关注我们
(本文阅读时间:10分钟)
(转载自微软研究院AI头条)
语音识别支持着许多生活中的常见服务 , 比如手机端的语音转文字功能、视频网站的字幕自动生成等等 。 但语音识别模型往往并不完美 , 需要纠错模型来纠正语音识别中的错误 。 目前 , 大部分纠错模型采用了基于注意力机制的自回归模型结构 , 虽然能够提升语音识别的准确率 , 但是延迟较高 , 这也成为了纠错模型在实际应用中的瓶颈 。 一个直接的做法是利用非自回归模型来提升速度 , 但是简单利用当前的非自回归模型不能降低错误率 。 为此 , 微软亚洲研究院机器学习组与微软 Azure 语音团队合作 , 推出了 FastCorrect 系列工作 , 提出了低延迟的纠错模型 , 相关研究论文已被 NeurIPS 2021 和 EMNLP 2021 收录 。
纠错是语音识别中的一个重要后处理方法 , 旨在检测并纠正语音识别结果中存在的错误 , 从而进一步提升语音识别的准确率 。 许多纠错模型采用的是延迟较高的自回归解码模型 , 但是语音识别服务对模型的延迟有着严格的要求 , 在一些实时语音识别场景中(如会议同步语音识别) , 纠错模型无法上线应用 。 为了加速语音识别中的纠错模型 , 微软亚洲研究院的研究员们提出了一种基于编辑对齐(Edit Alignment)的非自回归纠错模型——FastCorrect , FastCorrect 在几乎不损失纠错能力的情况下 , 将自回归模型加速了6-9倍 。 考虑到语音识别模型往往可以给出多个备选识别结果 , 研究员们还进一步提出了 FastCorrect 2 来利用这些识别结果相互印证 , 从而得到了更好的性能 。 FastCorrect 1和2的相关研究论文已被 NeurIPS 2021 和 EMNLP 2021 收录 。 当前 , 研究员们还在研发 FastCorrect 3 , 在保证低延迟的情况下 , 进一步降低语音识别的错误率 。
FastCorrect :快速纠错模型
语音识别的纠错实际上是一个文本到文本的任务 , 模型训练的输入为语音识别结果文本 , 输出为真实文本 。 在自然语言处理领域(如机器翻译和文本编辑) , 已经有一些非自回归的快速模型被提出 。 但初步实验结果(如图一)显示 , 简单地将这些模型应用到语音识别的纠错任务中 , 并不能取得令人满意的结果 。 经过对语音识别的分析 , 研究员们发现语音识别中的错误比较稀疏 , 通常错误的单词数不到总单词数的10% , 而模型必须精准地找到并修改这些错误 , 同时还要避免修改正确的单词 , 这是语音识别的纠错任务中最大的挑战 。 而机器翻译中非自回归模型的主要问题是修改了太多原本是正确的单词 , 模型修改了原有错误的同时又引入了较多新的错误 , 因此无法提升语音识别的精度 。
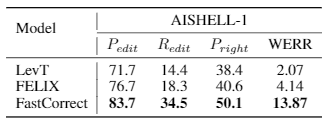
文章图片
图一:FastCorrect 和基线方法的错误检测率和错误改正率对比
考虑到语音识别的纠错输入输出的对应关系是单调的 , 所以如果可以在词的级别对齐输入和输出 , 就可以得到细粒度的错误信息:哪些词是错误的 , 这些错误的单词应该怎样修改 。 基于两个文本序列的编辑距离 , 研究员们设计了编辑对齐(Edit Alignment)算法(如图二) 。 给定输入(语音识别结果)和输出(真实文本) , 第一步是计算两个文本的编辑距离 , 然后可以得到数条编辑路径(Edit Path) , 路径中的元素为增加/删除/替换/不变四种操作之一 。 为了避免修改正确单词 , 包含“不变”操作最多的编辑路径会被选择 。 最终 , 基于编辑路径可以得到:对于每个输入的单词 , 哪些输出的单词与之对应 。 如果对应的输入输出单词不同 , 那么就表明输入单词是错误单词 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。