然而 , Assael等人意识到一个问题 , 这些记录通常都是不完整的 。 许多幸存下来的铭文在几个世纪的时间里遭到了破坏 , 或者从原来的位置被移走或者贩运 。 此外 , 现代年代测定技术 , 如放射性碳年代测定法 , 无法在这些材料上使用 。 而传统的铭文学方法涉及到高度复杂、耗时和专业的工作流程 , 这使得解读铭文既困难又费时 。
Assael对澎湃新闻采访人员表示 , 在将人工智能切入到铭文复原中 , 他们的工作涉及三项主要的任务 , “文本复原、确定原始的地理位置 , 以及追溯至铭文书写的时间 。 ”
他们在论文中也指出 , 受生物神经网络的启发 , 深度神经网络可以发现和利用大量数据中复杂的统计模式 。 而近年来计算能力的提高 , 使这些模型能够应对包括古代语言研究在内的许多领域中日益复杂的挑战 。
Assael将目标旨在完成上述三项任务的深度神经网络命名为伊萨卡(Ithaca) , 该工作始于2019年 。 “伊萨卡接受了近8万份由帕卡德人文学院(PHI , 一个非营利性基金会)提供的希腊铭文数字数据集的培训 , 它的架构旨在捕捉上下文并有效地处理受损的单词 , 同时它还可以并行地“注意”输入的不同部分 。 ”他表示 。
这些希腊铭文的时间跨度在公元前7世纪至公元5世纪 , 并横跨古地中海世界 。 论文中对这些铭文的选择做出2点解释 , “首先 , 希腊铭文记录的内容和语境的多样性 , 对语言处理构成了极大的挑战;其次 , 古希腊数字化语料库的可用性 , 这是训练机器学习模型的重要资源 。 ”
Assael提到 , 伊萨卡是一种基于Transformer的人工神经网络 , 它使用注意力机制来衡量输入的不同部分对模型决策过程的影响 。 相比于循环神经网(RNN)、卷积神经网络(CNN)等 , Transformer是一种新的神经网络结构 , 其仅基于注意力机制 , 抛弃了传统的循环或卷积神经网络结构 。
研究团队提到 , 自然语言处理模型通常使用单词进行训练 , 因为它们在句子中出现的顺序和它们之间的关系提供了额外的上下文和含义 。 例如 , “once upon a time”比单独看到的每个字符或单词有更多的含义 。 然而在这项研究中的挑战是 , 这些铭文都已损坏 , 而且经常丢失文本块 。
“为了确保模型在使用部分字符时仍能正常工作 , 我们既使用单词也使用单个字符输入来训练它 。 ”他们提到 , 模型核心的注意力机制并行地评估这两种输入 , 允许伊萨卡根据需要评估铭文 。
此外 , 为了最大化伊萨卡作为研究工具的价值 , 研究团队还开发了一些视觉辅助工具 , 以确保历史学家能够轻松地解释伊萨卡的结果 。
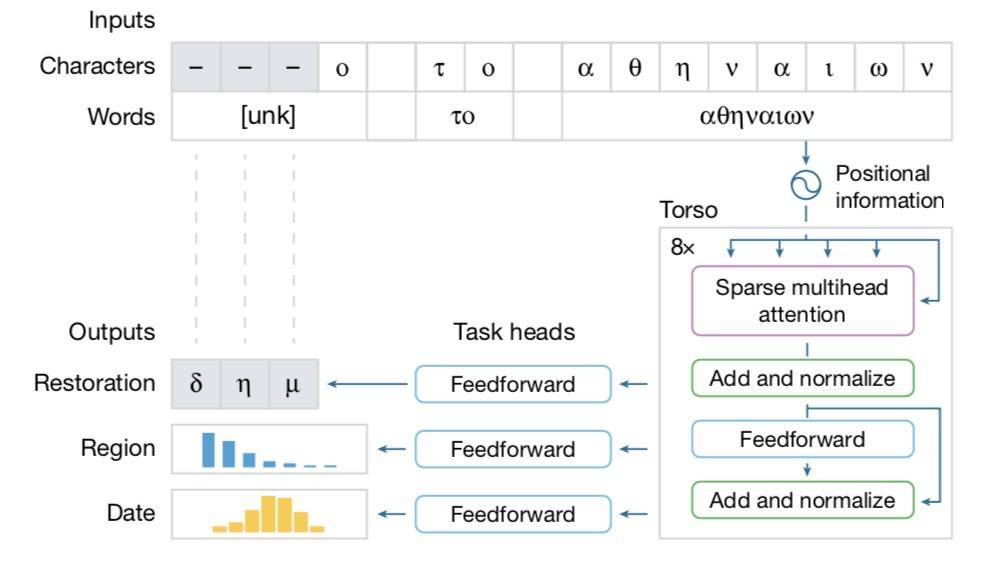
文章图片
伊萨卡处理δη?μο το αθηναι?ων’ (the people of Athens)的过程 。 该短语的前三个字符被隐藏 , 最终提出了修复建议 。 同时 , 伊萨卡还预测了铭文的地区和日期 。
希腊铭文复原仅有助于理解全球文明图景的一部分
Assael对澎湃新闻采访人员表示 , 伊萨卡的目标是提高我们对古代史的理解 , 并为历史学家提供一个方便的工具来帮助他们的研究 。
“出于这个原因 , 为了让历史学家能够解释伊萨卡 , 我们创造了大量的可视化图像来呈现所有的伊萨卡推测 。 这些可视化技术允许专家们使用他们的背景知识来选择最合适的输出 , 并可能对未探索的历史见解有所启发 。 ”他进一步提到 。
论文中详细提到 , 对于复原任务 , 伊萨卡并不是提供单一的假设 , 而是提供了一组根据概率排序的前20个解码预测 。 在确定地理任务方面 , 伊萨卡在84个区域中对输入文本进行分类 , 并通过地图和条形图可视化地实现可能区域预测的排名列表 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。