关注我们
(本文阅读所需 4 分钟)
通过阅读本文 , 您将会了解到 Azure 机器学习的架构和概念 , 并且深入了解一些组件 , 以及它们如何协同来协助构建、部署和维护机器学习模型的过程 。
工作区
机器学习工作区是 Azure 机器学习的 top-level 资源 。 工作区可集中用于:
- 管理用于训练和部署模型的资源 , 例如:计算
- 存储使用 Azure 机器学习时创建的资产 , 包括:环境、实验、管道、数据集、模型、端点等等
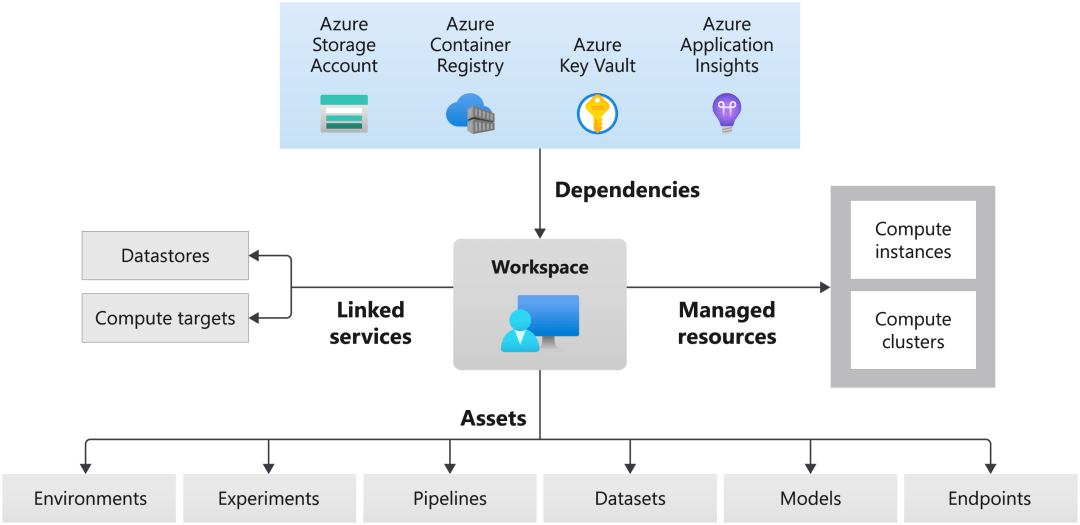
文章图片
计算
计算目标是用于运行训练脚本或托管服务部署的任何一台机器或一组机器 。 您可以使用本地计算机或远程计算资源作为计算目标 。 您可以使用计算目标在本地机器上训练 , 然后扩展到云端 , 这个过程中无需更改训练脚本 。
Azure 机器学习引入了2个为机器学习任务配置的虚拟机 (VM) , 它们是完全托管且基于云的:
- 计算实例: 是一个 VM , 其中包括为机器学习安装的多个工具和环境 。 计算实例的主要用途是用于您的开发工作站 。 您无需设置即可开始运行示例 notebook 。 计算实例也可以用作训练和推理作业的计算目标 。
- 计算集群: 是具有多节点扩展能力的虚拟机集群 。 计算集群更适合大型作业和生产的计算目标 。 提交作业时 , 集群会自动扩展 。 它用作训练计算目标或用于开发/测试部署 。
Azure 机器学习数据集使您可以更轻松地访问和处理数据 。 通过创建数据集 , 您可以创建对数据源位置的引用及其元数据的副本 。 由于数据保留在其现有位置 , 因此您不会产生额外的存储成本 , 也不会面临数据源完整性的风险 。
数据存储将连接信息(例如您的订阅 ID 和 token 授权)存储在与工作区关联的 Key Vault 中 , 因此您可以安全地访问您的存储 , 而无需在脚本中对其进行 hard code 。
环境
环境是对机器学习模型进行训练或评分的环境的封装 。 环境指定了围绕训练和评分脚本的 Python packages、环境变量和软件设置 。
实验
实验是来自指定脚本的许多运行的分组 。 它始终属于工作区 。 当您提交运行时的时候 , 需要提供一个实验名称 。 运行信息存储在该实验下 。 如果您提交实验时该名称不存在 , 则系统会自动创建一个新实验 。
文章图片
【深入了解 Azure 机器学习的工作原理】模型
最简单的模型是一段接受输入并产生输出的代码 。 创建机器学习模型涉及选择算法、为其提供数据和调整超参数 。 训练是一个生成训练模型的迭代过程 , 它封装了模型在训练过程中学到的东西 。
您可以引入在 Azure 机器学习之外训练的模型 , 也可以通过向 Azure 机器学习中的计算目标提交实验运行来训练模型 。 有了模型之后就可以在工作区中注册模型 。
Azure 机器学习与框架无关 。 您可以使用任何流行的机器学习框架来创建模型 , 例如 Scikit-learn、XGBoost、PyTorch、TensorFlow 和 Chainer 。
部署
将已注册的模型部署为服务端点需要以下组件:
- 环境: 此环境封装了运行模型进行推理所需的依赖项
- 评分: 该脚本接受请求 , 使用模型对请求进行评分 , 并返回结果
- 推理配置: 推理配置指定将模型作为服务运行所需的环境、entry 和其他组件
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。