ByteHouse起源于开源的clickhouse项目 , 所以有了House的后缀 。 但它其实是根据字节跳动大规模数据场景 , 进行了非常多的需求改造 , 最终形成的一个云原生的大规模数据分析平台 。
刚刚提到 , 数据驱动是字节跳动的重要技术理念 , 每天我们有数十PB的新增数据 , 有数万多人要从各种维度各种细节 , 对这些数据进行分析 。 这里面就有很多性能问题、实时问题需要解决 , 背后就是靠ByteHouse支持的 。
目前为止 , ByteHouse几乎服务于字节内所有的业务线 , 也是ABI系统、UBA系统、画像系统、A/B测试等分析系统的核心引擎 。 整体规模达到了三万台服务器 , 每天查询有几千万次 。
文章图片
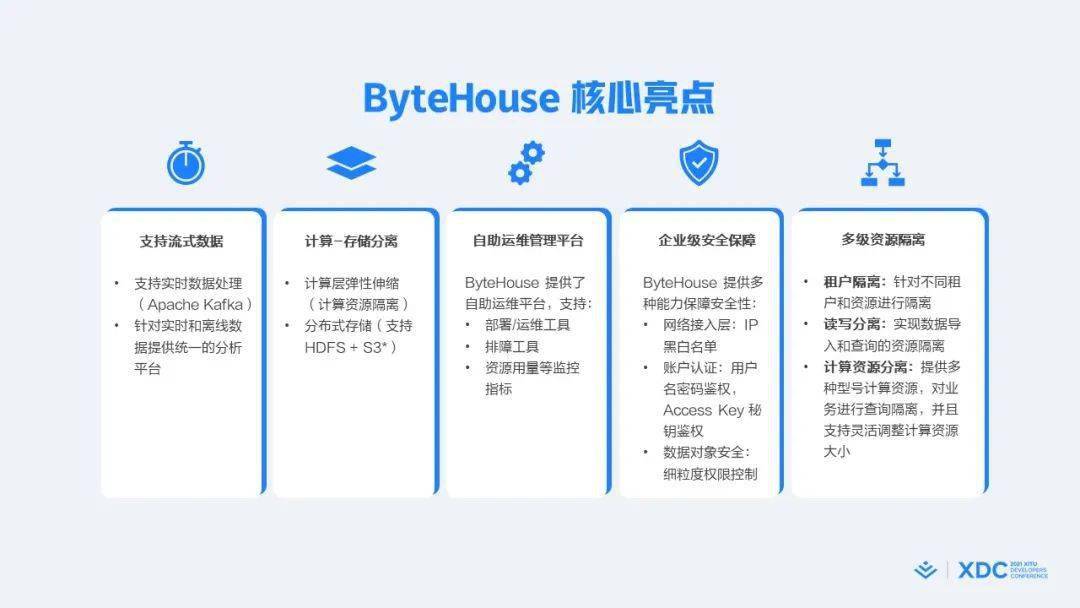
面对刚才说的大规模挑战 , 我们在ByteHouse上主要做了五个层次的深度改造:
第一是支持流式数据 。 对分析而言 , 我们对实时性的要求非常高 , 所以我们通过Kafka支持了对实时数据的处理 。 这样通过ByteHouse可以实现对实时和离线的数据提供统一的分析平台 , 支持批流一体 。
第二是计算和存储的分离 。 因为我们的规模实在太大了 , 如何在数十PB新增数据基础上 , 支持数万人 , 高效快速地做千万次的即时查询 , 是一个很大的挑战 。 通过计算和存储的分离 , 我们能更好地解决性能问题 。 分离之后 , 计算层可以单独地进行弹性的扩缩容 。 在存储一块 , 可以和分布式存储系统进行对接 , 包括HDFS、S3等等 。 这样一方面能解决存储的稳定性问题 , 另一方面也能解决扩容问题 。
在计算和存储的分离之外 , 我们在运维、安全方面做了很多工作 , 以进一步去弥补社区版本功能的缺失 。
最后一个很重要的是我们做了多级的资源隔离 。 因为每天有不同的部门、角色在做各种各样的分析 , 那么权限、时效性的要求都不一样 。 那么通过租户的隔离、读写的分离以及异构的计算资源 , 就能很好地满足不同部门、不同角色在大规模集中式地使用资源分配的问题 。
通过以上这五个大的层次上优化 , 所以我们能够基于ByteHouse去支撑起整个字节跳动数据驱动里的核心步骤 。
应用优化
文章图片
刚才讲了数据中台的一些实践 , 接下来再讲讲怎么去通过数据驱动来做应用和业务的优化 。 这里以增长获客来举例 。
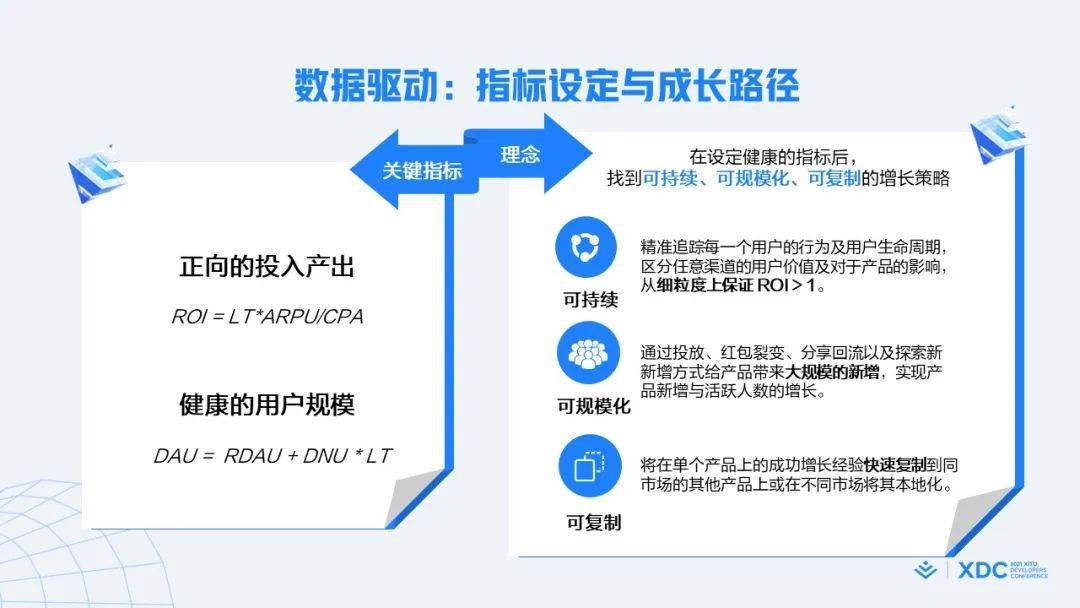
当然不管是增长场景还是其他场景 , 如果要做好数据驱动优化 , 首先最关键的就是设计好指标体系 。 因为指标不对 , 做的再多都是错的 。
那么对于增长而言 , 我们认为最重要的有两个指标——「正向的投入产出」和「健康的用户规模」 。
正向的投入产出 , 简单来说就是ROI>1 。 看起来非常简单 , 但怎么把ROI算对、算准以及精细到每个用户粒度跟进长期的 ROI , 其实是难点和关键 。
当然我们也不能只看短期的ROI , 还要看长期的用户的健康度 , 包括留存 , LT等等 。
设定了这些关键指标之后 , 其实就可以通过指标去找到对应的优化增长策略 。 这个增长策略不仅要满足指标的正向 , 同时也要具备可持续、可规模化、可复制的模式 。 这样就把业务的增长模式转化成了可衡量、可跟踪的数据驱动模式 。
最后用一张图去完整地阐述数据驱动、基于中台和应用优化 , 来构建整体飞轮的案例 。
- 首先基于数据做用户定向 , 定义好目标 , 找到对产品最关键的人群;
- 找到之后 , 去做对应的创意、内容 , 然后让这些最优质最吸引的内容在不同渠道触达到客户 , 形成转换并产生新的数据 。 而且我们有数字化记录的过程 , 能够准确地归因 , 精细化地追踪效果;
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。