下图 1 为这种方法的示意图:
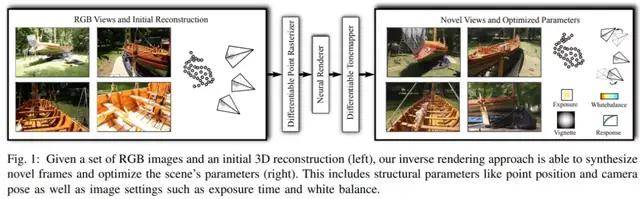
文章图片
完整的端到端可训练神经渲染 pipeline 如下图 2 所示 , 其中输入为新帧的相机参数、一个点云(每个点被分配给可学得的神经描述器)和一个环境图 , 输出为给定新视点的 LDR 场景图像 。 由于所有步骤都是可微的 , 因此可以同时对场景结构、网络参数和传感器模型进行优化:
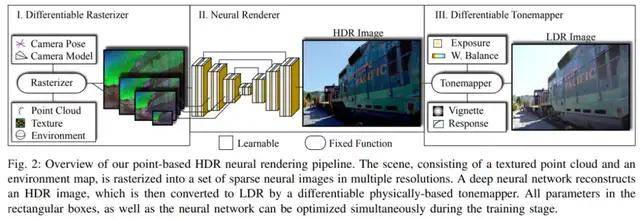
文章图片
具体地 , 该 pipeline 的第一个步骤是可微的栅格化单元(图 2 左) , 通过使用相机参数将每个点映射到图像空间 , 进而将该点渲染为单像素大小的 splat;
神经渲染器(图 2 中)使用多分辨率神经图像来生成单个 HDR 输出图像 , 它包含一个具有跳跃连接的四层全卷积 UNet , 其中更低像素的输入图像连接到中间特征向量;
该 pipeline 的最后一个步骤(图 2 右)是可学得的色调映射操作器 , 它将渲染的 HDR 图像转换为 LDR 。 这个色调映射器模拟了数码相机的物理镜头和传感器特性 , 因此最适合智能手机、DSL 相机和摄像机的 LDR 图像捕捉 。
可微的单像素点渲染
如上所述 , 可微的栅格化单元使用单像素大小的 splat 对多分辨率的变形点云进行渲染 。 形式上来讲 , 神经图像 I 的分辨率层 l ? {0,1...,L?1} 的是渲染器函数Φ_l 的输出 , 如下公式(1)所示:
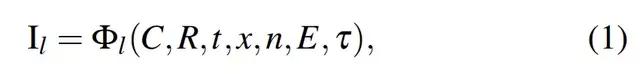
文章图片
点栅格化的前向传递可以分解为三个主要步骤 , 分别是映射、遮挡检查和混合 。 下图 3 展示了使用单像素点栅格化方法渲染的两张彩色图像的示意图:

文章图片
点栅格化单元的后向传递首先计算参数相关的渲染器函数(1)的偏导数 , 如下公式(8)所示 。 使用链式法则 , 研究者可以计算损失梯度并传递到优化器 。

文章图片
如下图 4 所示 , 研究者通过在每个方向上将 p = (u, v) 移动一个像素来计算近似值 。
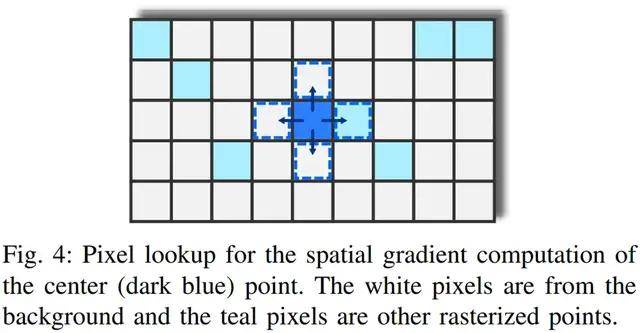
文章图片
在下图 5 中 , 在混合阶段前插入一个 dropout 层 , 该层将点云分割为两个集 。 第一个集正常地混合 , 并生成输入图像;第二个集 , 研究者称之为假性触控点(ghost point) , 不在前向传递中使用 。
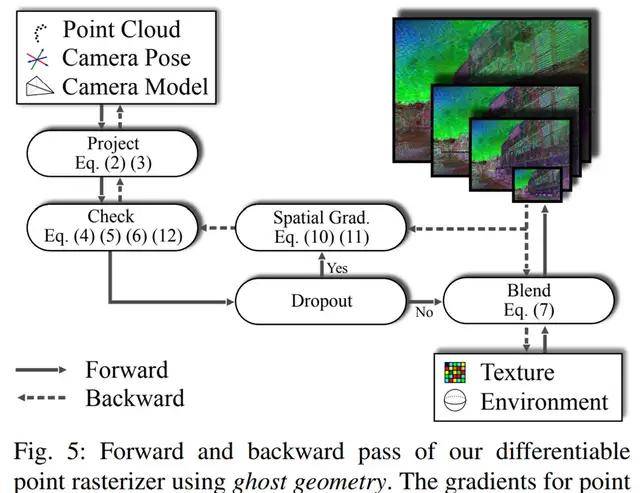
文章图片
通过进一步的性能分析 , 研究者发现即使在小的分辨率层 , 数百个点也可以通过单个像素的模糊深度测试 。 为了将这一数字降低到合理的范围 , 研究者采用了类似于 [72] 的随机点丢弃方法 。 随机丢弃的效果如下图 6 所示 , 其中基于渲染点的数量对每个像素进行上色 。

文章图片
实验展示
在实验部分 , 研究者首先针对前向和后向单像素点栅格化的运行时(runtime)与其他可微渲染系统进行了比较 。 下表 1 展示了自己的方法与 Synsin、Pulsar、使用 GL POINTS 方法的 OpenGL 默认点渲染的 GPU 帧时间的度量结果 , 计时时仅包含栅格化本身 , 不包括神经网络和色调映射器 。 可以看到 , 研究者的方法在所有指标上均优于其他方法 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。