StarRocks 如何优化数据湖分析
大数据分析领域 , 数据除了存储在数仓之外 , 也会存储在数据湖当中 , 传统的数据湖实现方案包括 Hive/HDFS 。 近几年比较火热的是 LakeHouse 概念 , 常见的实现方案包括 Iceberg/Hudi/Delta 。 那么 StarRocks 能否帮助用户更好地挖掘数据湖中的数据价值呢?答案是肯定的 。
在前面的内容中我们介绍了 StarRocks 如何实现极速分析 , 如果将这些能力用于数据湖肯定会带来更好地数据湖分析体验 。 在这部分内容中 , 我们会介绍 StarRocks 是如何实现极速数据湖分析的 。
我们先看一下全局的架构 , StarRocks 和数据湖分析相关的主要几个模块如下图所示 。 其中 Data Management 由数据湖提供 , Data Storage 由对象存储 OSS/S3 , 或者是分布式文件系统 HDFS 提供 。
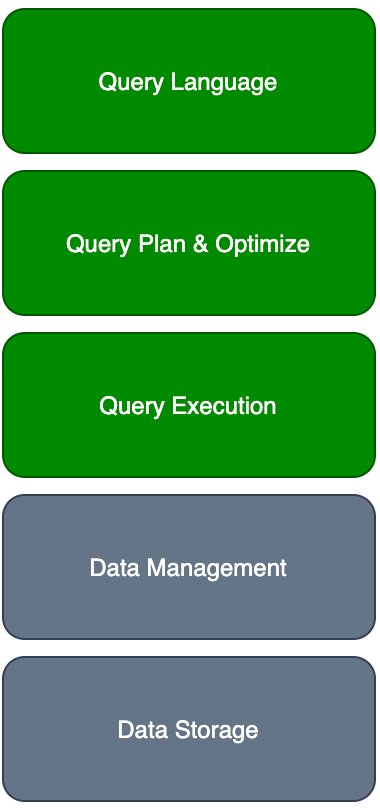
文章图片
目前 , StarRocks 已经支持的数据湖分析能力可以归纳为下面几个部分:
- 支持 Iceberg v1 表查询 https://github.com/StarRocks/starrocks/issues/1030
- 支持 Hive 外表查询 外部表 @ External_table @ StarRocks Docs (dorisdb.com)
- 支持 Hudi COW 表查询 https://github.com/StarRocks/starrocks/issues/2772
查询优化
查询优化这部分主要是利用前面介绍的 CBO 优化器来实现 , 数据湖模块需要给优化器统计信息 。 基于这些统计信息 , 优化器会利用一系列策略来实现查询执行计划的最优化 。 接下来我们通过例子看一下几个常见的策略 。
统计信息
我们看下面这个例子 , 生成的执行计划中 , HdfsScanNode 包含了 cardunality、avgRowSize 等统计信息的展示 。
MySQL [hive_test]> explain select l_quantity from lineitem;
+-----------------------------+
Explain String |
+-----------------------------+
PLAN FRAGMENT 0 |
OUTPUT EXPRS:5: l_quantity |
PARTITION: UNPARTITIONED |
RESULT SINK |
1:EXCHANGE |
PLAN FRAGMENT 1 |
OUTPUT EXPRS: |
PARTITION: RANDOM |
STREAM DATA SINK |
EXCHANGE ID: 01 |
UNPARTITIONED |
0:HdfsScanNode |
TABLE: lineitem |
partitions=1/1 |
cardinality=126059930 |
avgRowSize=8.0 |
numNodes=0 |
+-----------------------------+
在正式进入到 CBO 优化器之前 , 这些统计信息都会计算好 。 比如针对 Hive 我们有 MetaData Cache 来缓存这些信息 , 针对 Iceberg 我们通过 Iceberg 的 manifest 信息来计算这些统计信息 。 获取到这些统计信息之后 , 对于后续的优化策略的效果有很大地提升 。
分区裁剪
分区裁剪是只有当目标表为分区表时 , 才可以进行的一种优化方式 。 分区裁剪通过分析查询语句中的过滤条件 , 只选择可能满足条件的分区 , 不扫描匹配不上的分区 , 进而显著地减少计算的数据量 。 比如下面的例子 , 我们创建了一个以 ss_sold_date_sk 为分区列的外表 。
create external table store_sales(
ss_sold_time_sk bigint
, ss_item_sk bigint
, ss_customer_sk bigint
, ss_coupon_amt decimal(7,2)
, ss_net_paid decimal(7,2)
, ss_net_paid_inc_tax decimal(7,2)
, ss_net_profit decimal(7,2)
, ss_sold_date_sk bigint
) ENGINE=HIVE
PROPERTIES (
"resource" = "hive_tpcds",
"database" = "tpcds",
"table" = "store_sales"
);
在执行如下查询的时候 , 分区2451911和2451941之间的数据才会被读取 , 其他分区的数据会被过滤掉 , 这可以节约很大一部分的网络 IO 的消耗 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。