方法介绍
任务定义 。 RVOS 的输入为帧序列
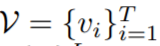
文章图片
, 其中
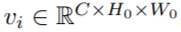
文章图片
;文本查询为
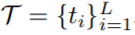
文章图片
, 这里t_i是文本中的第i个单词;大小为
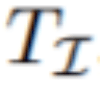
文章图片
的感兴趣帧的子集为
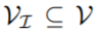
文章图片
, 目标是在每一帧
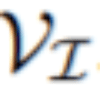
文章图片
中分割对象

文章图片
。
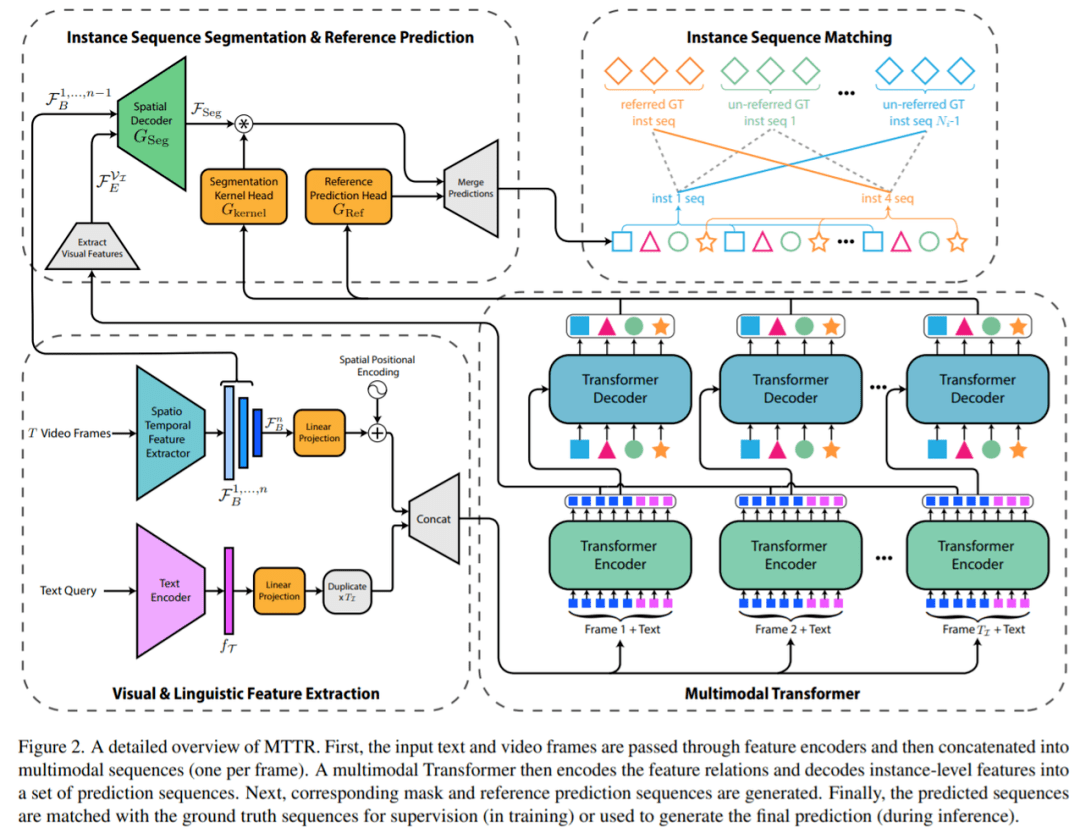
特征提取 。 该研究首先使用深度时空编码器从序列 V 中的每一帧中提取特征 。 同时使用基于 Transformer 的文本编码器从文本查询 T 中提取语言特征 。 然后 , 将空间-时间和语言特征线性投影到共享维度 D 。
实例预测 。 之后 , 感兴趣的帧特征被平化(flattened)并与文本嵌入分开连接 , 产生一组T_I多模态序列 , 这些序列被并行馈送到 Transformer 。 在 Transformer 的编码器层中 , 文本嵌入和每帧的视觉特征交换信息 。 然后 , 解码器层对每个输入帧提供N_q对象查询 , 查询与实体相关的多模态序列 , 并将其存储在对象查询中 。 该研究将这些查询(在图 1 和图 2 中由相同的唯一颜色和形状表示)称为属于同一实例序列的查询 。 这种设计允许自然跟踪视频中的每个对象实例 。
输出生成 。 Transformer 输出的每个实例序列 , 将会生成一个对应的掩码序列 。 为了实现这一点 , 该研究使用了类似 FPN 的空间解码器和动态生成的条件卷积核 。 最后 , 该研究使用文本参考评分函数(text-reference score function) , 该函数基于掩码和文本关联 , 以确定哪个对象查询序列与 T 中描述的对象具有最强的关联 , 并将其分割序列作为模型的预测返回 。
时间编码器 。 适合 RVOS 任务的时间编码器应该能够为视频中的每个实例提取视觉特征(例如 , 形状、大小、位置)和动作语义 。 相比之下 , 该研究使用端到端方法 , 不需要任何额外的掩码细化步骤 , 并使用单个主干就可完成 。 最近 , 研究者提出了 Video Swin Transformer [27] 作为 Swin Transformer 对视频领域的泛化 。 最初的 Swin 在设计时考虑了密集预测(例如分割) ,Video Swin 在动作识别基准上进行了大量测试 。
据了解 , 该研究是第一个使用Video Swin (稍作修改)进行视频分割的 。 与 I3D 不同 , Video Swin 仅包含一个时间下采样层 , 并且研究者可以轻松修改以输出每帧特征图 。 因此 , Video Swin是处理完整的连续视频帧序列以进行分割的更好选择 。
实例分割过程
实例分割过程如图 2 所示 。
文章图片
首先 , 给定 F_E , 即最后一个 Transformer 编码器层输出的更新后的多模态序列 , 该研究提取每个序列的视频相关部分(即第一个 H × W token)并重塑为集合
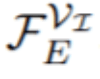
文章图片
。 然后 , 该研究采用时间编码器的前 n ? 1 个块的输出
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。