机器之心报道
编辑:陈萍、杜伟
虽然很方便 , 但遗憾的是 , 谷歌 Docs 的自动摘要生成功能仅向企业客户开放 。 希望个人用户也能尽快用到 。对我们很多人来说 , 每天都需要处理大量的文件 。 当收到一份新文件时 , 我们通常希望文件包含一个简要的要点总结 , 以便用户最快的了解文件内容 。 然而 , 编写文档摘要是一项具有挑战性、耗时的工作 。
为了解决这个问题 , 谷歌宣布 Google Docs 现在可以自动生成建议 , 以帮助文档编写者创建内容摘要 。 这一功能是通过机器学习模型实现的 , 该模型能够理解文本内容 , 生成 1-2 句自然语言文本描述 。 文档编写者对文档具有完全控制权 , 他们可以全部接收模型生成的建议 , 或者对建议进行必要的编辑以更好地捕获文档摘要 , 又或者完全忽略 。
用户还可以使用此功能 , 对文档进行更高层次的理解和浏览 。 虽然所有用户都可以添加摘要 , 但自动生成建议目前仅适用于 Google Workspace 企业客户(Google Workspace 是 Google 在订阅基础上提供的一套云计算生产力和协作软件工具和软件) 。 基于语法建议、智能撰写和自动更正 , 谷歌认为这是改善工作场所书面交流又一有价值的研究 。
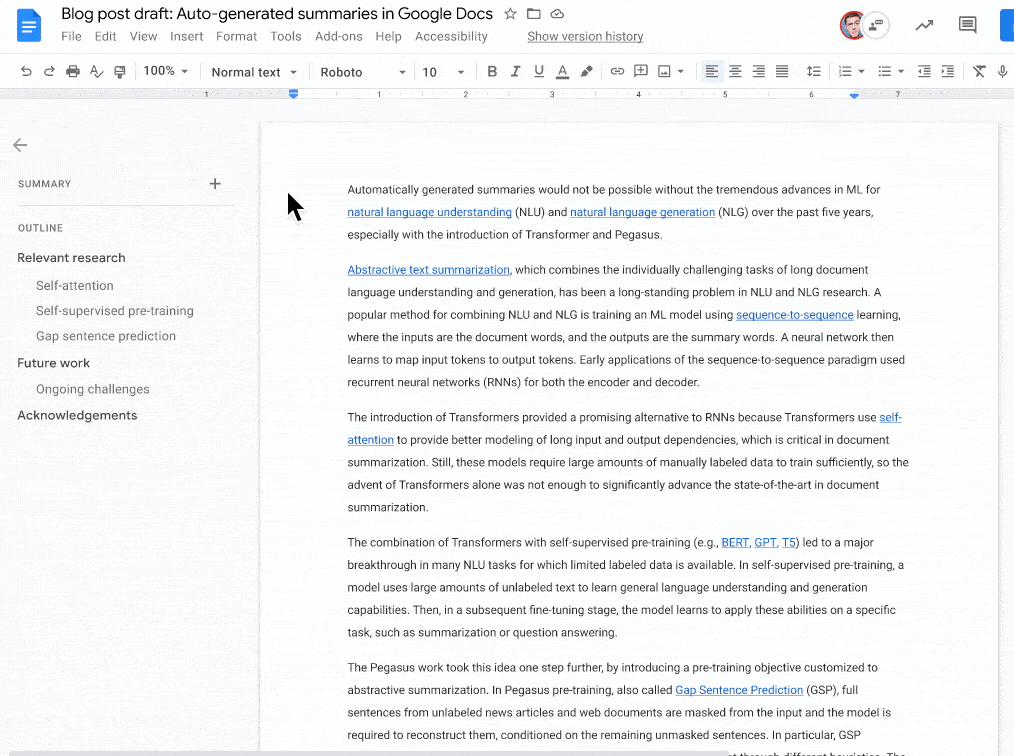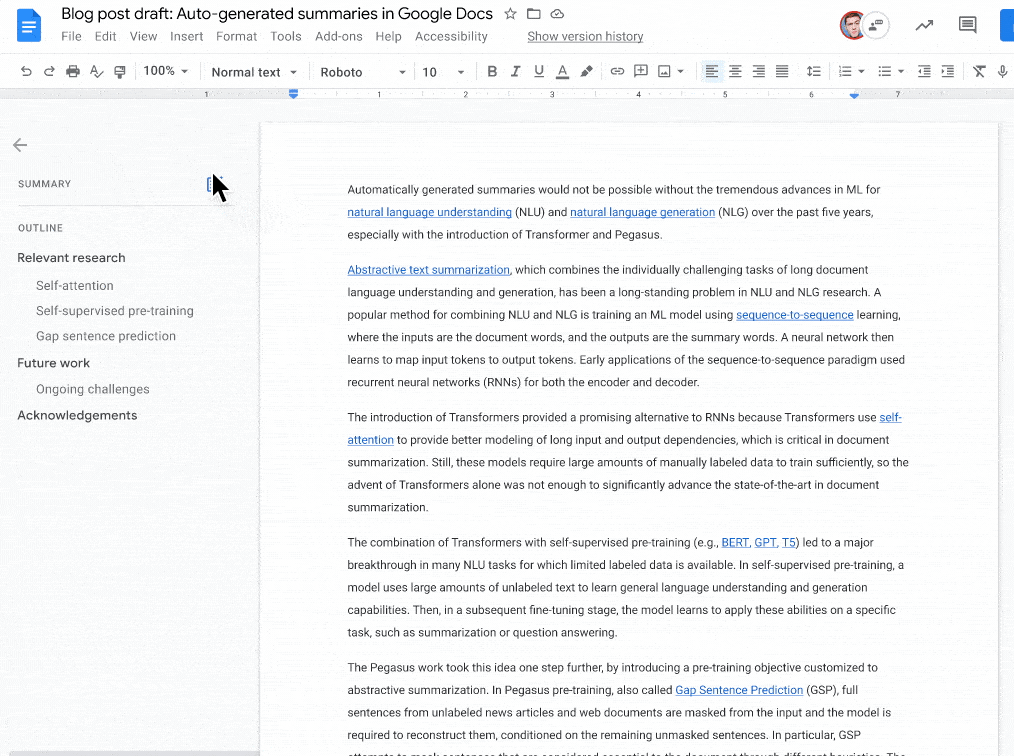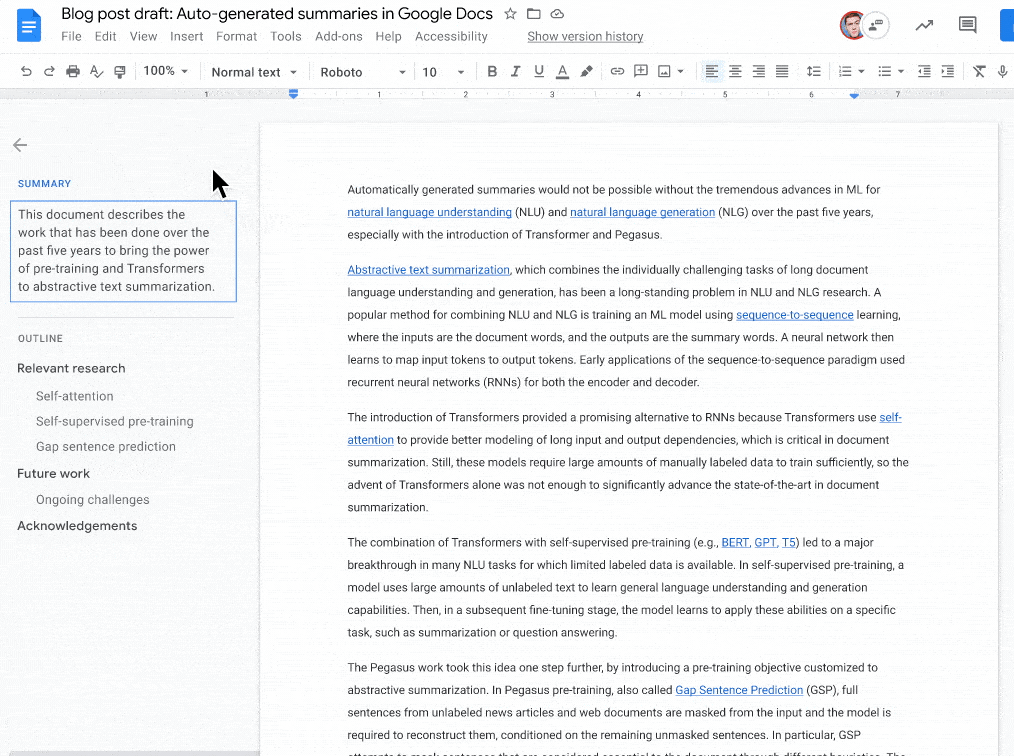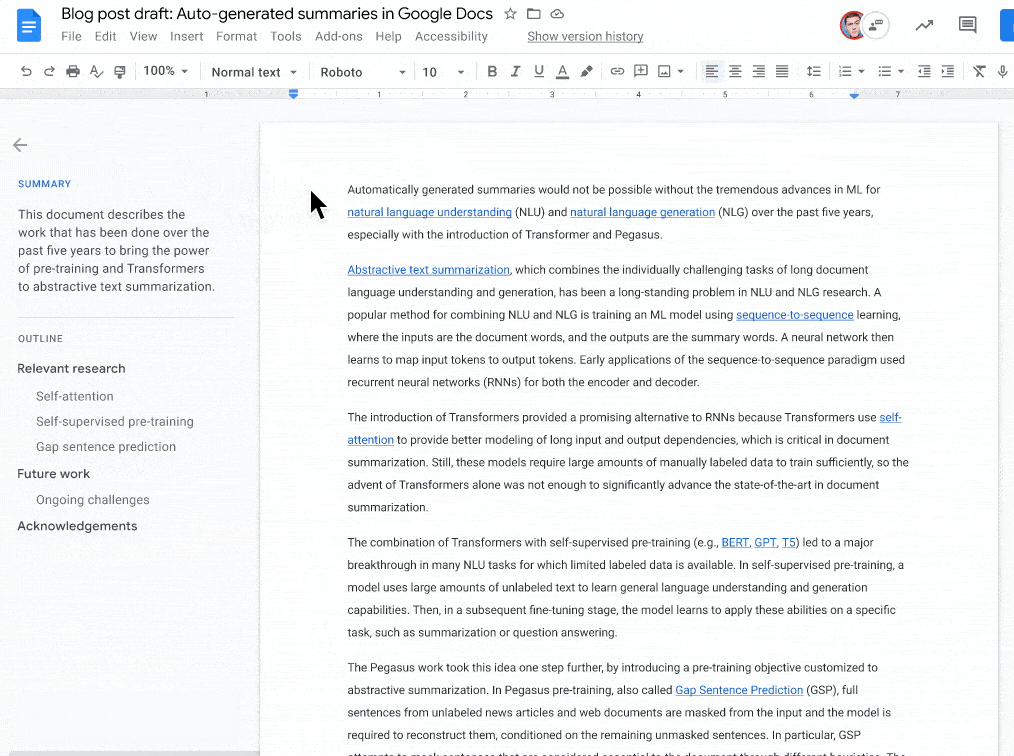
如下图所示:当文档摘要建议可用时 , 左上角会出现一个蓝色的摘要图标 。 然后 , 文档编写者可以查看、编辑或忽略建议的文档摘要 。
文章图片
模型细节
【谷歌Docs,现在已经可以自动生成文本摘要了】过去五年 , 特别是 Transformer 和 Pegasus 的推出 , ML 在自然语言理解 (NLU) 和自然语言生成 (NLG)方面产生巨大影响 。
然而生成抽象文本摘需要解决长文档语言理解和生成任务 。 目前比较常用的方法是将 NLU 和 NLG 结合 , 该方法使用序列到序列学习来训练 ML 模型 , 其中输入是文档词 , 输出是摘要词 。 然后 , 神经网络学习将输入 token 映射到输出 token 。 序列到序列范式的早期应用将 RNN 用于编码器和解码器 。
Transformers 的引入为 RNN 提供了一个有前途的替代方案 , 因为 Transformers 使用自注意力来提供对长输入和输出依赖项的更好建模 , 这在文档中至关重要 。 尽管如此 , 这些模型仍需要大量手动标记的数据才能充分训练 , 因此 , 仅使用 Transformer 不足以显着提升文档摘要 SOTA 性能 。
Pegasus 的研究将这一想法又向前推进了一步 ,该方法是在论文《PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization 》中提出 , 通过引入一个预训练目标自定义来抽象摘要 。 在 Pegasus 预训练中 , 也被称为 GSP(Gap Sentence Prediction ) , 未标记的新闻消息和网络文档中的完整句子在输入中被 mask 掉 , 模型需要根据未被 mask 掉的句子重建它们 。 特别是 , GSP 试图通过不同的启发式把对文档至关重要的句子进行 mask 。 目标是使预训练尽可能接近摘要任务 。 Pegasus 在一组不同的摘要数据集上取得了 SOTA 结果 。 然而 , 将这一研究进展应用到产品中仍然存在许多挑战 。
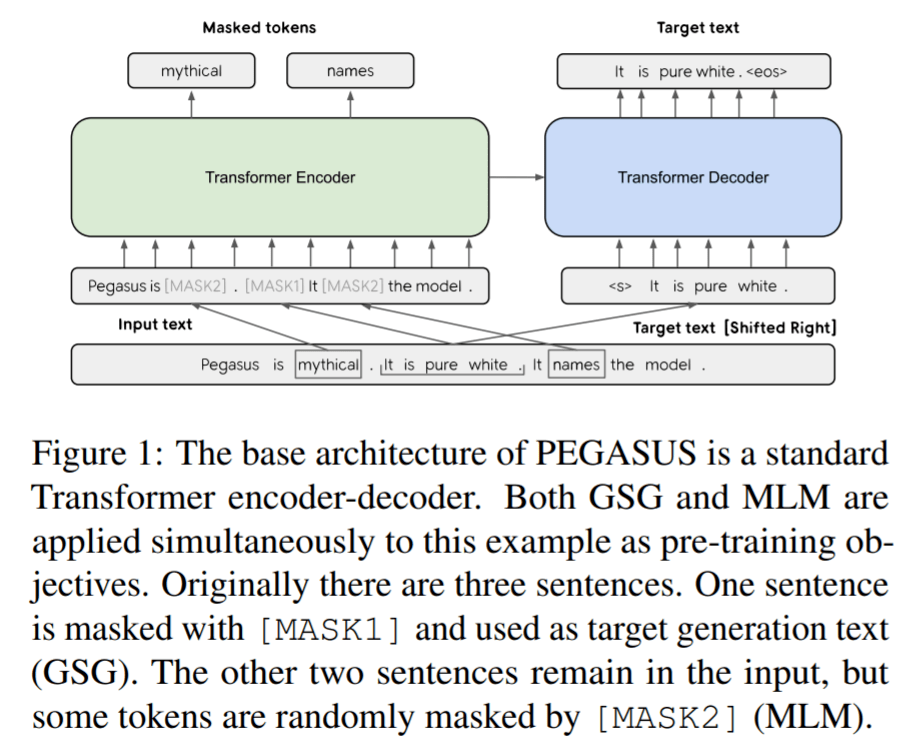
文章图片
PEGASUS 基础架构是标准的 Transformer 编码器 - 解码器 。
将最近的研究进展应用到 Google Docs
数据
自监督预训练生成的 ML 模型具有通用的语言理解和生成能力 , 但接下来的微调阶段对于该模型适应于应用领域至关重要 。 谷歌在一个文档语料库中对模型早期版本进行了微调 , 其中手动生成的摘要与典型用例保持一致 。 但是 , 该语料库的一些早期版本出现了不一致和较大变动 , 其原因在于它们包含了很多类型的文档以及编写摘要的不同方法 , 比如学术摘要通常篇幅长且详细 , 而行政摘要简短有力 。 这导致模型很容易混淆 , 因为它是在类型多样的文档和摘要上训练的 , 导致很难学习彼此之间的关系 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。