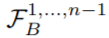
文章图片
, 并使用类似 FPN 的 [21] 空间解码器 G_Seg 将它们与
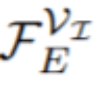
文章图片
分层融合 。 这个过程产生了视频帧的语义丰富、高分辨率的特征图 , 表示为 F_Seg 。
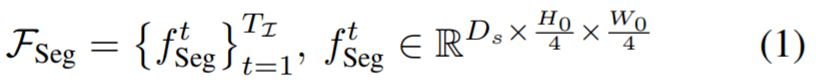
文章图片
接下来 , 对于 Transformer 解码器输出的每个实例序列
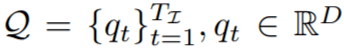
文章图片
, 该研究使用两层感知器 G_kernel 生成相应的条件分割核序列 。
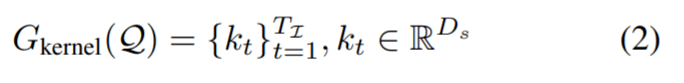
文章图片
最后 , 通过将每个分割核与其对应的帧特征进行卷积 , 为

文章图片
生成一系列分割掩码 M , 然后进行双线性上采样操作以将掩码大小调整为真实分辨率
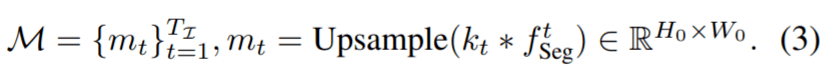
文章图片
实验
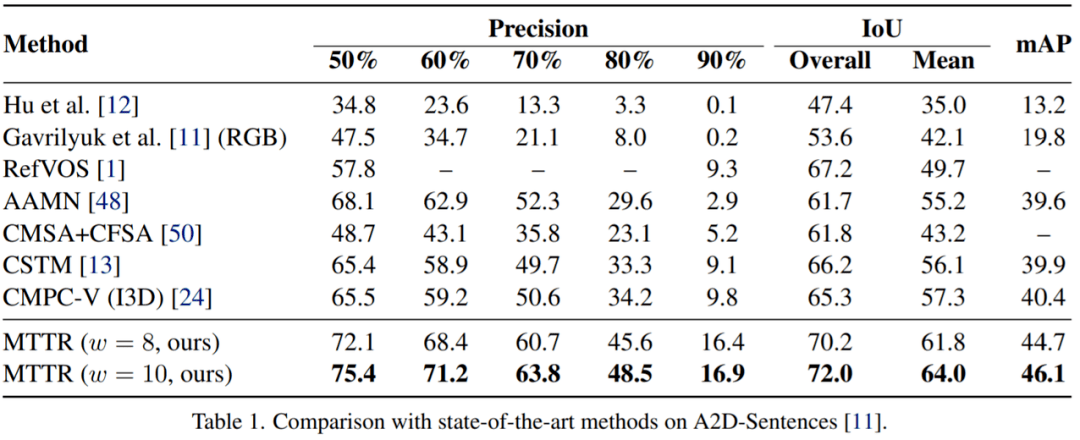
该研究在A2D-Sentences数据集上将MTTR与SOAT方法进行比较 。 结果如表 1所示 , 该方法在所有指标上都显着优于所有现有方法 。
例如 , 该模型比当前SOTA模型提高了 4.3 mAP, 这证明了MTTR能够生成高质量的掩码 。 该研究还注意到 , 与当前SOTA技术相比 , 顶级配置(w = 10)的MTTR实现了 5.7 的 mAP 提高和 6.7% 的平均 IoU 和总体 IoU 的绝对改进 。 值得一提的是 , 这种配置能够在单个 RTX 3090 GPU 上每秒处理 76 帧的同时做到这一点 。
文章图片
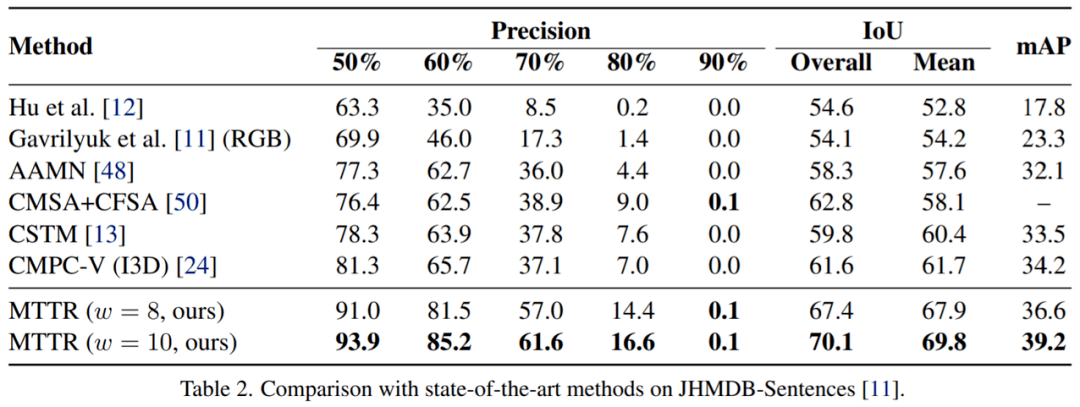
按照之前的方法 [11, 24] , 该研究通过在没有微调的 JHMDBSentences 上评估模型的泛化能力 。 该研究从每个视频中统一采样三帧 , 并在这些帧上评估模型 。 如表2所示 , MTTR方法具有很好的泛化性并且优于所有现有方法 。
文章图片
表3报告了在Refer-YouTube-VOS公共验证集上的结果 。 与现有方法[24,37]相比 , 这些方法是在完整数据集上进行训练和评估的 , 尽管该研究模型在较少的数据上进行训练 , 并专门在一个更具挑战性的子集上进行评估 , 但MTTR在所有指标上都表现出了卓越的性能 。

文章图片
如图 3 所示 , MTTR 可以成功地跟踪和分割文本参考对象 , 即使在具有挑战性的情况下 , 它们被类似实例包围、被遮挡或在视频的广泛部分中完全超出相机的视野 。

文章图片
参考链接:https://www.reddit.com/r/MachineLearning/comments/t7qe6b/r_endtoend_referring_video_object_segmentation/
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。