索引是一种用于快速查询和检索数据的数据结构 。 常见的索引结构有: B 树 , B+树和 Hash 。
索引的作用就相当于目录的作用 。 打个比方: 我们在查字典的时候 , 如果没有目录 , 那我们就只能一页一页的去找我们需要查的那个字 , 速度很慢 。 如果有目录了 , 我们只需要先去目录里查找字的位置 , 然后直接翻到那一页就行了 。
索引的优缺点
优点 :
?使用索引可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因 。 ?通过创建唯一性索引 , 可以保证数据库表中每一行数据的唯一性 。
缺点 :
?创建索引和维护索引需要耗费许多时间 。 当对表中的数据进行增删改的时候 , 如果数据有索引 , 那么索引也需要动态的修改 , 会降低 SQL 执行效率 。 ?索引需要使用物理文件存储 , 也会耗费一定空间 。
但是 , 使用索引一定能提高查询性能吗?
大多数情况下 , 索引查询都是比全表扫描要快的 。 但是如果数据库的数据量不大 , 那么使用索引也不一定能够带来很大提升 。
索引的底层数据结构
Hash表 & B+树
哈希表是键值对的集合 , 通过键(key)即可快速取出对应的值(value) , 因此哈希表可以快速检索数据(接近 O(1)) 。
为何能够通过 key 快速取出 value呢? 原因在于 哈希算法(也叫散列算法) 。 通过哈希算法 , 我们可以快速找到 value 对应的 index , 找到了 index 也就找到了对应的 value 。
hash = hashfunc(key)index = hash % array_size
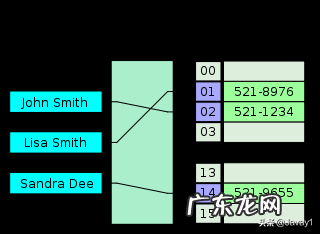
文章插图
但是!哈希算法有个 Hash 冲突 问题 , 也就是说多个不同的 key 最后得到的 index 相同 。 通常情况下 , 我们常用的解决办法是 链地址法 。 链地址法就是将哈希冲突数据存放在链表中 。 就比如 JDK1.8 之前 HashMap 就是通过链地址法来解决哈希冲突的 。 不过 , JDK1.8 以后HashMap为了减少链表过长的时候搜索时间过长引入了红黑树 。
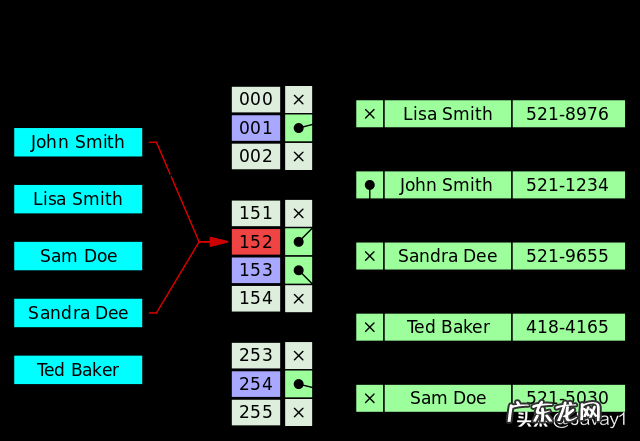
文章插图
为了减少 Hash 冲突的发生 , 一个好的哈希函数应该“均匀地”将数据分布在整个可能的哈希值集合中 。
【索引在目录的前面还是后面 索引与目录有什么区别】既然哈希表这么快 , 为什么MySQL 没有使用其作为索引的数据结构呢?
1.Hash 冲突问题 :我们上面也提到过Hash 冲突了 , 不过对于数据库来说这还不算最大的缺点 。
2.Hash 索引不支持顺序和范围查询(Hash 索引不支持顺序和范围查询是它最大的缺点: 假如我们要对表中的数据进行排序或者进行范围查询 , 那 Hash 索引可就不行了 。
试想一种情况:
SELECT * FROM tb1 WHERE id < 500;Copy to clipboardErrorCopied
在这种范围查询中 , 优势非常大 , 直接遍历比 500 小的叶子节点就够了 。 而 Hash 索引是根据 hash 算法来定位的 , 难不成还要把 1 – 499 的数据 , 每个都进行一次 hash 计算来定位吗?这就是 Hash 最大的缺点了 。
B 树& B+树
B 树也称 B-树,全称为 多路平衡查找树 , B+ 树是 B 树的一种变体 。 B 树和 B+树中的 B 是 Balanced (平衡)的意思 。
目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构 。
B 树& B+树两者有何异同呢?
?B 树的所有节点既存放键(key) 也存放 数据(data) , 而 B+树只有叶子节点存放 key 和 data , 其他内节点只存放 key 。 ?B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点 。 ?B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找 , 可能还没有到达叶子节点 , 检索就结束了 。 而 B+树的检索效率就很稳定了 , 任何查找都是从根节点到叶子节点的过程 , 叶子节点的顺序检索很明显 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。