文章图片
首先 , 输入的文本和视频帧被传递给特征编码器进行特征提取 , 然后将两者连接成多模态序列(每帧一个) 。
接着 , 通过多模态Transformer对两者之间的特征关系进行编码 , 并将实例级(instance-level )特征解码为一组预测序列 。
接下来 , 生成相应的mask和参考预测序列 。
【打打字就能指挥算法视频抠图,Transformer掌握跨模态新技能,精度优于现有模型丨CVPR 2022】最后 , 将预测序列与基准(ground truth , 在有监督学习中通常指代样本集中的标签)序列进行匹配 , 以供训练过程中的监督或用于在推理过程中生成最终预测 。
具体来说 , 对于Transformer输出的每个实例序列 , 系统会生成一个对应的mask序列 。
为了实现这一点 , 作者采用了类似FPN(特征金字塔网络)的空间解码器和动态生成的条件卷积核 。
而通过一个新颖的文本参考分数函数 , 该函数基于mask和文本关联 , 就可以确定哪个查询序列与文本描述的对象具有最强的关联 , 然后返回其分割序列作为模型的预测 。
精度优于所有现有模型
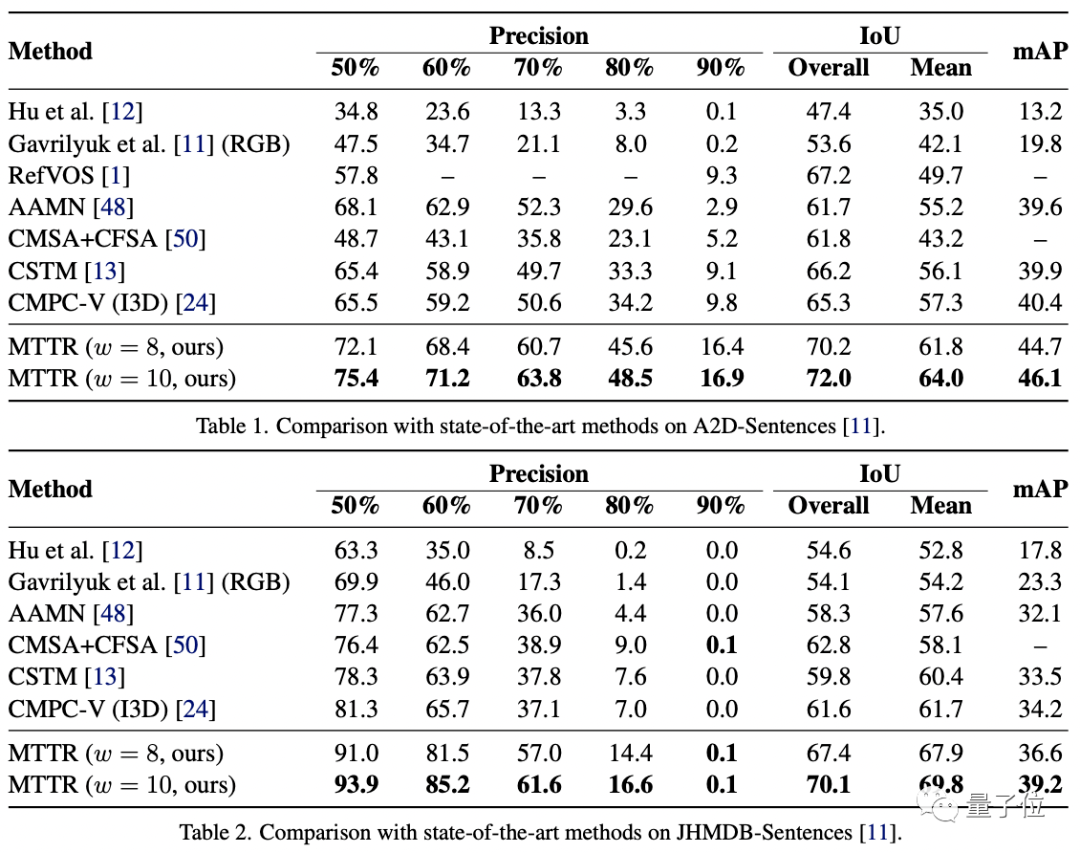
作者在三个相关数据集上对MTTR进行了性能测试:JHMDB-Sentences、 A2D-Sentences和Refer-YouTube-VOS 。
前两个数据集的衡量指标包括IoU(交并比 , 1表示预测框与真实边框完全重合)、平均IoU和precision@K(预测正确的相关结果占所有结果的比例) 。
结果如下:
文章图片
可以看到 , MTTR在所有指标上都优于所有现有方法 , 与SOTA模型相比 , 还在第一个数据集上提高了4.3的mAP值(平均精度) 。
顶配版MTTR则在平均和总体IoU指标上实现了5.7的mAP增益 , 可以在单个RTX 3090 GPU上实现每秒处理76帧图像 。
MTTR在JHMDBs上的结果表明MTTR也具备良好的泛化能力 。
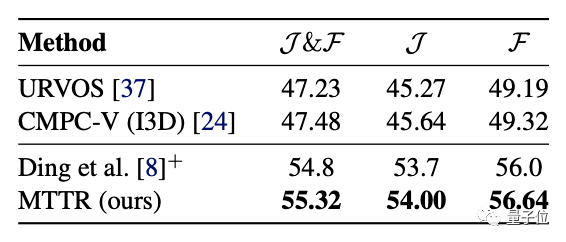
更具挑战性的Refer-YouTube-VOS数据集的主要评估指标为区域相似性(J)和轮廓精度(F)的平均值 。
MTTR在这些指标上全部“险胜” 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。