聚集索引的缺点
1.依赖于有序的数据 :因为 B+树是多路平衡树 , 如果索引的数据不是有序的 , 那么就需要在插入时排序 , 如果数据是整型还好 , 否则类似于字符串或 UUID 这种又长又难比较的数据 , 插入或查找的速度肯定比较慢 。 2.更新代价大 : 如果对索引列的数据被修改时 , 那么对应的索引也将会被修改 , 而且况聚集索引的叶子节点还存放着数据 , 修改代价肯定是较大的 , 所以对于主键索引来说 , 主键一般都是不可被修改的 。
非聚集索引
非聚集索引即索引结构和数据分开存放的索引 。
二级索引属于非聚集索引 。
MYISAM 引擎的表的.MYI 文件包含了表的索引 , 该表的索引(B+树)的每个叶子非叶子节点存储索引 , 叶子节点存储索引和索引对应数据的指针 , 指向.MYD 文件的数据 。
非聚集索引的叶子节点并不一定存放数据的指针 , 因为二级索引的叶子节点就存放的是主键 , 根据主键再回表查数据 。
非聚集索引的优点
更新代价比聚集索引要小 。 非聚集索引的更新代价就没有聚集索引那么大了 , 非聚集索引的叶子节点是不存放数据的
非聚集索引的缺点
1.跟聚集索引一样 , 非聚集索引也依赖于有序的数据2.可能会二次查询(回表) :这应该是非聚集索引最大的缺点了 。 当查到索引对应的指针或主键后 , 可能还需要根据指针或主键再到数据文件或表中查询 。
这是 MySQL 的表的文件截图:
文章插图
聚集索引和非聚集索引:
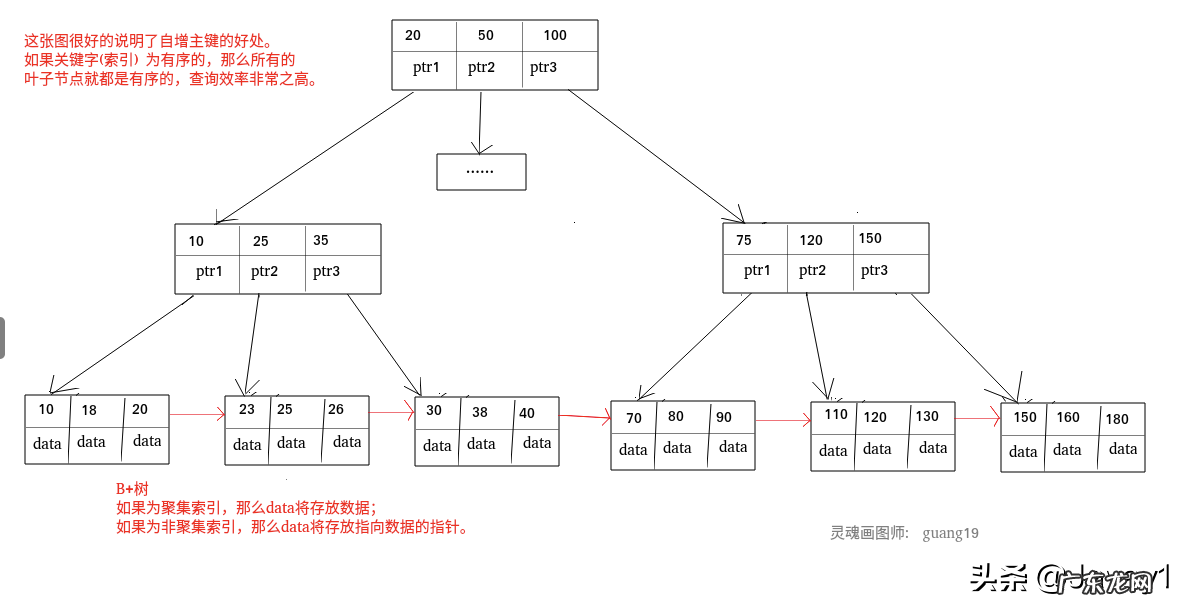
文章插图
非聚集索引一定回表查询吗(覆盖索引)?
非聚集索引不一定回表查询 。
试想一种情况 , 用户准备使用 SQL 查询用户名 , 而用户名字段正好建立了索引 。
SELECT name FROM table WHERE name=’guang19′;
那么这个索引的 key 本身就是 name , 查到对应的 name 直接返回就行了 , 无需回表查询 。
即使是 MYISAM 也是这样 , 虽然 MYISAM 的主键索引确实需要回表 , 因为它的主键索引的叶子节点存放的是指针 。 但是如果 SQL 查的就是主键呢?
SELECT id FROM table WHERE id=1;
主键索引本身的 key 就是主键 , 查到返回就行了 。 这种情况就称之为覆盖索引了 。
覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值 , 我们就称之为“覆盖索引” 。 我们知道在 InnoDB 存储引擎中 , 如果不是主键索引 , 叶子节点存储的是主键+列值 。 最终还是要“回表” , 也就是要通过主键再查找一次 。 这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的 , 不做回表操作!
覆盖索引即需要查询的字段正好是索引的字段 , 那么直接根据该索引 , 就可以查到数据了 , 而无需回表查询 。
如主键索引 , 如果一条 SQL 需要查询主键 , 那么正好根据主键索引就可以查到主键 。
再如普通索引 , 如果一条 SQL 需要查询 name , name 字段正好有索引 , 那么直接根据这个索引就可以查到数据 , 也无需回表 。
覆盖索引:
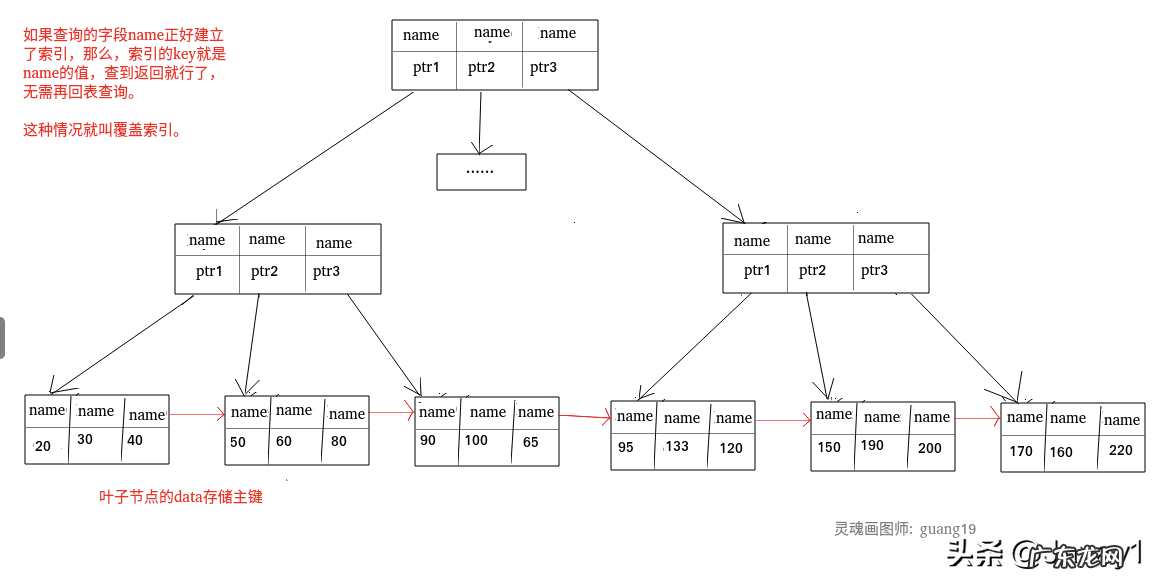
文章插图
创建索引的注意事项
1.选择合适的字段创建索引:
?不为 NULL 的字段 :索引字段的数据应该尽量不为 NULL , 因为对于数据为 NULL 的字段 , 数据库较难优化 。 如果字段频繁被查询 , 但又避免不了为 NULL , 建议使用 0,1,true,false 这样语义较为清晰的短值或短字符作为替代 。 ?被频繁查询的字段 :我们创建索引的字段应该是查询操作非常频繁的字段 。 ?被作为条件查询的字段 :被作为 WHERE 条件查询的字段 , 应该被考虑建立索引 。 ?频繁需要排序的字段 :索引已经排序 , 这样查询可以利用索引的排序 , 加快排序查询时间 。 ?被经常频繁用于连接的字段 :经常用于连接的字段可能是一些外键列 , 对于外键列并不一定要建立外键 , 只是说该列涉及到表与表的关系 。 对于频繁被连接查询的字段 , 可以考虑建立索引 , 提高多表连接查询的效率 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。