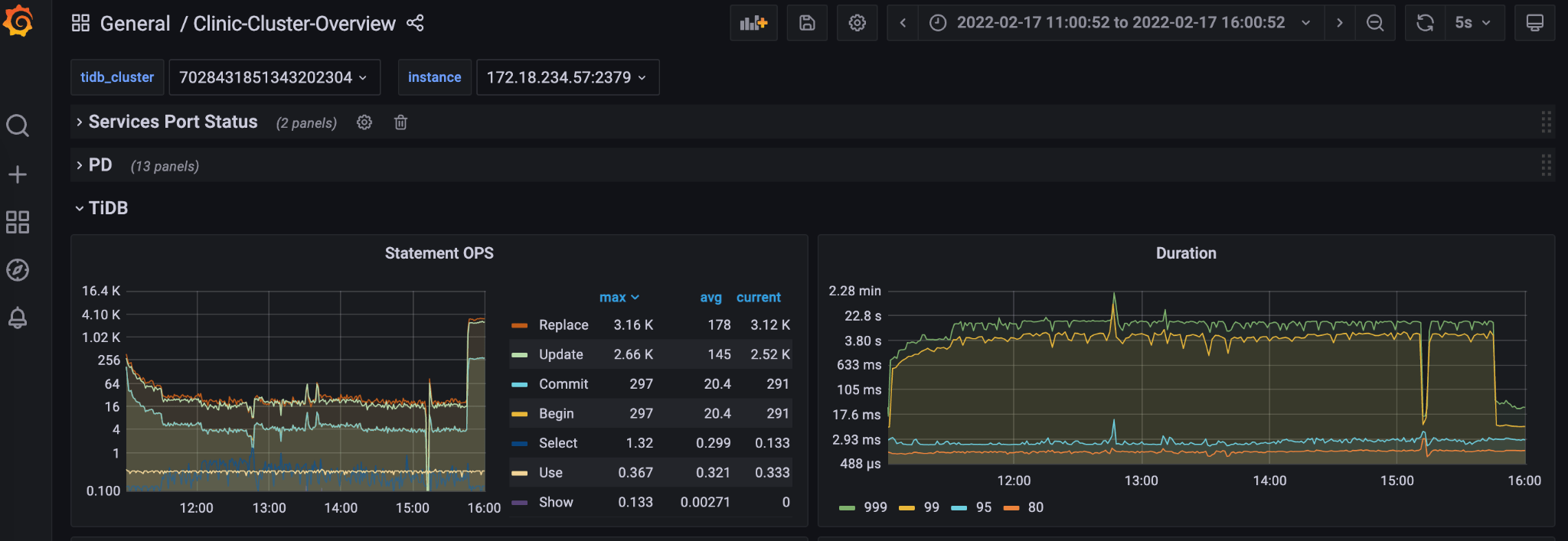
文章图片
其实 TiDB Clinic 也是对于基础软件的维护性的一个新尝试:诊断能力的 SaaS 化 , 通过一个在云端不断强化的规则引擎 , 将故障的诊断和修复建议和本地的运维部署结耦 。 这样的能力会变成用户选择 TiDB 的一个新的价值点 , 也是 TiDB 很强的生态护城河 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。