文章图片
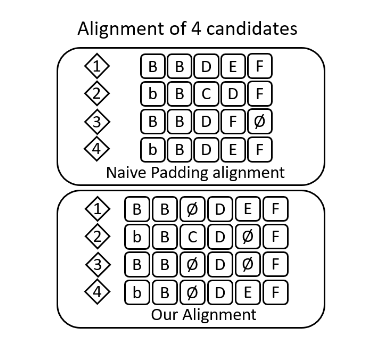
图五:简单补零和读音相似度对齐的对比 ,
可以看出 FastCorrect 2 在每个位置上的单词一致性更高 。
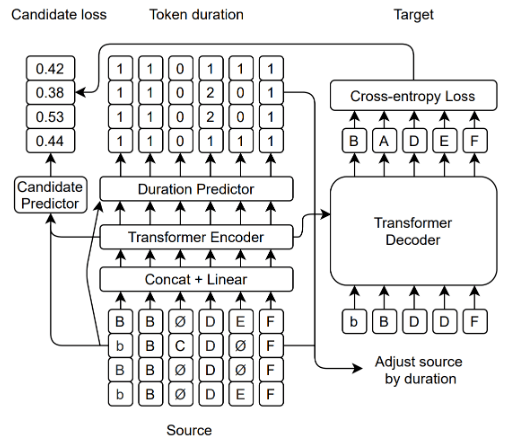
对于模型结构 , 研究员们也进行了改动 , 并引入了一个新模块:选择器(如图六) 。
1. 在编码器之前 , 新引入了一个 PreNet , 用来融合每个位置上不同单词的信息 。
2. 长度预测器需要对每个位置上的每一个单词 , 预测 Duration 。
3. 选择器则用来选择一个输入 , 这个输入会被调整(基于 Duration)并被送进解码器 , 选择器的训练目标是预测解码器的损失 , 因此选择器选择的是解码器损失最小的 , 也就是最容易被解码器修改的输入 。
文章图片
图六:FastCorrect 2 模型结构
实验表明 , 在开源学术数据集 AISHELL-1 和微软内部的产品数据集上 , FastCorrect 2 相对于 FastCorrect 都取得了较大的提升(如图七) , 而且模型的提升会随着输入的增多而不断增大 。
【语音识别的快速纠错模型FastCorrect系列来了!】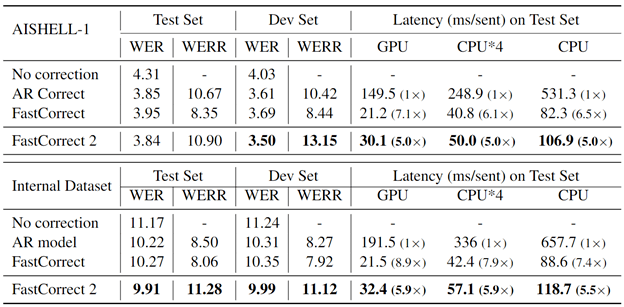
文章图片
图七:在 AISHELL-1 和微软内部的数据集上 ,
FastCorrect 2 和基线方法在词错误率和解码延迟上的对比 。
FastCorrect 系列工作的代码已经开源 , 开源链接:
- https://github.com/microsoft/NeuralSpeech
- https://github.com/microsoft/NeuralSpeech/tree/master/FastCorrect
- https://github.com/microsoft/NeuralSpeech/tree/master/FastCorrect2
论文链接:
- FastCorrect:Fast Error Correction with Edit Alignment for Automatic Speech Recognition https://arxiv.org/abs/2105.03842
- FastCorrect 2:Fast Error Correction on Multiple Candidates for Automatic Speech Recognition https://arxiv.org/abs/2109.14420
查看语音服务文档
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。