研究者还讨论了代码语言建模中使用的三种流行的预训练方法 , 具体如下图 2 所示 。

文章图片
评估设置
研究者使用外部和内部基准对所有模型展开了评估 。
外在评估 。 代码建模的最流行下游任务之一是给定自然语言描述的代码生成 。 遵循 Chen et al. (2021) , 他们在 HumanEval 数据集上评估了所有模型 。 该数据集上包含 164 个以代码注释和函数定义形式描述的提示 , 它们包括参数名称和函数名称以及用于判断生成代码是否正确的测试用例 。
内在评估 。 为了评估不同模型的内在性能 , 他们在一组未见过的 GitHub 存储库上计算了每种语言的困惑度 。 并且 , 为了防止 GPT-Neo 和 GPT-J 等模型在训练到测试的过程中出现数据泄露 , 他们在评估数据集上移除了在 Pile 训练数据集的 GitHub 部分出现的存储库 。
模型比较
研究者主要选取了自回归预训练语言模型 , 这类模型最适合代码完成任务 。 具体地 , 他们评估了 Codex , OpenAI 开发的这一模型目前部署在了现实世界 , 并在代码完成任务中展现出了卓越的性能 。 Codex 在 179GB(重复数据删除后)的数据集上进行训练 , 该数据集包含了 2020 年 5 月从 GitHub 中获得的 5400 万个公开 Python 存储库 。
至于开源模型 , 研究者比较了 GPT 的三种变体模型 ——GPT-Neo(27 亿参数)、GPT-J(60 亿参数)和 GPT-NeoX(200 亿参数) 。 其中 , GPT-NeoX 是目前可用的最大规模的开源预训练语言模型 。 这些模型都在 Pile 数据集上进行训练 。
目前 , 社区并没有专门针对多编程语言代码进行训练的大规模开源语言模型 。 为了弥补这一缺陷 , 研究者在 GitHub 中涵盖 12 种不同编程语言的存储库集合上训练了一个 27 亿参数的模型——PolyCoder 。
PolyCoder 的数据
原始代码库集合 。 研究者针对 12 种流行编程语言克隆了 2021 年 10 月 GitHub 上 Star 量超 50 的的最流行存储库 。 最开始未过滤的数据集为 631GB 和 3890 万个文件 。
接着进行数据预处理 。 PolyCoder 与 CodeParrot、Codex 的数据预处理策略的详细对比如下表 2 所示 。
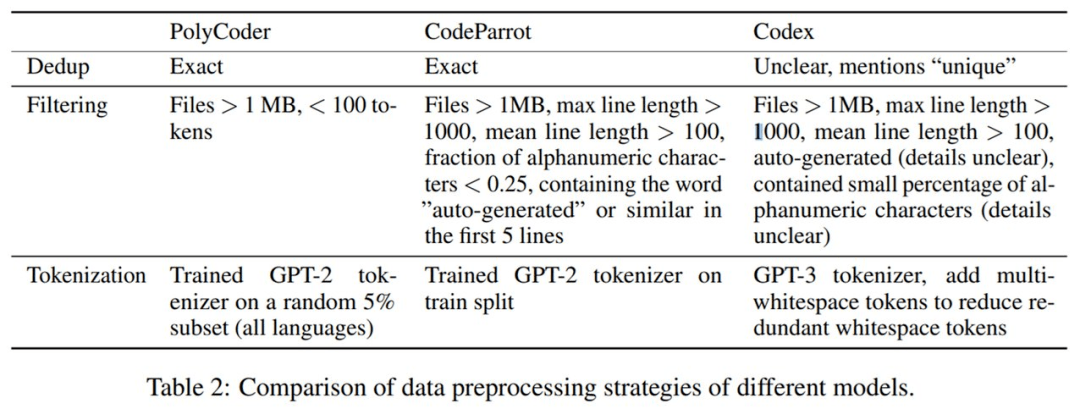
文章图片
最后是重复数据删除和过滤 。 整体来看 , 过滤掉非常大和非常小的文件以及删除重复数据 , 将文件总量减少了 38% , 数据集大小减少了 61% 。 下表 1 展示了过滤前后数据集大小的变化 。
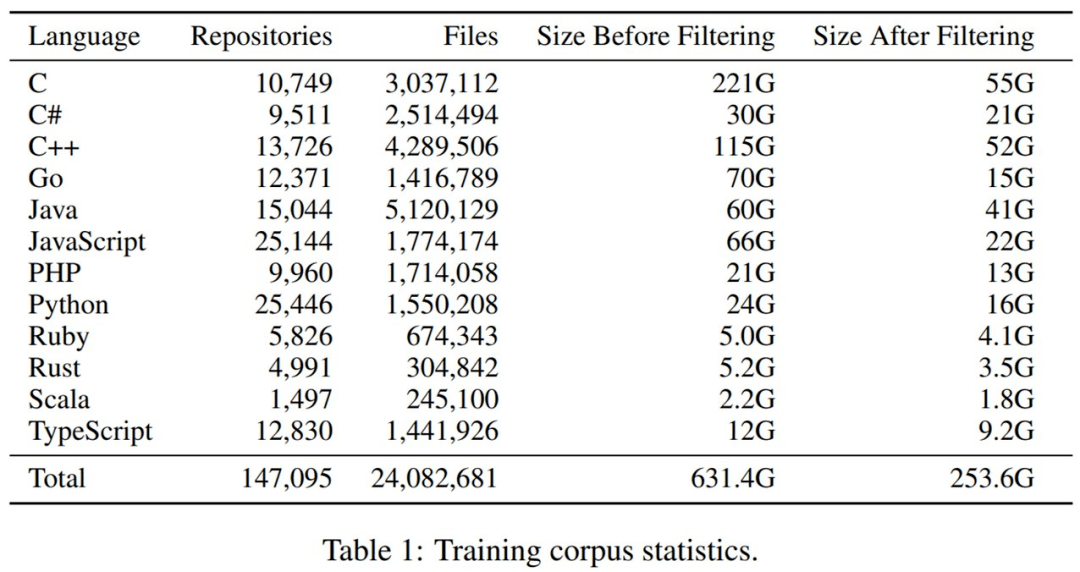
文章图片
PolyCoder 的训练
考虑到预算 , 研究者选择将 GPT-2 作为模型架构 。 为了探究模型大小缩放的影响 , 他们分别训练了参数量为 1.6 亿、4 亿和 27 亿的 PolyCoder 模型 , 并使用 27 亿参数的模型与 GPT-Neo 进行公平比较 。
研究者使用 GPT-NeoX 工具包在单台机器上与 8 块英伟达 RTX 8000 GPU 并行高效地训练模型 。 训练 27 亿参数 PolyCode 模型的时间约为 6 周 。 在默认设置下 , PolyCode 模型应该训练 32 万步 。 但受限于手头资源 , 他们将学习率衰减调整至原来的一半 , 训练了 15 万步 。
1.6 亿、4 亿和 27 亿参数量 PolyCode 模型的训练和验证损失曲线如下图 3 所示 。 可以看到 , 即使训练 15 万步之后 , 验证损失依然降低 。
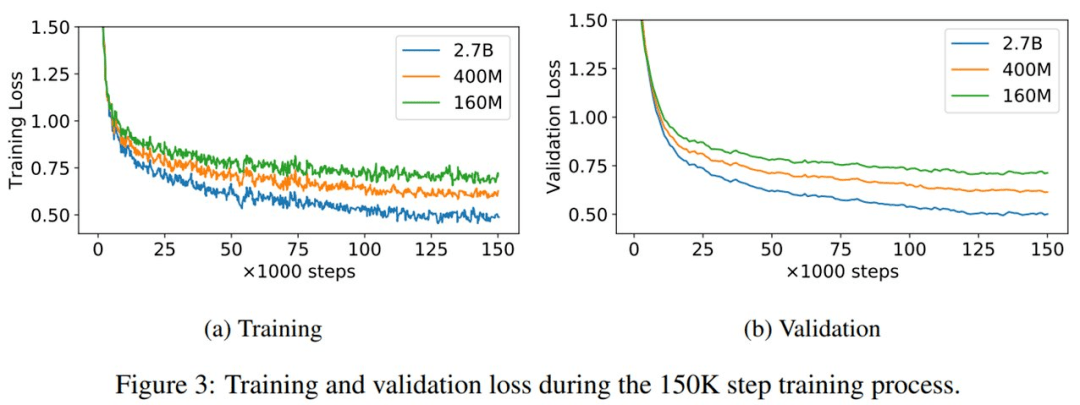
文章图片
下表 3 展示了训练不同代码模型中的设计决策和超参数比较情况 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。