量化投资与机器学习微信公众号 , 是业内垂直于量化投资、对冲基金、Fintech、人工智能、大数据等领域的主流自媒体 。 公众号拥有来自公募、私募、券商、期货、银行、保险、高校等行业20W+关注者 , 连续2年被腾讯云+社区评选为“年度最佳作者” 。
前言
Optiver波动率预测大赛于上个月27号截止提交 , 比赛终于告一段落 , 等待着明年1月份的最终比赛结果 。 Kaggle上 , 由财大气粗的对冲基金大佬主办的金融交易类预测大赛 , 总能吸引大量的人气 。 在过去3个月的比赛中 , 也诞生了很多优秀的开源代码 , 各路神仙应用各种模型算法 , 在竞争激烈的榜单你追我赶 。
关于这个比赛 , 网络上陆陆续续也有很多参赛经验的分享 。 但为了充分吸收大神们的精髓 , 公众号还是决定从0到1解读各种不同类型的开源比赛代码 , 方便小伙伴们学习归纳 , 并应用到实际研究中去 。 本系列大概安排内容如下:
- 第一篇:相关概念及数据介绍 , 简单的EDA分析
- 第二篇:初次尝试 , LightGBM模型及特征工程
- 第三篇:首次开源的金牌代码
- 第四篇:独门绝技 , TabNet
- 第五篇:登顶在即 , 图神经网络助力
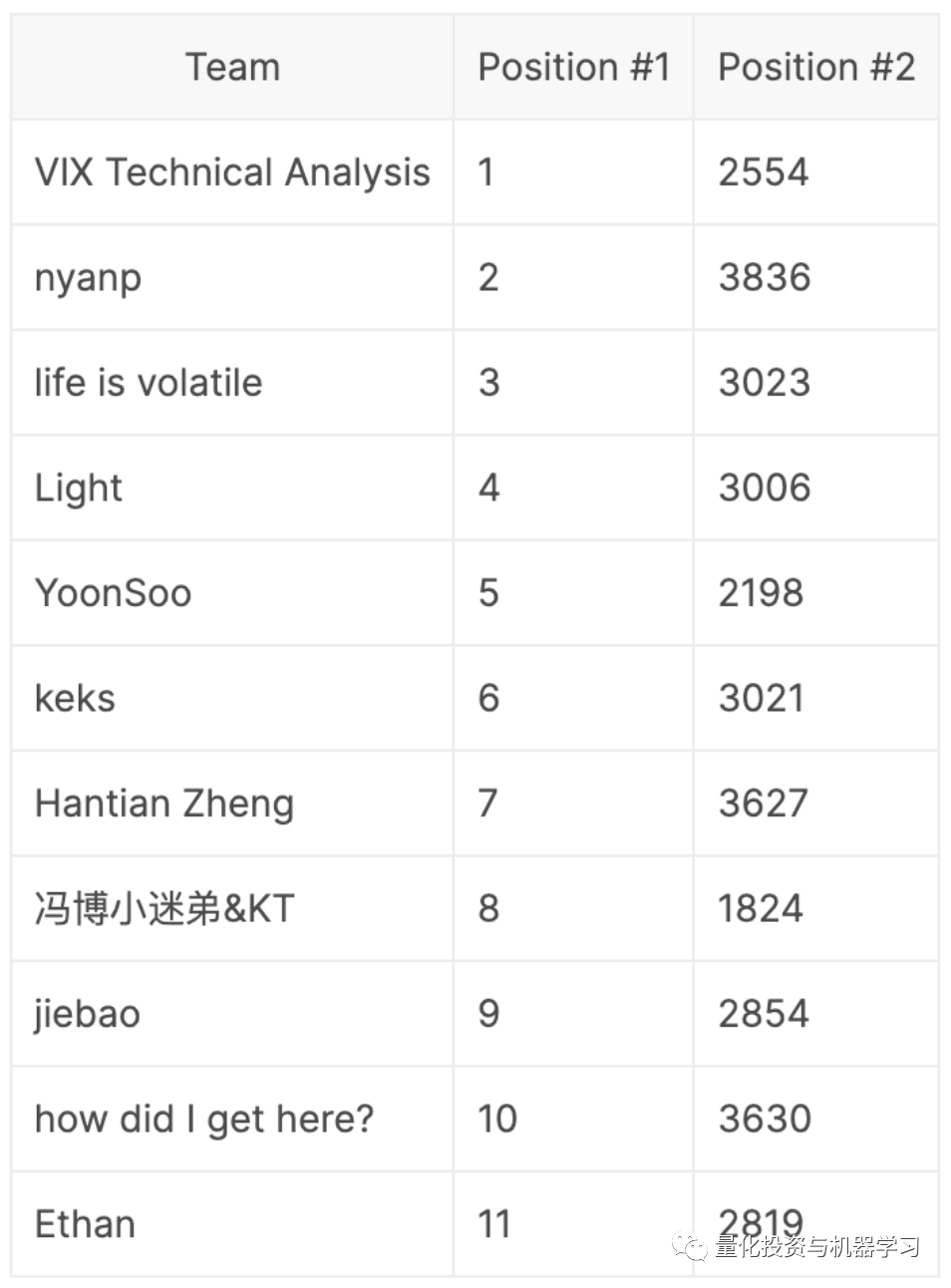
文章图片
我们从模型及特征两个维度来解读本方案:
- 模型:
- 本方案采用了LightGBM及全联接神经网络模型的复合方案 , 最终的预测结果是两个模型的 均值;
- 在神经网络模型中 , 采用KNN++对训练数据进行分层 , 确保每个分层中不同波动水平的股票尽量均衡 。
- 特征:本方案的特征也借鉴了其他方案 , 主要有以下特点:
- 在同一time_id的不同时间窗口进行特征计算;
- 将股票根据预测值进行聚类 , 计算每个聚类的特征;
- 计算每个time_id内的交易的平均时间间隔作为特征 。
https://www.kaggle.com/alexioslyon/lgbm-baseline
我们对其中关键的代码段进行解读 。
特征构建
订单簿的特征主要在book_preprocessor中完成 ,
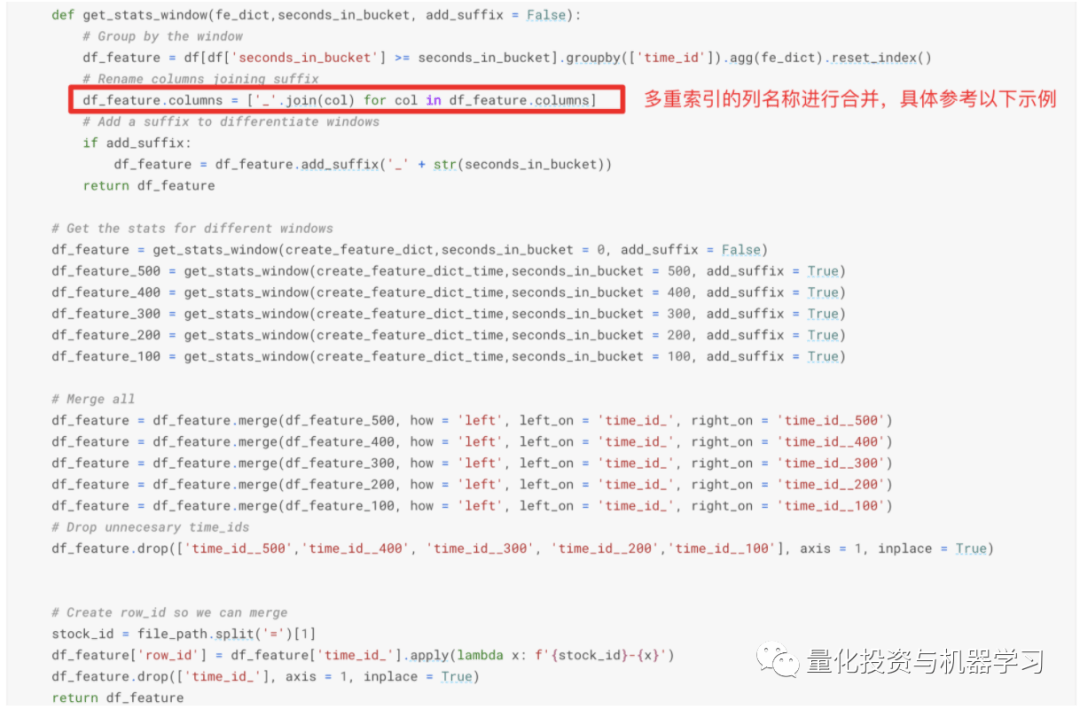
文章图片
多重索引列名合并示例
这样的处理在本方案中出现多次 , 在dataframe进行分组计算(采用agg函数 , 多每列进行多种计算)后 , 返回一个列为多重索引的dataframe , 作者对列名称进行合并作为特征的名称 , 如以下简化的例子 , 可以看出agg后列名默认使用的是函数的名称 , 合并后原先的列名和函数名称合并在一起:

文章图片
交易的特征在trade_preprocessor中完成 , 后book特征类似 , 前半部分也是计算全部时间范围和部分时间范围的特征 , 并进行合并 。 在交易特征中 , 作者还计算了基于成交价变动及成交量乘积的tendency特征 。
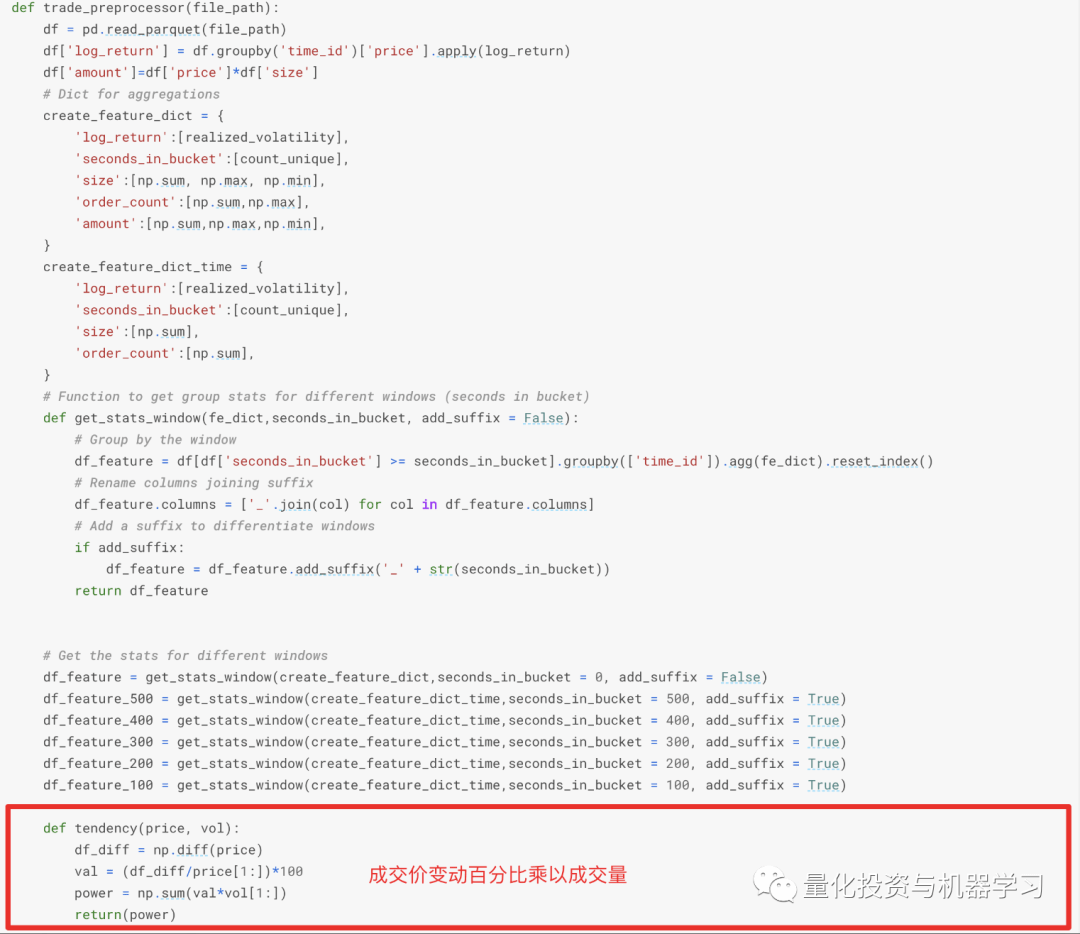
文章图片
book_preprocessor和trade_preprocessor计算的是每个stock_id在每个time_id内特征 , 而以下函数get_time_stock则分别计算了在某个time_id内所有股票综合的特征(比如 , 某个时间所有股票波动的最大值等) , 及某个stock_id在所有时间内的综合特征(比如 , 某个股票在所有时间波动的最小值等) 。
特别声明:本站内容均来自网友提供或互联网,仅供参考,请勿用于商业和其他非法用途。如果侵犯了您的权益请与我们联系,我们将在24小时内删除。